视频是互联网应用中占比最大的数据类型。智慧城市、视频直播、短视频、线上会议、VR、云游戏、视频AI分析等视频相关应用近期获得了迅猛发展,在这些应用场景中对视频的处理效率直接关系到用户体验。如何获得高品质、高性能、低功耗的智能视频处理成为了目前业界关注的热点技术。
视频是以单一格式创建和上传的,但最终以不同的分辨率在不同的终端设备上播放,需要将原视频解码、后处理、再编码,这一过程称为转码。同时,还需要根据不同应用场景的需求对视频进行各种处理,如视频缩放、视频图像增强、视频增加广告/字幕/水印/台标、视频拼接等。随着视频处理需求激增,视频业务成本快速上涨,各大视频业务服务厂商不得不在用户体验和资源成本之间做平衡。
在这种情况下VPU应运而生。VPU全称Video Processing Unit(视频处理单元),是专门面向AI场景优化设计的视频加速器,内置视频编码加速专用功能模块,具有高性能、低功耗、低延时等特性,为视频行业应用带来高效能的加速计算。目前已有多家厂商宣布了VPU的开发计划。Google近期宣布了一款名为Argos的视频芯片(VCU)并将其大规模用于YouTube的视频转码处理任务中。在国内,浪潮发布了AI视频处理加速器M10A。浪潮M10A在8W超低功耗下可以实现16路1080P全高清视频处理加速,支持H.264、H.265、VP9等多种视频格式,兼容PCIE的服务器,为广泛的互联网视频厂商提供计算支撑。

浪潮M10A加速卡▲
M10A系统架构
M10A板卡的系统架构设计兼顾了稳定的数据流程和完善的控制流程。VPU芯片是整张板卡的数据处理核心单元,视频数据的解码、编码、转码、后处理等功能都是在VPU芯片中完成的。为了与服务器BMC控制系统进行连接,M10A板卡上设计了单独的板级BMC管理芯片,完成板卡状态收集和控制,包括温度、功耗、告警、输出复位等。从服务器BMC的控制界面中,可以获取M10A板卡的状态和控制等操作,这是M10A产品相比同类产品的显著优势。
M10A板卡在完成视频转码的过程中,仅需要输入原始视频就可以得到最终重新编码的视频,在整个转码的过程中不需要CPU数据面的参与,从而减少HOST主机CPU的性能消耗,降低转码延时。

M10A加速卡架构图
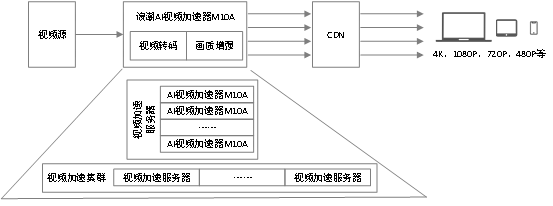
M10A智能视频处理加速器处于视频业务流程中的核心位置。如下图所示,在数据中心,M10A搭载服务器组成高密度、低功耗、低成本的视频处理专用服务器,进而组建数据中心视频处理加速集群。视频输入源完成视频数据采集后,通过网络传输到数据中心视频处理加速集群中,M10A完成视频流的解码、后处理工作,比如对视频YUV原始数据进行缩放和裁剪操作,最后完成高质量的视频编码,通过CDN分发给最终观看者。
M10A除了完成支持传统视频转码操作外,还针对互联网视频的需求特点,研发了多播模式,针对输入视频进行衍生操作,最多可以支持1路视频衍生4路视频的操作,每路输入视频单独调整帧格式、分辨率等属性。
M10A核心技术
|无状态设计
