基于深度学习的自主驾驶系统社会交互思考
没有人在真空中驾驶汽车;她/他必须与其他道路使用者协商,以实现他们在社交交通场景中的目标(goals)。理性的人类驾驶员可以社会兼容的方式与其他道路使用者交互,在交互密集、安全-紧要的环境中顺利完成他们的驾驶任务。
本文旨在回顾现有的方法和理论,帮助理解和重新思考人类驾驶员之间的交互,从而实现社会自主驾驶。这项综述为了寻求一系列基本问题的答案:
1)什么是道路交通场景中的社会交互?2) 如何衡量和评估社会交互?3) 如何建模和揭示社会交互过程?4) 人类驾驶员如何在社会交互中达成隐性协议并顺利协商?
本文回顾了建模和学习人类驾驶员之间社会交互的各种方法,从优化理论和图模型(graphical models)到社会力理论和行为认知科学。还强调了一些新的方向、关键挑战以及未来研究的开放性问题。
人类可以被训练成具有强大社会交互能力的卓越驾驶员。在现实世界的交通中,理性的人类驾驶员可以通过使用非语言通信(如手势,向另一辆车挥手让路)、指示语(如使用转向信号灯指示意图)等有效地与周围环境协商,在复杂和拥挤的场景中做出与社会兼容的决策,以及运动线索(例如加速/减速/转弯)。
理解复杂交通场景中人类驾驶员之间动态交互的原则和规则,可以 1)利用对他人行为或反应的信念和期望,产生不同的社会驾驶行为;2) 预测具有移动目标场景的未来状态,对于构建可能安全的智能车辆至关重要,其具有行为预测和潜在碰撞检测的能力;3)创建逼真的驾驶模拟器。
然而,这项任务不简单,因为从交通心理学家的角度来看,在驾驶交互过程中存在各种社会因素,包括社会动机、社会感知和社会控制。一般来说,人类驾驶行为由人类驾驶员的社会交互和与场景的物理交互所构成。
由于人类之间的连续闭环反馈,社会交互比物理交互更加复杂,并且存在许多不确定性。社会交互可能只需要简单的决策,直接将人类感知映射到行动,而无需具体的推理和规划(例如,刺激反应、反应性交互、跟车)。社会交互也可能需要复杂的决策,通过预测其他智体的行为并评估所有可能替代方案的影响,迫使人类驾驶员谨慎地决定备选方案中的行动(例如,让路或通过)。
另一方面,人类驾驶员可以通过显式通信相互交流,例如使用手势和闪光灯。然而,在实践中,明确的沟通选项并不总是可用或最有效。在许多情况下,人类驾驶员更喜欢使用隐式而非显式通信来完成交互交通场景中的驾驶任务。
从人与人之间交互到人与自动驾驶汽车(AV)的交互
人与人之间的社会交互。人类是自然的社会传播者;人类驾驶员安全高效地与其他智体进行协商,形成一个交互密集的多智体系统。一般来说,人类驾驶行为受两类规范的支配:法律规范和社会规范。
交通规则构成法律规范,人类社会因素构成社会规范。在真实的交通中,人类驾驶员并不总是严格和刻板地遵守交通法规(例如,在高速公路上保持在限速之下),这是合规的行为(即法律规范)。
相反,人类驾驶员通常会根据隐含的社会规范和规则驾驶,促进道路高效和安全的行为。现有研究还表明,根据随便的行为(即社会规范)行事,可以使其他人的行为变得可识别和可预测,从而减少交互不确定性,促进每个智体的决策。
因此,通过纯粹的法律规范理解和推断其他人的驾驶行为可能是无效的,因为:
交通规则并不总是规定驾驶行为。例如,当驾驶员打算在拥挤的交通中改变车道时,交通法只禁止碰撞,但没有具体说明驾驶员应如何与他人合作或竞争以形成空档。社会规范通常主导这种交互行为。
