有这样一种半导体IP,它能让SoC芯片体积更小、功耗更低,非常强大,但却鲜有人注目,它就是片上网络(Network on Chip,NoC)。
前几日,北京开源芯片研究院(简称“开芯院”)举行线上发布会,向会员单位正式发布了全球首个开源大规模片上互联网络(NoC)IP——研发代号“温榆河”。
这不仅标志着国内又攻破了一个高度被垄断的领域,更标志着行业格局,即将改变。
历经18个月,成功验证
根据开芯院官方微信显示,自项目成立以来,经过18个月紧张开发,开芯院成功完成支持64核互联的NoC IP开发和验证。
目前,该NoC IP可交付企业进行评估,进一步推动RISC-V生态的发展。
官方称,NoC作为面向数据中心服务器芯片除高性能处理器核之外的核心基础IP,目前全球仅Arm一家供应商,并在一定程度上限制RISC-V处理器核使用。
简单解释,Arm的NoC IP是设计制造高性能处理器的基础IP,如果没有NoC IP,设计制造RISC-V处理器就要额外购买别人的NoC IP,又会被人反过来卡脖子。

官方信息显示,开芯院是由北京市和中科院组织国内一批行业龙头企业和顶尖科研单位于2021年12月6日发起成立,主要发力点在于RISC-V产业生态。

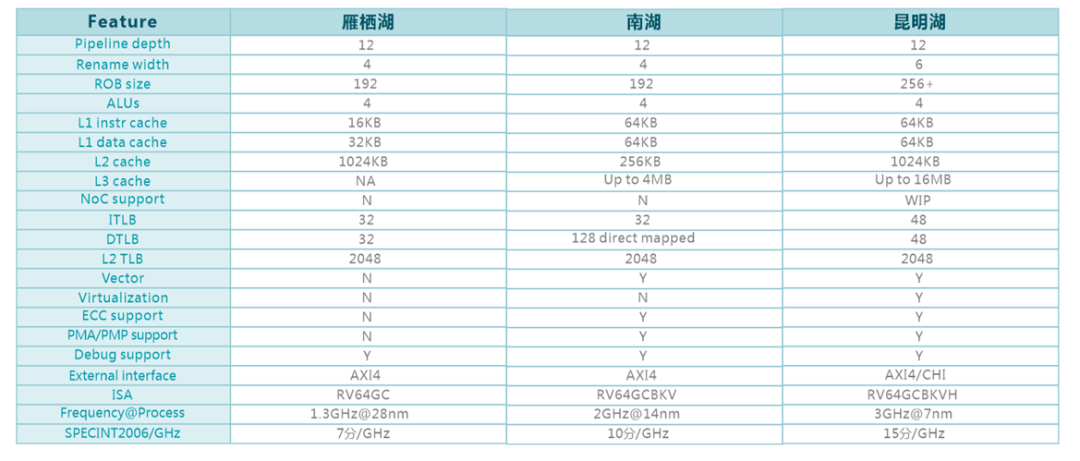
值得注意的是,今年4月,开芯院在2024中关村论坛上发布第三代“香山”开源高性能RISC-V处理器核,其主频达到3GHz@7nm,SPECINT2006评分为15分/GHz,性能水平已进入全球第一梯队,可广泛应用于服务器芯片、AI芯片、GPU、DPU等高端芯片领域,为先进计算产业提供开源共享的共性底座技术。
由此,不难推测,全新NoC IP会与上述IP核配合,实现方式可能类似于Arm CoreLink互连,为全面展开RISC-V芯片和生态做准备。
NoC在芯片中,有什么用
NoC其实是一个相对较新的研究领域,关于这一领域的论文直到20世纪90年代末才开始出现,并由Agarwal(1999年)、Guerrier 和Greiner(2000 年)、Dally 和Towles(2001年)、Benini 和Micheli(2002年)、Jantsch 和Tenhunen(2003 年)等人逐步提出概念,直到最近才开始以成熟的形式出现在产品中。
NoC在论文中有好几种名字,包括NoC(Network-on-Chip)、OCIN(On-Chip Interconnection Networks)和OCN(On-Chip
Network)指代的都是它,中文名“片上网络”。不过,最为常见的缩写,还是NoC。
NoC是系统级芯片(SoC,System-on-Chip)内一种基于网络的通信互联模块,相当于联接CPU内核、存储单元和各种功能模块的高速总线,可实现各功能模块间的高速、高效、低延迟和低功耗的数据通信。