无论是解码核心还是编码核心,浪潮M10A在开发中均采用了无状态设计思想。软件通过操作一系列控制寄存器来管理编解码核心。所有的输入和输出,比如待解码帧、参考帧、运动向量都存储在设备DRAM中。编解码核心不会保存编解码的状态,当编解码核心处理完一路视频流的某一帧后,随时可以切换到其它路视频流进行处理。这样编解码核心的调度管理将变的十分简洁,软件可以派发任务到任意一个空闲的编解码核,随着编解码核心的频率提升,可处理视频路数也将以接近线性的方式提升。这种上下文切换的消耗相较于编解码一帧来说几乎是忽略不计的。可能对于摄像头等某些边缘嵌入式设备来说,在帧间处理时保留状态是一种十分简洁的设计。但是就大型数据中心来说,它们要处理成千上万不同分辨率、不同码率的视频流,无状态设计将是一种更友好、更高性能的选择。
| 主观画质优化
浪潮M10A是目前市面上首款支持窄带高清技术的视频转码加速卡。窄带高清技术的目标是在标准编码内核的基础上,在降低码率的同时保持主观质量不下降。那它是如何做到的呢?现有视频编码是基于香农定理,它的率失真模型都是连续的,但是人眼视觉模型是阶梯性非连续的,因而在这个阶梯上存在一个降码率的空间。
窄带高清一般情况下包含三个模块:
一是基于人眼JND模型,也就是找出人眼最小可察觉误差;
二是基于JND去做感知编码;
三就是通过感知编码来控制标准编码内核输出,主要是去控制CU级别的QP delta。从而使得在主观质量不变的情况下大幅降低码率。
窄带高清技术在CPU编码场景下是非常好控制的,用户可以精确的设置CTU/CU级别的QP delta。但是到了视频转码芯片就遇到了很大困难,绝大多数芯片编解码控制最小单位都是frame或者slice,这也导致市面上大多数芯片在质量精确优化下有瓶颈,无法与CPU编码抗衡,但是浪潮M10A却可以。通过深入分析目前大厂主流视频编码技术,M10A让用户不但可以设置常规意义上ROI(Region of Interest),还做了功能扩展,让用户可以设置CTU/CU级别的ROI。

| 一进多出(多播模式)
针对一进多出的直播场景,浪潮M10A专门开发了前后处理模块,提升了转码效率。
在真实的直播应用场景中,数据采集端一般会采用固定的高清分辨率来获取视频源,但是到了播放端,事情就会变的复杂很多。有的用户使用超大屏手机,有的用户使用老式的小屏机,有的用户使用PC机。各种各样的终端设备,屏幕分辨率千变万化。同时用户所处的网络环境也不尽相同,有的在偏远山区信号很差,有的在高速列车上信号时好时差,有的使用千兆光纤享受4K极致画质。这就带来了新的问题,不同客户需求千差万别,如何才能做到一路视频源,同时满足多种分辨率多种码率要求呢?很快人们便想出了解决之道:在对视频源转码的时候,同时转码成多种分辨率多种码率的视频流,这样既满足了多种多样的客户需求,也满足了实时的要求。
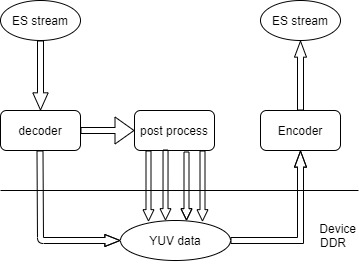
浪潮M10A在解码的同时,后处理模块会根据配置将一路视频分离成多路不同分辨率的流(后处理模块包含scale功能,可以对视频做缩小处理)。并且前后处理模块还采用了on-the-fly模式,解码输出将直接传输给后处理模块(前处理输出也直接传输给编码模块),避免了像一些GPU还需要把中间数据保存到显存中,造成DDR带宽的浪费。
M10A测试数据
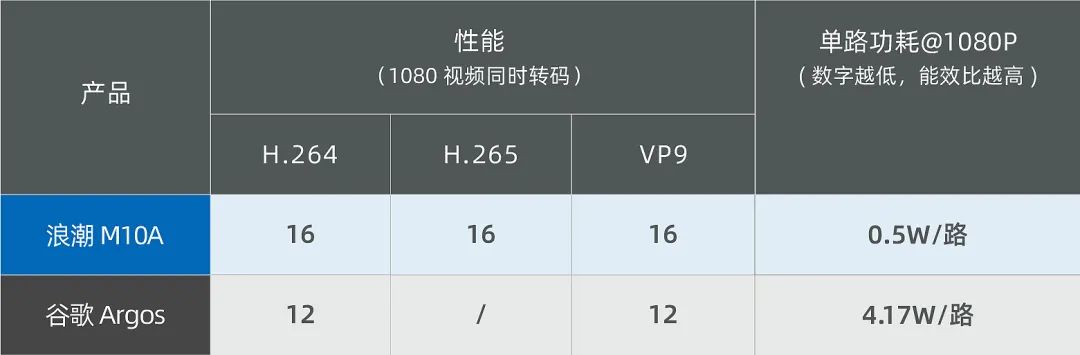
以下是浪潮M10A、谷歌Argos两款VCU在处理1080P30全高清视频实时转码业务时的性能数据。
(Google发表的论文中公布了其VPU的性能数据,链接:
https://dl.acm.org/doi/abs/10.1145/3445814.3446723)
M10A在视频质量方面表现又如何呢?