人工驾驶不严格遵守交通规则。如图说明了现实生活中经常发生的交互场景。一名经验丰富的驾驶员(红色)打算通过十字路口,但其领路车正在等待左转。驾驶员可以越过白色实线并从右侧通过超车,节省行驶时间。虽然这种行为稍微违反了交通规则,但却提高了交通流效率。

因此,让自动驾驶汽车(AV)配备人与人之间交互的集体动力学,可以在人类环境中做出知情和社会兼容的决策。
自动驾驶车辆的社会行为。作为移动智能的智体,智能车辆也需要与人类交互,并将成为复杂社会系统的一部分。在这样一个安全-紧要的系统中,AVs应该无缝地融入到有人类驾驶的道路中,并在社交上与达到人类水平的性能兼容。然而,如图所示,人类驾驶员遵循的规范与自动驾驶车辆之间存在很大差距。

严格遵循法律规范的自动驾驶车辆可能无法应对高度交互的场景,并搞糊涂其他遵循社会规范的人类驾驶员。例如,在停车标志(可被视为法律规范)向人类传递令人困惑的社会线索之前,AV严格且刻板地遵循3秒法则:“为什么车辆不前进?”为了有效沟通,AVs需要模仿或理想地改进,如人类一般驾驶,这要求他们:
理解并适应他人的社交和运动线索。这将AV视为信息接收器,使其在功能上安全高效。例如,如果没有认识到其他驾驶员的攻击性水平,将使AV不安全或过于保守。
提供可识别、信息丰富的社交和动作线索。AVs视为信息发送者,其他人类驾驶员能够感知和理解AVs行为,从而能够进行安全有效的工作。例如,在让行和通过之间犹豫的AV会搞糊涂其他道路使用者,导致事故或交通堵塞。
并不是说AVs为了表现得像人类驾驶员或与社会兼容就要违反交通规则。学习和理解人类驾驶员遵循的社会规范有助于高效安全的交互。
如图说明了两个智体(人类驾驶员和/或AV)之间的动态通信过程,每个智体在信息交换过程中扮演两个角色:信息发送者和接收者。例如,智体A将充当信息发送者,“告诉”智体B其意图。同时,智体B应该感知并理解智体A提供的信息(即感知),然后通过提供可识别的有用信息采取一些行动来响应或适应智体A。

赋予AVs人类社会能力,提高复杂交通场景中的交互性能。例如,用计算认知模型对人类社会偏好(如利他、亲社会、利己和竞争)以及与AV交互时的合作水平进行定量评估。
在量化社会交互之前,我们首先需要弄清楚在特定场景中 “交互何时发生?”或者“是否人类驾驶员之间发生交互?”。一个相关的问题是 “谁参与了交互?”
在实际交通中,道路使用者并不总是有丰富的交互。例如,在人行道上移动的单个行人通常不会影响其他行人,但更丰富社会交互模式的任务除外,例如体育。同样,驾驶员之间丰富的社会交互可能并不总是发生。
人类驾驶员主要单独驾驶,并对物理环境做出反应,但在大多数驾驶任务中,如高速公路的车道保持行为和城市信号交叉路口的受保护左转行为,不会与其他道路使用者直接交互。有三种常用的方法来确定何时发生交互以及谁参与交互。
潜在冲突检查
确定一个驾驶员是否会与另一个驾驶员(直接或间接)交互的一种直接方法是检查他们近期的路径是否冲突。如果路径冲突,则会发生交互,否则不会发生交互。该检查方法即冲突点的定义,“靠近车辆路径合并、分流或交叉区域的位置。”
假设只有潜在冲突的车辆才能相互交互,简化了交互场景,这与日常驾驶过程中的人类直觉一致。可以从多个移动目标的预测未来运动和意图来评估潜在冲突。
