特斯拉新一代FSD芯片深度分析,三星是最大赢家
2019年3月,特斯拉正式推出第一代FSD芯片,全球累积出货量大约50-70万片。2023年初,特斯拉新一代自动驾驶硬件系统HW4.0曝光,新一代FSD芯片也随之问世,2023年底的Model S/X可能会搭载HW4.0,Model Y则不大可能。
最新曝光的Model Y的座舱域控制器取消了独立GPU,没错,就是那个AMD的算力达10TFLOPS的独立GPU,存储也从昂贵的GDDR6换成了最廉价的DDR4,显然特斯拉很在意成本,即便是顶配版本,昂贵的HW4.0也不大可能出现在Model Y上。

根据特斯拉爆料大神Greentheonly的信息,我们能够得到一些HW4FSD芯片的简要信息。
首先来看CPU或者说NPU之外的部分,初代FSD使用了12个ARM Cortex-A72内核,新一代FSD使用了基于三星ExynosIP的内核,最初笔者认为仍然是ARM Cortex-A72,因为三星自己研发CPU架构的行为自2019年中期就停止了,而特斯拉的HW4 FSD是2020年以后的设计。但在深入研究三星最后一代Exynos后,作者认为特斯拉完全有可能照搬三星的设计,因为这个设计非常超前,基本上近似于目前ARM Cortex X系列的旗舰X3的设计。

Exynos 990 CPU拓扑
三星自研Exynos最后一代是Exynos 990,严格地说三星自研架构叫猫鼬即Mongoose,Exynos 990的CPU包含两个M5即猫鼬5内核,两个ARM Cortex-A76内核,四个ARM Cortex-A55内核。猫鼬第一代于2016年1月的Exynos 8890搭载,之所以叫猫鼬是因为三星当时的竞争对手高通的自研架构代号是Krait即眼镜蛇科的环蛇属,而猫鼬是眼镜蛇的天敌,以眼镜蛇为主要食物。不过后来高通成了三星的大客户,三星也就很少提猫鼬,第五代猫鼬还有个代号叫Lion。

三星M5内核微架构
三星M5内核最强之处在于其IPC解码器宽度高达6位,而ARM挤牙膏的做法,直到Cortex-X3才将解码器宽度提高到6位。
ARM提升性能最有效的做法:
一是增加IPC解码宽度;
二就是增加缓存Cache容量;
三是提高核心运行频率。

三星M5虽然逼近ARM Cortex-X3,但其解码器宽度很宽,因此执行引擎的宽度多达11位,但M5的流水线不长,宽度过宽,这就注定其无法提高运行频率,而手机是强调单一大核心性能的。对比来看,ARM毕竟是专业做手机CPU核心架构的,在宽度增加情况下,流水线很长,很容易提高运行频率,X3最高频率可以达到4GHz,用在高通骁龙8 Gen2上的X3运行频率高达3.36GHz,而M5很难超过2.5GHz。这也是三星不再搞自研架构的原因之一。另一个原因在于指令集还是ARM的,ARM的架构运行起来自然更好。
但在汽车领域,M5就很合适,汽车领域是强调多核性能的,且汽车封闭性强,如特斯拉这样不打算销售芯片的厂家,完全可以用RISC-V来自定义指令集,因此基本可以确定特斯拉使用了三星的M5架构,最高运行频率是2.35GHz,典型运行频率估计是2GHz。特斯拉可能用12核或16核M5架构,搭配8核或4核Cortex-A72,A72的运行频率比较低,最低1.37GHz,典型运行频率估计是1.5GHz。特斯拉的CPU比12核A78的英伟达Orin估计要强15-30%。
第一代FSD芯片就在三星生产,三星的代工价格远低于台积电,且台积电产能紧张。特斯拉那一点量对台积电来说微不足道,台积电大客户太多,特斯拉如果去台积电流片,会被排在很靠后的位置,因为高通、AMD、联发科、博通、苹果这些台积电大客户都是数以亿片的下单量。台积电的亚利桑那工厂进展缓慢,要到2024年才投产,而三星新增的德州奥斯汀晶圆厂就在特斯拉家门口,2022年下半年投产,特斯拉没理由舍近求远。再加上特斯拉使用三星M5内核,让三星代工更顺理成章。不过,三星奥斯汀晶圆厂的5纳米工艺还不算太成熟,量产估计要到2023年底。HW4 FSD可能还是会用7纳米工艺制造,一来比较成熟,二来比较便宜。
不单是特斯拉采用三星的IP,谷歌手机的自研芯片TENSOR系列也是使用三星IP,当然也在三星代工生产,如第一代谷歌手机自研芯片TENSOR G1(谷歌内部型号就是三星S5P9845)就照搬了三星Exynos 2100的CPU和GPU设计,自己只做了NPU。G2(内部型号就是三星S5P9855)和G3则是照搬了三星的Exynos 2200的CPU设计。未来谷歌旗下的Waymo也会采用三星的IP推出自动驾驶芯片,当然也得在三星代工。
特斯拉HW4 FSD芯片可能也会像三星Exynos990一样有一个MALI G77内核的GPU,算力估计有1GFLOPS。
HW4 FSD芯片的NPU或许是大部分人最关心的,实际CPU重要程度高于NPU,NPU只是辅助角色,CPU才是主角。