目前业界一般采用PSNR(峰值信噪比)和SSIM(结构相似性)作为视频客观质量的评判标准,而压缩率则一般用编码后码流的bitrate来表示。将这两个标准结合,就有了我们的综合评判标准:BD-PSNR和BD-SSIM。接下来,我们将用M10A方案与GPU、CPU方案做编码客观质量对比测试。请注意,不同的视频内容,编码时会采用不同的编码工具,因而压缩率也不尽相同。这里我们将使用不同场景的视频来完成测试。
下图分别表示在静态场景、动态场景和多人物场景,使用VPU、CPU、GPU方案的编码客观质量对比,横轴表示码率,纵轴表示PSNR值,相同码率下,PSNR值越大代表视频质量越高。从图中可以看出,在上述三个场景下,使用浪潮VPU编码的视频质量都优于CPU和GPU方案。
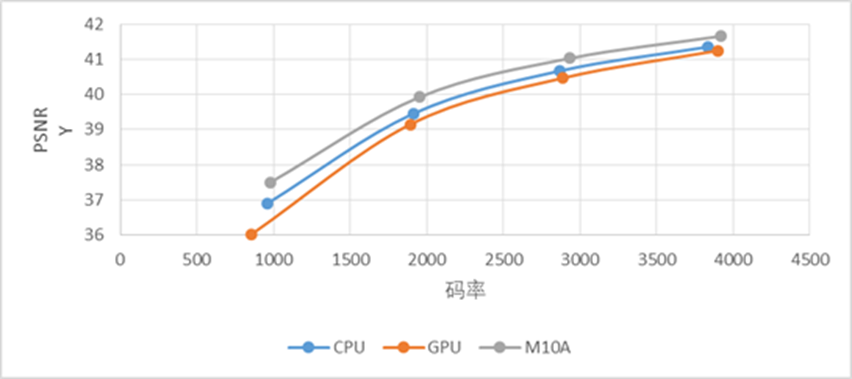
静态场景视频编码质量对比
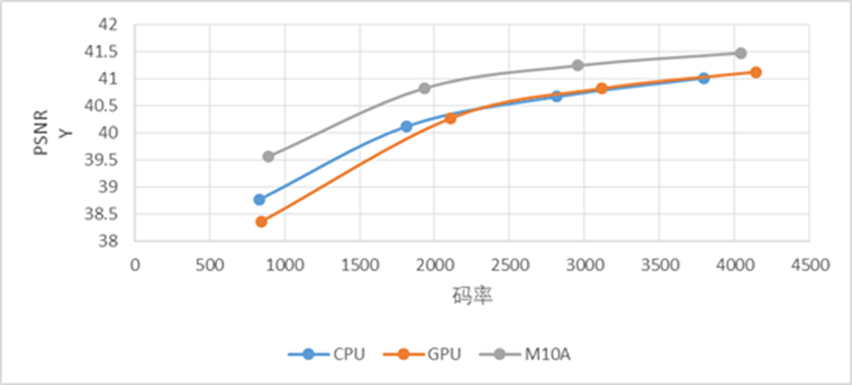
动态场景视频编码质量对比

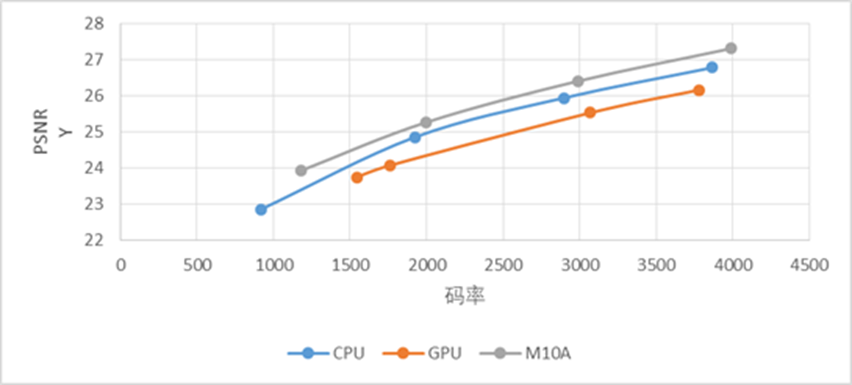
多人物场景视频编码质量对比
M10A应用场景
| 智慧城市
为了追求编码速度,目前主流的摄像头ISP编码部分常常只能编码I帧和P帧,这样就导致视频压缩率不高。一般在边缘云还需要再部署一台转码服务器,对视频作转码再压缩,以节省传输带宽。M10A以其优异的转码性能和优秀的视频压缩率,可以将多路摄像头输入数据作快速二次转码,从而让边缘云获得更高的数据处理密度。
| 直播
在直播场景,同样的视频在不同设备上播放,需要通过转码将视频转换成不同的分辨率。H.265以其更高的压缩率,被越来越多厂商采用。而一般原始设备上采集的视频,还是以H.264居多,这也需要转码来完成。浪潮M10A以其远超CPU转码效率的出色性能,非常适用于直播场景。
| AI推理
视频数据已经成为数据中心最重要的数据类型,如何高效、低成本地分析视频数据已经成为行业痛点,当前行业的主流方案是采用图片资源池和AI算力资源池的系统架构。浪潮M10A支持视频解码和视频后处理功能,拥有丰富的视频缩放和图像裁剪功能,最低可以提供144*144分辨率的图片,满足AI推理计算的需求同时降低图片传输带宽,是图片资源池生产环境的最优选择。