驾驶员可以利用道路几何和交通法规的相关信息来检查与他人的潜在冲突。当驾驶员进入交通规则明确的交叉路口时,可以通过检查与其他虚拟参考线的交叉点来识别冲突点。此外,驾驶员还用指示语及其对他人意图和动作的社会推理来识别潜在冲突点。例如,当驾驶员(表示为A)注意到相邻车辆(表示为B)打着闪光灯(即指示灯)或有意接近,目的是切入驾驶员A的前方间隙(即社会推理)时,驾驶员A可以识别驾驶员B的换道意图,接着发生冲突。
感兴趣区域设置
确定交互何时发生的另一种方法是在环境中设置特定的感兴趣区域(RoI)。同时占据RoI的任意一对智体之间存在交互,并且一旦任何一个智体移动到RoI之外,交互就会消失。设置RoI通常是面向应用的,可以根据以下两种方法进行设计:
以场景为中心。确定地图上的RoI,并将该地区的所有人类驾驶员视为交互智体。该方法通常用于预测和分析特定交通区域(如城市交叉口和环岛)中的多智体驾驶行为。在这些情况下,研究人员在地图上确定了涵盖此类场景的RoI,并假设占据RoI的所有驾驶员都会相互影响。
以智体为中心。将RoI与一个感兴趣的智体(即自智体)连接起来。这种方法通常用于研究自智体与其周围智体的交互行为,例如高速公路上的车道变换行为。RoI的形状有多种选择。例如,在研究高速公路上的车道变换交互行为时,通常将矩形区域连接到自车并设置为RoI。
请注意,有些方法还混合二者。例如,在设定高速公路路段的RoI后,进一步计算了智体之间的距离,以确定交互的存在。
上述RoI需要手工制定的规则,相关的评估性能可能对RoI的配置敏感。一般来说,RoI越大,参与的智体越多,可能会高估交互;而RoI小,参与的智体越少,可能会低估交互。为了克服这些缺点,可以根据驾驶任务主动选择交互智体。
面向任务的智体选择
人类将根据具体的驾驶任务,有选择地确定应该更多关注哪些智体以及何时应该关注。受这一事实的启发,研究人员根据问题及其相应交互过程的领域知识,根据经验为特定任务选择交互智体。例如,对于左车道变换任务,研究人员假设自车仅与当前车道上的领头车辆以及左目标车道上的领头和跟随车辆交互。该假设符合人类驾驶经验,并且可以通过只关注任务相关的智体来简化交互问题。然而,它需要具有特定领域知识的手工规则,并且可能无法捕捉个体在如何关注方面的差异。
检查驾驶员对彼此的影响可以确定是否存在人类交互。对于驾驶员之间的交互,一项关键任务是弄清楚 “如何在利用社会因素的同时量化这些交互?” 常用的量化方法,通常可分为两类:基于显式模型的方法和隐式数据驱动的方法。
基于模型的方法
最常用的显式量化交互的方法是构建交互模型,其中一些参数可以从传感器数据中估计,以量化智体之间的社会交互强度。研究人员利用基于不同假设的传感器信息开发了许多交互模型,如图所示四类。

对于作为模型输入的传感器数据,设计师可以明确解释与物理距离相关的度量,从而获得更多研究人员的吸引。在应用中,可以直观地假设交互强度与交通场景中智体相对距离及其变量(例如,相对速度和加速度)相关。例如,相距较近的驾驶员在直觉上会视为彼此具有较大的交互影响。
1 基于理性效用的模型
人类驾驶行为或动作是(接近)最佳结果,可最大化环境的某些效用。在这一点上,研究人员将物理距离相关信息整合到目标/成本函数中,将驾驶员之间的相互作用表述为优化问题,这可以用现成的动态和线性规划算法来解决。通常,成本函数是根据交通管制和驾驶任务的先验域知识手工构建的。例如,研究人员将驾驶员的换道机动视为一个优化问题,即在车辆动力学约束下最小化横向路径跟踪误差(横向控制),同时保持期望速度(纵向控制)。通常,基于效用的模型可以在类似场景中仔细调参达到预期性能,但在未知场景中通用性较低。通常使用的模型是最优群(optimal swarms)、博弈论模型、模仿学习和马尔可夫决策过程(MDP)。
