从极越01聊纯视觉和激光雷达融合感知方案,谁是未来?一文读透
关于智驾,你觉得,纯视觉方案和激光雷达多传感器融合感知方案谁才是未来?
为什么今天聊这个话题呢?是因为2024年的年初又发生了一件不大不小的事儿。
1、发生了什么新鲜事儿?
1月14日,极越汽车在“汽车机器人进化日”上发布了整车OTA的最新版本。

很惊人啊,一共更新智能驾驶、通用语言能力、安全性能、娱乐功能等五大类的400项功能点,其中纯视觉智驾方案的升级换代是绝对的焦点。

所以在这次活动上,极越汽车CEO夏一平驾车全程使用点到点的领航辅助驾驶PPA,从上海嘉定开到了极越汽车杭州城西银泰体验店,亲自为极越01的纯视觉智驾方案站台。

不仅如此,极越还与平安保险联合推出了“智驾保”,这是全球首个高阶智能驾驶专属保障产品,也就是说,如果你在用极越01的高阶智驾PPA时候出事故了,所产生的责任费用将由保险公司进行赔付。别的先不说,这一点,值得所有车企学习。
从另外一个角度我们也可以看出,极越对自己的智驾系统是特别有信心的,那么这一次的OTA之中,它在智驾方面有哪些升级呢?
2、极越01的纯视觉智驾升级点在哪儿?
目前行业内智能驾驶解决方案主要分为两种:
一种是激光雷达为基础的多传感器融合感知方案,这是目前包括蔚小理在内的大多数汽车品牌所采用的策略。

另外一种就是特斯拉、极越等厂商坚持的纯视觉方案。

在这次更新之前,极越01在纯视觉方案上已经做出了不小的成绩,它的BEV+Transformer技术方案是国内唯一量产的纯视觉方案。
而这次更新,极越01融入了百度与极越联合开发的OCC占用网络技术,通过BEV+OCC+Transformer多任务统一网格,它可以大幅提升对异形障碍物识别和场景泛化的能力。
简单来说,就是它对周围环境的“理解能力”更强。
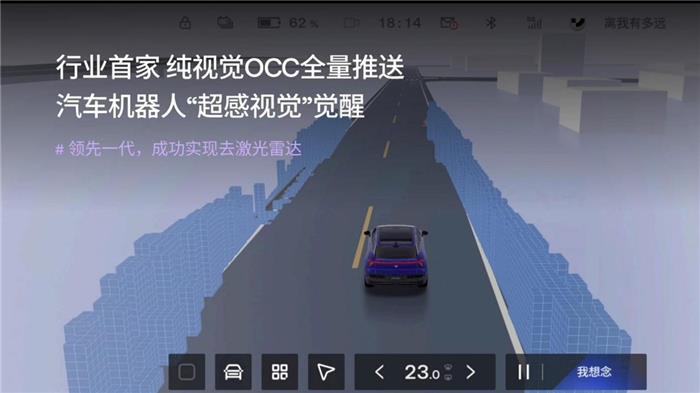
这里我们展开科普一下:
BEV(Bird's-eye-view),中文翻译是鸟瞰图视角,它就像是一个转换器,核心作用是将2D信息作为输入,在加上测距的感知方式之后,最终转换为鸟瞰图视角下的3D环境。
而这个3D环境,便被称作是BEV空间。
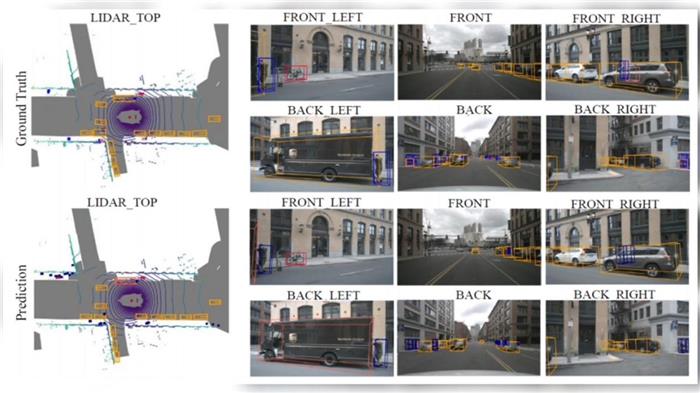
但一个特别难得问题是:如何将不同传感器采集到的信息实现最优的表达。
Transformer我们可以把它理解为一个超级强大的“信息理解机器”。
在智能驾驶系统中,Transformer主要用于处理和理解车辆通过传感器收集到的关键环境信息,比如摄像头拍摄的图片、雷达和激光雷达检测到的数据等,比如一个即将穿越马路的行人,或者一个正在变道的车辆。