| AI图像增强
对于各大视频平台来说,视频带宽成本的压力巨大,AI图像增强技术已经成为在不增加带宽成本的情况下加强编码画质的最佳选择。浪潮M10A配合AI计算硬件,输出解码和后处理的YUV 原始数据,经过AI计算硬件完成图像增强算法处理后,M10A完成最终的视频编码工作。浪潮M10A拥有丰富的编码参数,提供CPU x265 veryslow级别的编码效果,是AI图像增强方案中最优的视频编码器。
| 云游戏
云游戏能复用设备,可以降低玩家的成本,同时云游戏非常追求即时互动,延时一般不能超过50ms。为此,M10A特别提供了低延时模式。在该模式下,编码耗时仅为3毫秒。这为整体数据传输节省了大量时间,能够进一步提高玩家的游戏体验。
| 云桌面
云桌面应用部署方案因其高信息安全管理力度、云端集中部署等优势逐渐成为主流的办公解决方案。云桌面由云主机和瘦客户机组成,云主机根据客户机的操作反馈,实时渲染视频画面,并生成低码率、高清晰度的视频流,客户机解码视频流并显示出来,达到与传统PC一致的操作体验。浪潮M10A最低3ms的编码延时、领先的编码算法,以及高密度的部署方案,能够很好地满足云桌面系统优化视频处理的行业需求。
| 视频会议
视频会议具有简单便利、实时性等优点,已经成为企业内外部沟通的重要手段。为了满足参会人员的沟通需求,视频会议需要提供清晰,流畅的画面体验。浪潮M10A提供超强的H.265编码算法,可以保证相同画质下,降低50%视频码率,并且支持限制最高码率,极大方便视频会议系统的控制。同时,M10A支持帧率控制、分辨率down scale的高级操作,适应视频会议系统多种应用场景。
浪潮M10A VPU加速卡采用了业界领先的无状态设计理念,通过优化编码算法,提供行业最优秀的视频编码效果,为智慧城市、直播、短视频、云游戏、云桌面、视频会议等典型应用场景带来高密度、低延迟、低功耗的全新解决方案,助力视频行业快速发展。