2 概率生成模型
社会交互情境的描述是一种条件,其中单个驾驶员的行为由其组织特征和环境决定,其他驾驶员的行为是环境的一个组成部分,反之亦然。从条件概率角度来看,驾驶员之间的交互影响可以解释为“在感知到周围其他驾驶员的状态后,一个驾驶员可能怎样采取特定的行动?”。该问题可以通过概率条件分布或条件行为预测来表示。
这一概念是贝叶斯网络的基础。此外,可以通过一种意外的交互来量化智体的交互作用。在这种交互作用中,一个智体(表示为智体B),由于另一个智体(表示为智体A)观察到的轨迹,而经历行为的变化。这种想法使得信息论中的大多数现成相似性度量方法(如KL发散)变得容易。
另一方面,交互作用也可以进一步视为(潜在的)概率生成过程或条件概率模型。例如,一种概率图模型捕捉领头车辆的未来状态与动态系统(即领头车辆和后随车辆)历史状态之间的相互作用。然而,它没有考虑并入车辆对前后车辆之间相互作用的影响。一种交互-觉察概率驾驶员模型,捕捉驾驶员的交互偏好,并且考虑到周围驾驶员行为的预测,驾驶员将在当前时间步执行机动。然后,在逆优化框架下,通过加权特征(即导航和风险特征)的组合来制定交互偏好。
3 潜在/风险域
基于人类驾驶行为来自基于风险域的假设,提出潜在/风险域的模型。在人类机器人和多车辆交互,已经广泛研究了势函数对智体之间交互进行建模。物理距离相关度量通过某些可学习可解释的函数(称为潜函数)允许有效地制定交互,这些函数可以嵌入交通规则和驾驶场景上下文的领域知识。
另一方面,势函数相对坐标系(例如,x和y方向)的导数,导致“推”或“拉”车辆的尺度化虚拟力,最小化车辆的局部规划成本,同时与周围的驾驶员进行交互。研究人员还设计了能量函数,根据周围车辆和自车之间的相对距离(通常是两条车辆轨迹的最小值或最近点)捕捉车辆间的交互作用。
然而,基于相对距离的测量并不总是正确地捕捉驾驶员之间的交互。当智体之间存在物理约束时,距离较近的驾驶员可能非常弱或无交互作用,例如高速公路护栏或对面车道的分隔线。
4 认知模型
研究人员用相对距离来表征驾驶员风格,并揭示多智体之间的交互过程,例如,心理学理论和信息累积测度。从行为科学和心理学角度出发,还开发了其他类型的交互模型来模拟人类的驾驶行为。
数据驱动的方法
与上述模型不同,该模型直接利用显式传感器信息来表征人类驾驶员之间的交互,另一种方法使用编码的隐式信息来量化交互。此类隐式信息通常以低维标量或向量的形式出现(在图模型中也称为嵌入),分为三种编码交互的方法。
1 深度神经网络
神经网络表示通过一系列基本层(例如,卷积和递归)将多个传感器信息映射到低维向量特征,例如,在自动编码器和生成对抗网络(GAN)结构中。此外,注意机制还可以集成到网络中,模拟驾驶员之间的交互。
2 具有社会池化的图神经网络
图神经网络(GNN)与常规深度学习(嵌入结构信息作为模型输入的多层神经网络)有一些共同点。信息池化是一种灵活的工具,可根据深度神经网络和大量编程开源的优势,将时域空间和空域空间的智体之间关系抽象为低维可量化嵌入(例如,归一化连续向量)。嵌入可以是时域相关的,捕获演化图(evolving graph)中节点和边缘的时间信息。