看似很深奥,实际上NoC的概念并不难理解。
打个比方来说,NoC就像叠加在芯片上的空中高速公路网络一样,极大地简化了高速数据移动,并确保数据流可以轻松地定向到芯片任何地方。
现在的SoC芯片其实已经相当于是一个小型计算机,有CPU、GPU、NPU等各种IP核,也有存储器、输入/输出接口等,过去它们的通信主要依靠总线(Bus)和交叉开关(Crossbar)两种互连方式,不过随着SoC里放的模块越来越多,这种方式明显比较复杂,会让芯片变得很大,功耗也更高。
因此,NoC应运而生,说白了就是IP核之间通信互连的一种设计方法,是总线(Bus)和交叉开关(Crossbar)最有吸引力的替代方案:
NoC为片上通信提供了一种可扩展的解决方案,因为它们能够使用较小的面积提供可扩展的带宽,并且随着节点数量的增加,提供近似线性的带宽增幅;
NoC的布线非常高效,在相同链路上复用不同的通信流,进而提供更大的传输带宽;
具有规则拓扑结构的片上网络具有固定长度的局部短互连,因此,可以使用规则的可复用结构进行模块化优化和构建,从而减轻了验证的负担。
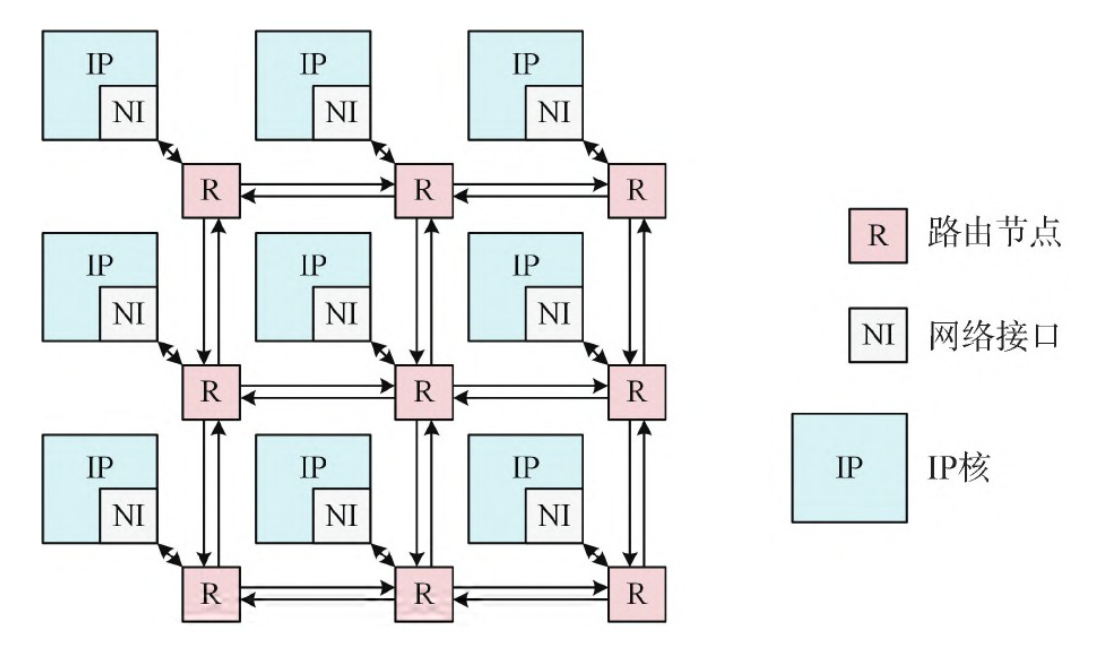
片上网络的典型结构
理论上NoC可以极大减少裸片面积,使得芯片功耗控制得更低,而且可以设计针对片上数据流及其QoS微调优化的扩展功能,甚至是数据保护/访问控制功能。
毋庸置疑的是,NoC在超大规模、高密度集成电路中相对于传统SoC结构有不可替代的优势,是多核系统/异构系统的最佳互连方案,NoC它的优点不仅是单纯的路由选择,还可以设计很多扩展功能。
NoC的出现使得芯片设计从过去的以计算为中心逐渐过渡到以通信为中心。
强如NoC,为什么这么少见
不过,这么强大的技术,为什么现在声量这么小?这几年似乎也只有Achronix强调把NoC做进了FPGA里。
这是因为,一方面,之前SoC并没有这么复杂,用NoC如同“大炮打蚊子”,成本划不来,不如提升制程工艺来的更直接。另一方面,现在主要的商业化的公司只有Arteris(安通思)和Arm。
首先,从SoC发展来看,1990年代初期,SoC可能只包含几十个IP模块,整个设备可能只包含20000~50000个逻辑门和寄存器。彼时芯片间相互通信依靠Bus总线和Crossbar两种方式通信完全能够满足要求。
但如今,SoC可以包含数百个IP模块,每个模块包含数十万甚至数百万个逻辑门和寄存器,传统总线(Bus)和交叉开关(Crossbar)设计的平均通信效率低、单一时钟同步等问题逐渐凸显。
其中最为致命的问题是功耗,即便精心设计,也很难控制住过大的片上网络功耗。比如说,工业界最早的多核原型芯片之一的英特尔80核TeraFLOPS芯片,片上网络占用了30%的芯片功耗;MIT的Raw芯片,片上网络占用了36%的芯片功耗。