第一代FSD的NPU部分拓扑图
第一代FSD的NPU乏善可陈,中规中矩,没什么亮点可言,显然这是针对传统CNN设计的NPU,Transformer时代完全不适用。如果特斯拉真要流畅运行Transformer,那么NPU和存储系统必然要大幅度改进。CNN有98%的运算都是卷积,没有时间序列,数据没有上下文联系,而Transformer模型有不少非卷积运算,包括Relu的矢量和位置的三角函数运算,数据的上下文有联系,意味着有可能有分支跳转,因此NPU必须增加标量运算系统和数据流控制系统。HW4.0采用了美光的GDDR6,带宽达224GB/s,较HW3.0提高了约6.5倍。
在分析或者说推测HW4 FSD的NPU之前,首先看一下特斯拉为自动驾驶数据中心推出的DojoD1芯片,再看一下亚马逊AWS在2022年底推出的,号称专为Transformer推理而生的芯片Inferentia2。

这是未考虑Transformer模型的第一代亚马逊推理芯片Inferentia架构,和特斯拉的FSD比添加了标量引擎,特斯拉的可编程SIMD勉强可算矢量引擎。其余二者相差不大。

针对Transformer设计的第二代Inferentia架构(上图),减少了两个Neuron内核,增加了一个CPU,即Collective compute engine,控制数据流和动态整形,还增加了一个SIMD系统,据亚马逊说这是一个通用型的DSP。此外,还升级了存储系统,从廉价的DDR4升级到了非常昂贵的HBM。
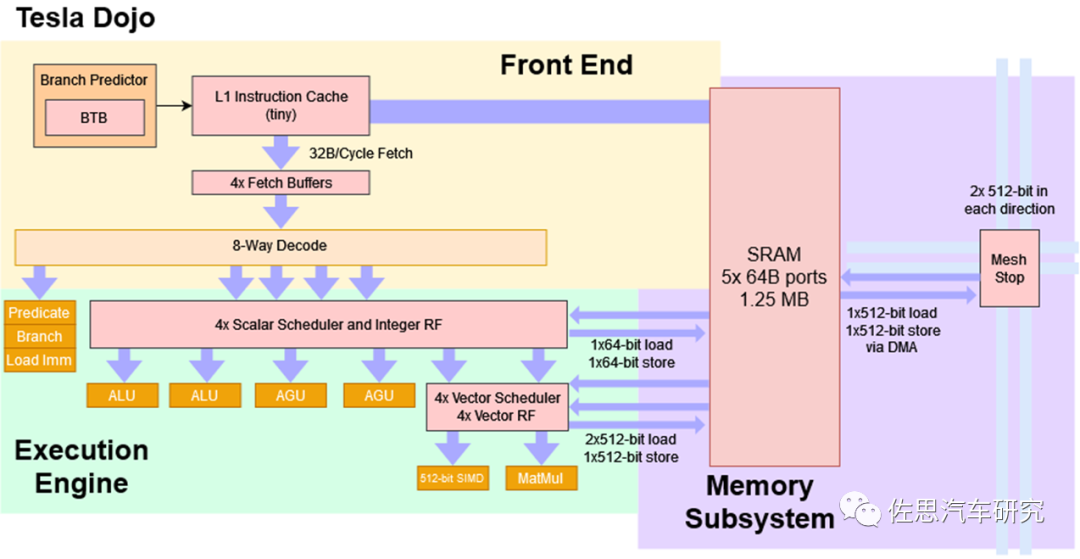
Dojo D1的架构是一个标准的CPU架构,应对标量计算,具备分支预测和跳转机制,拥有8位解码和6路执行引擎。
按照特斯拉爆料大神Greentheonly的说法,HW4 FSD芯片是3个NPU,这个NPU应该类似亚马逊Inferentia里的Neuron核心。一般来说,核心都是对称平行出现,也就是只可能是偶数,不大可能是3个,应该是特斯拉添加了一个CPU,两个NPU还是和初代FSD芯片一样,拥有96*96=9216个MAC阵列,算力就很好计算了,9216个阵列,一个MAC包含两个operation,因此就是9216*2*2.2=40.55TOPS,两个就是81TOPS,两片FSD就是162TOPS的AI算力。