然后,它利用这些信息来帮助车辆做出决策,比如何时加速、何时减速,或者何时改变车道等。
在此之前呢,BEV+Transformer的组合便在极越01这款车上量产并且实现了“纯视觉”的高阶智驾,但存在的提升空间在于:如何有效识别异形障碍物,如何拥有更高的场景泛化的能力。
OCC(Occupancy Network)占用网络技术便是为解决这个难题而来的,它是一种基于深度学习的三维环境感知方法。
通过神经网络来预测一个空间位置是否被占据,它主要便是为了提高车辆对周围环境的理解能力,尤其是在处理复杂、多变的道路条件和障碍物识别时。

比如,在实际道路环境中,总会存在一些没有打标和训练过的障碍物,比如临时障碍物、施工区域、路边伸出的树枝、前方货车上掉下来的货物等。
OCC占用网络能够识别这些非打标障碍物,帮助车辆做出及时的反应。
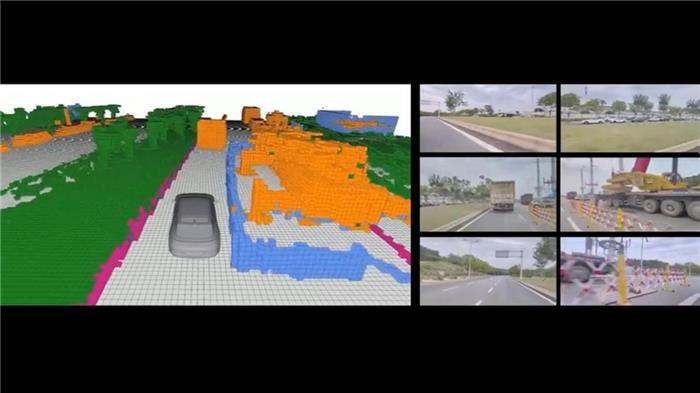
也正是因为这样的能力,所以OCC技术可以去追求去白名单化,换句话说就是可以尽可能多的去识别各种各样的障碍物,包括未知的物体形状和类别。
按照发布会上的信息,极越01目前已经标注了近一百类的物体,而且这个数据还在逐步增加。

咱们可以再举个例子,OCC可以不依赖于特定场景的标注数据,它通过学习大量的空间数据,OCC占用网络可以建立一个通用的空间理解模型,这个模型能够对新的、未见过的场景进行有效的3D重建和障碍物检测。
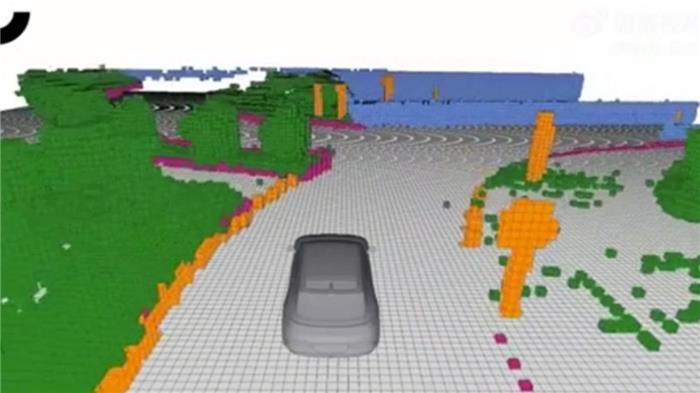
极越将这种全新的智驾方案称为“B.O.T 三向箔”。

它可以不用提前学习而在第一次遇到的时候就能识别这是障碍物,它可以无感老练的去主动避障,它还可以让车辆远离路肩、水马、绿化带等常见障碍从而留出更多的安全距离,定量来讲的话,是偏离原本中心线10cm左右。

打个比方,在没有智驾系统的时候,人类驾驶员避障除了用眼睛“看”之外,主要靠“猜”,但B.O.T三向箔却可以精准地对物体进行感知。
其次,纯视觉方案依赖高精地图,而在实际用车环境下,高精地图和实际路况有可能会不一致,例如那些突发的事故场景、施工场景或者恶劣天气带来的非常规路况等,这个时候B.O.T 三向箔就可以主动进行绕行、减速或者刹停动作。
从技术上来说,纯视觉方案的原理似乎并没有那么复杂,但它对高清摄像头感知能力、计算机视觉算法、大数据积累等都有更高的要求。

极越之所以会坚持纯视觉路线,是因为它有来自百度Apollo技术生态的支持。
到目前为止,百度的Apollo技术生态已经积累了超过6000万公里的高质量Robotaxi原始数据,特别强大,同时还得到了百度170亿参数的AI视觉大模型的加持,可以实现模型的每周快速迭代。

极越01的3D精度可以做到厘米级,对于运动障碍物的识别精度也能达到0.1米/秒的误差范围,这样的表现,已经可以比肩激光雷达多传感器融合感知方案。
3、纯视觉方案VS多传感器融合感知方案有何差异?
这一次的活动,极越汽车CEO夏一平亲自驾车,期间还接到了蔚来汽车CEO李斌的电话。
蔚来与极越采取的其实是不同的智驾技术路线,但他们都很乐于“卷”。