时间来到现在,SoC开始越来越复杂,加之摩尔定律趋缓,所以NoC的大好日子才刚刚开始。
其次,从商业界来看,拥有NoC IP的玩家并不多,大多都是拥有处理器IP核的配合使用,比如Arm、Intel。
在2019年以前,Arteris、NetSpeed、Sonics是第三方NoC IP供应商三大巨头,商业化产品分别是FlexNoC、Gemini NoCs、SonicsGN。
2018年,NetSpeed被英特尔收购;2019年,Sonics被Meta(原Facebook)纳入旗下。2020年,Arteris作为大股东,在中国合资设立传智驿芯(Transchip),逐渐铺开中国业务。
至此,虽然市面还有SignatureIP、Truechip等玩家,但方案比较全、公司比较大的只有Arteris唯一一家了。而主流商业方案则包含两个:
Arm的CoreLink互连可生成面向Arm Cortex和Mail内核定制的针对缓存一致性CMP和移动SoC的总线和mesh网络;
Arteris提供的FlexNoC是专有的NoC生成工具,用于连接实现AMBA ACE、ACE-Lite、AXI、AHB、AHB-Lite、APB、OCP和PIF协议的任意IP核组合。
未来多核处理器规模会越来越大,同时异构计算、多核的数量及复杂度都会增加,NoC会是SoC芯片提升能耗比的关键。
开源的NoC,能带来什么
国内的突破远比我们想象中要难,NoC是一个很深的领域。
与传统离散IP不同,做一个高性能的NoC难度非常高,它需要具备灵活性,能够应对多核/异构SoC的要求,又要有稳健的路由算法,保证互联网络不存在死锁的情况,还有很好的通信效率,同时还要有配套的EDA工具,能够快速配置网络参数和拓扑结构,以及自动部署上众多的信号连线。
NoC的门道也远比我们想象中要多。一方面,NoC 技术领域包括体系结构、纳米设计技术、EDA实现理论与工具等几个主要方面,另一方面,NoC设计基础元件库会对系统性能产生重大影响,NoC工具和框架的科学研究非常丰富,但又多是分散的。所以,光有一个NoC IP是远远不够的,换句话说,就是想要使用这项技术门槛很高。
更重要的是,想要更好地提供NoC IP,还要提供一个子系统。NoC IP实现本身需要反复的迭代,从rtl到后端时序的收敛,整个流程上的时间相对固定,如果迭代次数大幅减少的话,那么迭代时长就会降低,这将非常有利于降低成本。也就是说,不能只有离散的IP,而是能够提供一个可以复用性更高的多个IP。
从目前来看,开芯院已经手握多个IP,未来也会不断建设IP,这或许会是国产RISC-V发展的关键。
更重要的是,这个NoC IP还是开源的,相比国外的闭源IP,未来一定能拥有更多灵活性,同时会为RISC-V SoC进一步扩张带来更多惊喜。