因此,它们可以通过聚合操作来表征人类驾驶员之间的交互强度,例如平均聚合、加权聚合和图演化消息(或图消息传递)。此外,池化操作可以独立或同时用不同的神经网络结构将信息嵌入到时域和空域维度上的低维潜状态中。前者通常首先应用时域模型(例如,LSTM)来独立概括每个驾驶员随时间变化的特征,然后用一个社会模型制定概括特征的交互,如convolutional social pooling。
能够模拟车辆交互的编码嵌入可以通过训练GAN和自动编码器获得。尽管一些方法在标准基准测试中显示了有希望的结果,但仍不清楚这些方法应该用什么信息来预测未来状态,以及如何用物理意义解释这些嵌入。量化交互关系的另一种方法,是在序列观测下采用某些图边缘的可学习权重,也称为加权图边缘。这些“编码器”的一个显著特征是,它们很少或根本没有提及学习的编码信息的有效性和可解释性。
3 拓扑模型
编码驾驶员之间交互的另一个想法是使用拓扑编织(topological braids)的形式将其映射为二重代数和几何性质的紧凑表示。这种紧凑的拓扑表示有助于理解任何环境中与任何数量驾驶员的复杂交互行为。
对社会驾驶过程中的影响建模
交通场景中的显式传感器信息和其他驾驶员行为中的隐式社会推断,使人类可以非常好地驾驶,从而进行安全的和社会可接受的操纵。人类的天性是,以社会偏好、社会模仿和社会推理等因素,赋予信息吸收和行为预期能力,这是社会兼容驾驶行为的核心。
对这些社会因素的定量评估需要计算认知科学和技术。
1 驾驶偏好的社会价值取向(SVO,Social Value Orientation)
人类驾驶员在与他人交互时会有各种社会偏好。社会偏好,如其他人类驾驶车辆的利他倾向,可以从计算心理学(如SVO)进行定量评估。SVO模型衡量了一个驾驶员如何将其奖励相对其他智体的奖励的加权,这可以从逆强化学习(IRL)结构下的观测轨迹中学习。然后,SVO模型的在线学习驾驶偏好,集成到两辆或多辆的车辆协同交互的游戏场景中。SVO概念已被广泛研究并应用于社会兼容的自主驾驶中。
2 社交驱动模仿的社会凝聚力
”人类驾驶员像绵羊一样相互跟随‘,共同作用对交通行为的影响非常强烈。因此,人类驾驶车辆的行为具有社会凝聚力——驾驶员会采取与周围驾驶员类似的行动。例如,如果领头车辆减速并采取轻微的“避碰”行为,自车驾驶员通常会采取类似的行动,在社交上假设可能存在虚拟障碍物(例如,圆锥体、动物身体、路面坑)。受人类驾驶员司社会凝聚力的启发,有人开发了一种凝聚增强的奖励函数,确定哪些方面(what aspects)、谁(who)、和何时(when)跟随以保证安全,自动跟随其他车辆。
3 现场-觉察的社会感知
人类可以主动收集并获取有关环境的附加信息,创建相对完整的交通场景,从而提供足够的信息并提高环境意识,从而进行安全高效的机动。例如,通过感知相邻车辆的减速和停车行为,无论驾驶员的视线是否被遮挡,人类驾驶员可以推断出潜在的行人通过道路。人类将其他驾驶员视为传感器的能力已被设计并集成到自动驾驶车辆中,增强驾驶员的现场-觉察。
4 驾驶风格的社会交互风格
人类驾驶员通过评估和平衡未来不同的奖励条款来制定规划并采取行动。根据其内部模型、驾驶任务和动机,人类可能会格外关注不同的奖励条件,通过这些条件,人类与周围环境之间表现出不同的交互风格,如攻击性、保守性、礼貌性、自私性和非理性。因此,交互样式可以表示为在生成轨迹时不同特征的加权结果。例如,研究人员定量衡量这些社会因素诱发的交互风格作为奖励特征。然后,用逆强化学习(IRL)从轨迹中学习此类特征的权重或排名目标函数。
