“随着模型能力的迭代,以及模型从语言模型逐渐变成一个加上生成、多模态理解的能力,相信在今年年底、明年可能会期待有质变的产生,从务实的角度来看,大模型目前阶段只是一个初步的阶段。”
一辆搭载着FSD V12.3.1 Beta的特斯拉穿梭在旧金山市闹区的傍晚,依靠纯视觉端到端的方案完成了从车位驶出到目的地停靠路边的丝滑操作。

马斯克几乎会以每两周的节奏对FSD进行一次“大改”,直到这次FSD V12.3.1 Beta的更新。
3月25日,马斯克向全体特斯拉员工发了一封邮件,要求必须为北美地区提车的客户演示并安装激活FSD V12.3.1 Beta,并在交车前让客户进行短暂的试驾。希望让人们意识到FSD确实有效。
紧接着,马斯克又随即公布特斯拉基于纯视觉方案的端到端自动驾驶泊车功能将在这几日推送,在Twitter上对FSD不惜溢美之词的进行宣扬:开特斯拉用FSD,几乎哪儿都能去。
新版本发布后,海外媒体平台充斥着该版本的测试视频,不少网友对FSD V12.3.1在北美城市道路中的驾驶能力表达了赞叹:Taht's so cool!
作为引领自动驾驶风向标的特斯拉,已经将端到端自动驾驶的热流从北美流入了国内,又从舆论场的角逐带到了今年3月15日-17日召开的电动汽车百人会的产业演讲中来(以下简称:百人会)。
端到端的风暴,在中国正式打响了“第一枪“。
01.
纯视觉在端到端中的“AB”面
随着高速NOA走向城市NOA,自动驾驶系统的复杂程度在大幅提升,数百万行的C++代码对人工编写规则方式带来巨大的成本。
这时,完全基于人工智能和神经网络的感知模块不会存在因为手动编写规则引发效率低下的困惑,所以现如今的行业风向走到基于大模型的端到端自动驾驶。
多家企业在今年百人会论坛中亮相了行业成果的殊荣,各家对于感知的技术路线看法也各有千秋。
去年,商汤的端到端自动驾驶大模型UniAD入选了2023年CVPR最佳优秀论文。
绝影是商汤智能汽车的板块,商汤绝影智能汽车事业群总裁王晓刚在百人会上表示:“端到端的自动驾驶UniAD,是今年我们自动驾驶最大的突破,从高速到城区的领航,在这里可以看到场景日益复杂,需要大量的工程师每天去解决层出不穷的各种case。端到端自动驾驶是数据驱动,能够为我们高效地解决城区的领航,提供更加高效实践的路径。”
与传统的的单模态模型相比,多模态大模型的优点在于它可以从多个数据源中获得更丰富的信息,从而提高模型的性能和鲁棒性。
王晓刚还提到,商汤进一步提出了多模态大模型自动驾驶方案,这种方案的输入,除了各种感知传感器,系统的信息以外,还允许人机交互,通过自然语言作为输入。当自动驾驶时觉得旁边大车有压迫感,如果想要离它远一点,或者想超车,都是可以通过语言模型进行交互。
另外,输出的时候不但可以输出感知,还可以输出规控,还可以对自动驾驶做出的决策有解释性。
毫末智行CEO顾维灏也发表了对多模态大模型的看法,基于毫末的的DriveGPT,顾维灏表示,DriveGPT最核心的能力是基于持续的多模态的视觉识别大模型。
“我们把它用Token化的表达方式进行训练,再进行三维化,这是我们做大模型很重要的技术基础。”
DriveGPT是毫末智行研发的垂直领域大模型,在视觉大模型基础上,毫末又构建了多模态大模型,用以实现感知万物识别的能力。
顾维灏表示:“多模态放到视觉大模型里面,就会让视觉三维的渲染、标注、识别,能够提前自动化地理解这个照片里面,或者是说前融合后的数据里面究竟这个桌子和讲台是怎么样来分割的,所以加入了多模态大模型。在认知模型里面,我们又加入了大语言的模型。大语言模型它不仅仅是自然的交互,它还有很多知识的理解。”
百度和火山更强调座舱大模型,共识是:认为座舱大模型天生是多模态的场景。
百度的语音和大模型的一体化方案已经在极越车上落地,百度智能云汽车行业解决方案总经理肖猛认为,2024年是座舱大模型的元年。

同时,极越还是目前国内唯一采用纯视觉自动驾驶方案落地的车企,基于百度Apollo纯视觉高阶智驾能力和安全体系赋能,极越完成OCC(Occupancy Network,占用网络)升级,已形成“B.O.T”(BEV+OCC+Transformer)完整技术体系。
与传统的视觉方案相比,OCC的一个显著优势在于它能够处理未知或不常见的物体,降低了因未识别物体而可能引发的意外情况的风险。OCC还能够以厘米级的精度对障碍物进行三维建模。
3月26日,极越在其AI DAY2024技术大会上,发布了OTA V1.4.0新版软件,升级涉及智能驾驶、智能座舱、智能互联、三电等诸多领域,共计升级200多项功能。
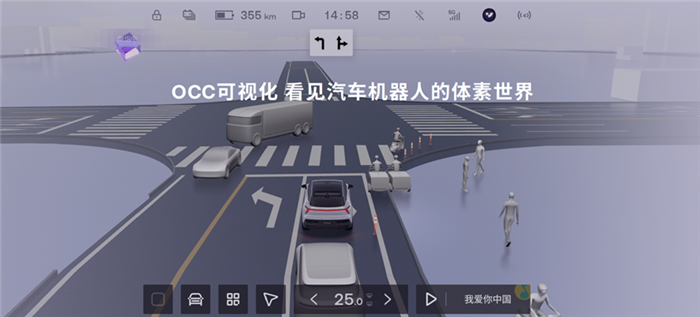
当OCC对应在PPA(点到点领航辅助)功能上,就能使车辆拥有更合理的路线规划,并实现更流畅的变道和绕行。