添加一个CPU主要是应对Transformer,特斯拉有这方面的技术积累,Dojo的CPU架构完全可以再用一次,再有就是订制的CPU可以使用自定义的RISC-V指令集而非通常的ARM指令集,这样效率更高,近似于VLIW。
至于算力,这只是个数字游戏,单看芯片的算力毫无意义,因为AI算力的瓶颈在内存,内存的吞吐量或者说带宽远低于AI处理器的运算速度,AI处理器的速度再快,算力再高,90%的时间都是在等内存搬运数据。另一个瓶颈就是CPU,AI处理器是个协处理器,需要HOST主机做任务分配和调度,这个HOST一般就是CPU,CPU要足够强,才能发挥AI处理器的全部潜力。
服务器芯片领域都是用HBM解决内存瓶颈,但汽车领域不行,汽车领域对价格非常敏感,上万美元的芯片不可能出现在量产车上,汽车领域最多也就是GDDR6。CNN时代,外置CPU足以配合好AI处理器,Transformer时代最好内置CPU,这是绝大多数AI芯片不具备的能力。
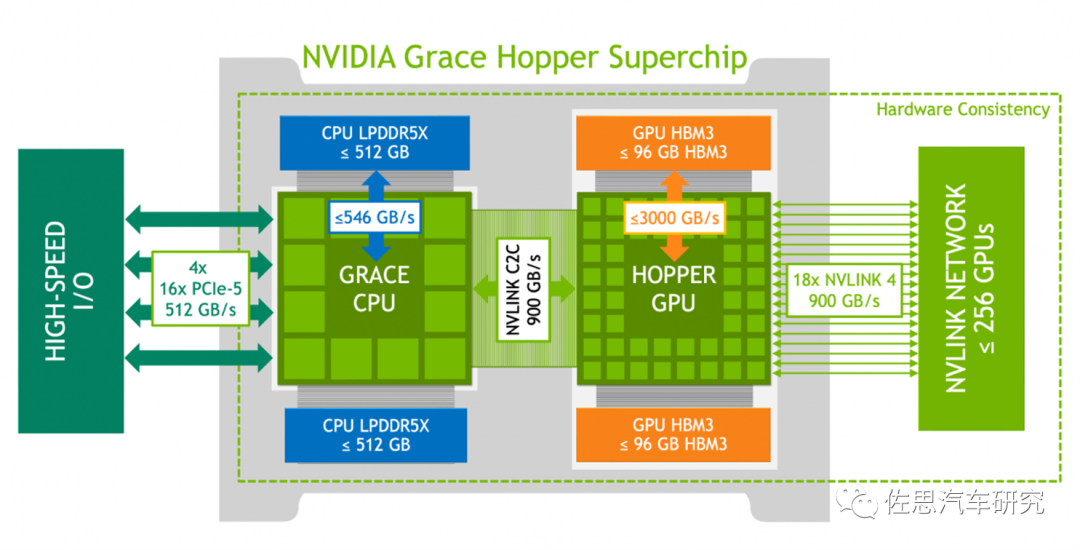
英伟达最新最强的DGX-GH200采用的超级芯片中也是自研了CPU,即64核ARM V2,不过效果还是不如放在一个die里。
AMD的MI300则是CPU+GPU的Chiplet设计,比英伟达要好一些。

AMD MI300 DIESHOT,3个CPU内核,6个GPU内核,8个HBM3
特斯拉的芯片团队基本都来自AMD,包括在 AMD 工作了近 17 年,研究各种 Opteron 处理器以及命运多舛的“K12”Arm 服务器芯片的Emil Talpes,他在2016年4月加入特斯拉。
Autopilot的硬件架构师Debjit Das Sarma则在AMD工作了14年,也是位CPU架构师,2016年2月加入特斯拉。Douglas Williams在AMD工作了12年,2017年10月加入特斯拉,FSD芯片架构师。Ganesh Venkataramanan也在AMD工作了14年,是CPU设计工程主任,在2016年3月加入特斯拉。Rajiv Kurian则比较年轻,2017年1月加入特斯拉,2018年10月离开,跳槽到Waymo,负责Waymo的硬件加速器设计,2020年11月又跳槽回特斯拉,参与Dojo的设计。Bill Chang则在IBM工作了15年,主要负责工程管理,后跳槽到苹果,2020年加入特斯拉。
最终,还是要特斯拉公布详情。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。