如图是人类驾驶员之间交互建模和学习的方法概述:包括基于理性效用的模型、基于深度神经网络的模型、基于图模型、社会场和社会力以及计算认知模型。

基于理性效用的模型
日常交通中最常见的交互场景是城市环境和高速公路中的跟车、汇入/汇出和换道。研究人员将人类驾驶员视为最优控制器,其具有可访问的目标函数,实现预定义的目标导向(goal-oriented)任务,制定这些场景中的行为。
例如,当在公路闸道上汇合时,将整个过程视为一个显式动态系统,可以将公路上后方车辆对前方车辆的纵向行为(如加速/减速)表示为一个最优控制器。然而,自然交通场景中驾驶员或其他人之间的交互具有物理(例如,运动学和几何)和社会(例如,意图、注意和责任)约束。
通常,基于优化的方法需要特定的目标(例如,车辆之间的期望间隙和车头前进速度)和待优化的目标函数。
本文没有列举所有基于优化的方法,但选择了一些流行的方法,包括基于swarm/flocking的模型、博弈论模型、模仿学习和马尔可夫决策过程(MDP)。
基于swarms/flocks的方法
值得注意的是,在应用中Reynolds规则的大多数具体实例是基于牛顿运动定律传播的动态模型。因此,这需要开发一套反映Reynolds定律的力分量全集,这些力分量(即内聚、分离和对齐)与用于模拟行人交互的社会力理论各部分完全匹配。
Reynolds规则揭示了交互的基本机制,比基于社会力的理论更具普遍性。
尽管flocking启发的规则成功地揭示了动物(如鸟类、鱼类和羊群)之间的群体(swarm)交互机制,但它们只能在自由空间或有静态障碍物的空间(如天空中的鸟类和海洋中的鱼类)中很好地工作。
在交互式交通场景中,这些规则可能由于两种类型约束而失效。
(i)交通环境的限制。flocks运动的空间有微弱的物理限制,甚至没有物理限制,例如在开阔的天空和水下。相反,道路车辆的运动空间具有来自道路轮廓和交通基础设施的许多约束。例如,车辆应在车道内行驶,而不是在道路边界内行驶。
(ii)智体本身的约束。行人和flocks具有高度的运动,例如行人可以在不改变位置的情况下转身。然而,人类驾驶员操作的车辆具有物理运动约束,例如车辆结构导致的最大转弯角和最小转弯半径。
总之,在真实道路交通中,采用flocks启发的方法去捕捉人类驾驶员交互会带来一些挑战:
1.交通规则:交通场景是结构性的,因为交通标志和灯控制交通。人类驾驶员应该遵守许多交通规范和规则,以确保安全和效率,例如保持车辆在车道上。
2.个体异质性:并非每个人类驾驶员都会严格遵守Reynolds规则的每一项;相反,人类驾驶员可能会根据他们的驾驶任务调整规则。例如,人类驾驶员的期望状态可能因其驾驶风格而不同。此外,人类行为可能是随机和时变的。因此,因为道路使用者的个体异质性,很难完美地标定模型匹配所有个体的观测值。
博弈方法
大多数最早的驾驶员交互博弈论模型关注矩阵博弈。目前,大多数人将交互行为转化为迭代优化问题,角色分配将影响模型性能。因此,动态博弈所需的第一个问题是“自车应如何在连续博弈的单个阶段考虑其他驾驶员的影响和角色?”通常,这个问题有三种解决方案,如图所示,将人类驾驶员视为(a)障碍,(b)理性追随者,以及(c)相互依赖的参与者。