对于这件事,用李斌的原话讲便是:“只有卷才能有进步”。

老板们之间惺惺相惜,那么消费者该如何选择呢?我们首先要弄清楚,纯视觉方案和激光雷达方案,有哪些不同的地方?
普通的纯视觉方案,依赖的是高清摄像头、高精地图进行环境感知和场景识别。
然后,将采集到的图像传输到汽车控制系统中进行分析,从而将2D图像映射到3D空间中。

就像是用人眼睛来捕捉周围环境的信息然后传输给大脑进行决策一样。
简单来说,它更加接近人类的驾驶逻辑,摄像头和算法,相当于人的双眼与大脑。
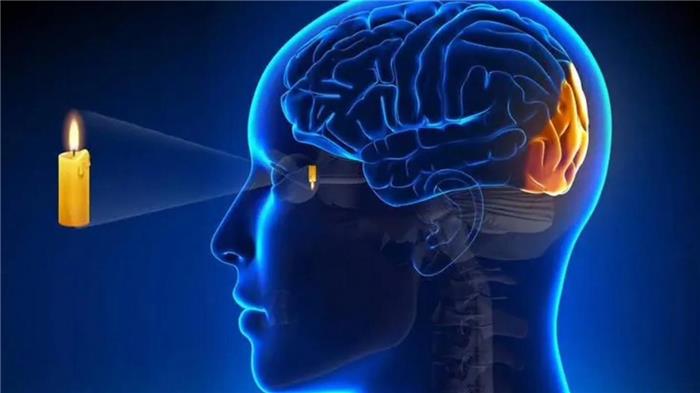
它的优势在于消费者的购车成本更低,因为它不需要那么昂贵的激光雷达感知系统;但它也存在一定的短板,比如感知距离比较有限,比如深度信息检测不足;除此之外,它对计算机算法的要求也比较高,相当于它要求驾驶员的大脑必须非常聪明而且一直高度集中。
激光雷达融合感知方案则是以激光雷达方案为核心,多传感器一起集团作战去收集车辆的周边信息。

其中的重点之一便是引入了激光雷达,可以辅助快速的构建环境的3D模型,举个例子,针对激光雷达扫描到的物体,它可以先计算出远近,相当于眼睛看到的物体直接就带有远近距离的信息,这样可以减少计算机的很多计算工作。

相比较而言,激光雷达它在恶劣天气和苛刻光照条件下的可靠性更高,但目前来看依旧成本高昂,容易给消费者带来一些不必要的成本。一个好消息是:从宏观市场来看,由于激光雷达的销量基数在逐步增大,所以成本有所下降。
极越通过数据大模型、高度智能化的计算机图像算法、海量的数据,基本上解决了普通的纯视觉方案的短板,而走激光雷达路线的厂商,则需要在车上堆积激光雷达雷达和其它感知元器件。
4、纯视觉方案VS多传感器融合感知方案如何选?
从汽车行业的实际应用来看,选择多传感器融合方案的的车企偏多数。
从表面来看,两种技术路线的区别在于传感器的选择存在差异。
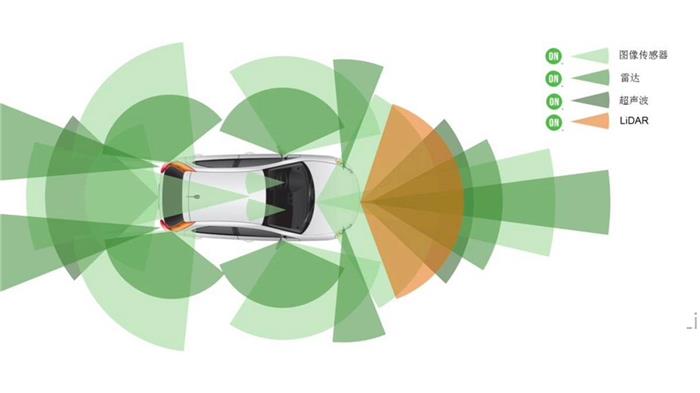
但从本质上来看,主要还是当前传感器技术、传感器成本、数据计算性能等的现状与车规级要求之间还存在较大的差距,两种不同路线的对错与否目前来看依旧难以下定论,但可以肯定的是,恰恰是这样的思辨过程,极大的促进了汽车科技的飞速发展。

从客观角度来说,无论是纯视觉方案还是激光雷达多传感器融合感知方案,只要正式上车,那它们肯定是符合国家相关法律法规的要求,智驾水平也达到了比较高的层次,从我们对极越01和其它带激光雷达的车型的体验来看也是如此。

所以从消费者的角度而言,如果消费者对智驾情有独钟,那么在购车之前一定要进行更多的试驾体验感受之后,然后再做出决定。
结束语:
对新能源汽车市场来说,不同路线的技术争鸣是必不可少的。就像混动与纯电的并存,就像磷酸铁锂与三元锂的并存一样,在未来相当长的一段时间内,纯视觉方案也必将和激光雷达融合感知方案并存。于消费者而言,其实哪种技术路线其实关系不大,能真正用技术的手段去提供更好的用车体验的,才是最好的。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。