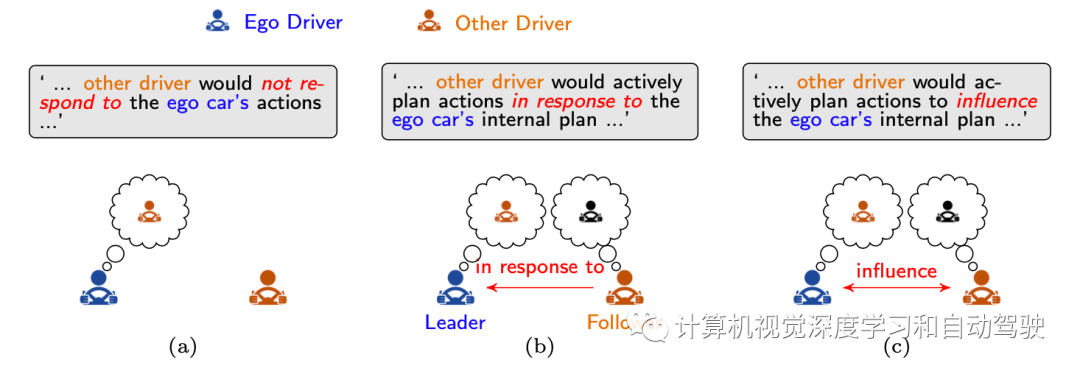
博弈论框架提供了一个可解释的显式解决方案来模拟人类驾驶员之间的动态交互。然而,尽管简化系统动力学和信息结构方面取得了一些进展,但仍难以满足其在连续状态-动作空间中计算易处理的实时约束。由于这些限制,大多数当前的博弈论交互建模方法都存在可扩展性问题,因此仅限于两个车辆的设置和模拟实验,或只是成对地处理多智体场景。
社会偏好是一种方法,将重复博弈的长期影响补偿为单步博弈的奖励。社会价值反映了智体在交互中的经验,可嵌入智体的效用(RL领域称为奖励,或控制理论领域称为成本函数)。
人类是有适应性的,通过与环境安全交互的奖励-强化机制学习驾驶。受此启发,学习与其他驾驶员交互的过程,可以通过博弈论的强化学习来制定。除自车之外的智体可视为环境的一部分,会产生两种交互建模的博弈方案。如图所示:分为异步和同步。

•异步方案。每个驾驶员将其他周围驾驶员视为环境的一部分,如图(a)所示。异步方案下人类驾驶员之间的交互动力学可以用特定的博弈论方案实现,如k-级博弈,其中人类驾驶员的行为以迭代方式预测,如图(c),而不是同时评估。具体来说,为了获得一个k-级智体的策略,所有其他智体的策略都设置为(k-1)-级 ,这有效地成为动态已知环境的一部分。因此,k-级智体的策略估计是对其他(k-1)级智体操作的最佳响应 ,如图(b)所示。
•同步方案。在多驾驶员交互场景中,每个人类驾驶员都试图通过类似试错的过程同时解决顺序决策问题。环境状态的演变和每个人类驾驶员收到的奖励函数,是由所有驾驶员的联合行动决定。因此,人类驾驶员需要考虑环境和其他人类驾驶员并与其交互。为此,同步方案可以通过马尔可夫博弈,也被称为随机博弈,捕获涉及多个人类驾驶员的决策过程。每个智体表示为基于MDP的智体,形成多智体强化学习(MARL)。
MARL算法的不同学习范式可以设计为不同交互任务的特定假设。从理论上讲,学习范式可分为六组,如图所示:(a)共享策略、(b)独立策略和(c)组内共享策略。(d) 一旦中央控制器控制所有驾驶员。(e) 集中训练和分散执行:在训练期间,驾驶员可以随时与任何其他驾驶员交换信息;在执行过程中,驾驶员独立操作。(f) 联网驾驶员进行分散训练:在训练期间,驾驶员可以与网络中的邻居交换信息;在执行过程中,驾驶员独立操作。

单智体的MDP
另一个建模自车如何学习与他人交互的流水线是单智体MDPs方案。单智体MDP假设包含其他智体的环境是静止的,因此可以通过马尔可夫决策过程(MDP)来表示。自车在与环境交互时,动态展开交互轨迹,在考虑其行为影响的情况下,尝试选择最佳规划,最大化相关奖励。
从人类演示学习驾驶
以上讨论的群优化和博弈论方法都是前向设计。通过启发式设置超参来解决优化问题,而不是使用数据进行优化。利用认知领悟分析场景,然后设计一个先验已知的相关成本/目标函数,模拟人类驾驶员之间的交互行为。
驾驶员之间社会交互背后的决策和运动,潜在机制是复杂的,难以编码为简单的手工编程规则。一般来说,演示交互行为要比指定生成相同行为的奖励函数容易得多。这一事实为模拟和学习人类驾驶员的交互提供了另一种选择:通过模仿学习直接从人类演示中学习交互行为。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。