火山引擎汽车行业总经理杨立伟在谈到大模型在各个行业应用时,发现汽车行业一个非常大的特点。
他表示:“手机目前交互形态还是基于触摸屏幕,通过屏幕来交互的产品形态,所以这也是为什么我们看Siri和手机里面的语音助手做的不好,我相信座舱内有非常便利的空间,目前没有大模型的时候,我们座舱的语音交互的时长和频率已经非常高,座舱是天生多模态的场景,机器想要跟人有互动更好,大模型更像一个人机交互的操作系统和人机交互的智能品。这样的话没有多模态的能力是不行的。”
端到端是自动驾驶研究和开发领域的一个活跃研究方向,这是不争的事实,但端到端自动驾驶技术尚未成熟,跟随特斯拉FSD V12的后来者虽多,但对于任何一家具备研发自动驾驶技术能力的企业来说,光是从普通架构切换到端到端技术的单项成本就颇高。
杨立伟坦诚地表达了这一观点:大模型现在在整个汽车行业的应用还是偏早期阶段。“刚才我们还在讨论,目前是量的提升,没有到质变,随着模型能力的迭代,以及模型从语言模型逐渐变成一个加上生成、加上多模态理解的能力,我相信在今年年底、明年可能会期待有质变的产生,从务实的角度来看,大模型目前阶段只是一个初步的阶段。”
感知固然重要,它提供了必要的信息输入,是司机的“眼睛与耳朵”,与它同样重要的,还有被业界及科研机构不断研究的认知,涉及到规划、决策和应对复杂或紧急情况的能力,相当于司机的“大脑”。
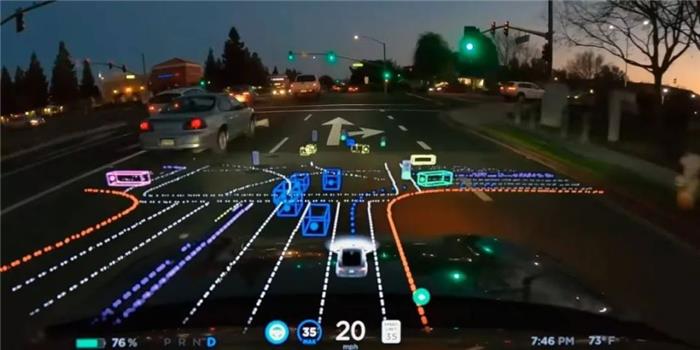
而只有当大模型作为自动驾驶的驾驶员,在认知层面远超于人类时,才能做出超出人类的决策能力,这时,感知、认知会不断迭代,甚至超出人类认知的上限,自动驾驶才会迎来真正所谓的GPT、IPhone时刻。
北京大学计算机学院教授黄铁军在百人会上对当下自动驾驶发展阶段进行了总结:
第一个阶段:只关心感知精度,缺乏认知的阶段,现在大部分车还处于这一阶段,就是L2、L3还很难,因为你只关心感知,不关心认知,这是肯定有问题的。
第二个阶段:特斯拉的FSD,但是他也不是真正的大模型,他只是用了Transformer,还是学人类的驾驶行为。但未来一定是对世界的深度认知,加上很强感知的时代。
不过目前,基于纯视觉方案的端到端自动驾驶,仍被很多主机厂认为是跨越鸿沟的必经之路。

因为不需要大量的人工策略、只需要采集足够多的优质驾驶数据来训练即可,可以通过规模化的方式不断扩展数据来不断提升系统的能力上限。
但这种简单也隐藏了巨大风险。
完全基于视觉的端到端自动驾驶不具备传统自动驾驶系统的“透明性”,传统自动驾驶即模块化方法,端到端自动驾驶是一体化方法,不产生中间结果,直接通过图像输入,直接输出控制信号,但这种技术路线也存在彻底黑盒,解释性差的问题。
同时,端到端模型的训练需要处理大量的数据,包括多模态视觉数据和车辆控制信号等。
02.
当大模型训练的“暴力美学”应用在自动驾驶上
端到端可以类比做GPT-4语言模型,通过收集海量的数据加上训练而实现的。
以特斯拉为例,通过遍布全球的几百万辆量产车,可以采集到足够丰富、足够多样的数据,再从中选出高质量数据,在云端使用数万张GPU、以及自研的DOJO进行训练和验证,使得端到端自动驾驶能够从paper变成product。
OpenAI的秘诀一直以来是屡试不爽的Scaling Law——当数据和算力足够多,足够大,就会产生智能涌现的能力。

直到Scaling Law在这次百人会中被诸多次提及,意味着自动驾驶的成熟需要“暴力美学”来催化,而背后是高昂的算力支出来支撑。
黄铁军在百人会上明确强调了大模型未来超越人类的关键不是靠概率,靠的正是对海量语料,数据背后精确的理解。
顾维灏表示,伴随着人工智能和大模型的发展,自动驾驶迎来了第三个阶段:数据驱动的时代。
或许可以这么理解:大部分代码都不是工程师来写,这些工程师从第二个阶段的“软件驱动的时代”来到了第三个阶段的“数据驱动时代”,解放了过去写软件的双手,所有的工程师都是在准备数据、准备环境、训练模型、检验最后的结果、调整结构、调整参数等工作。
最近一段时间的发展,顾维灏认为或许是自动驾驶的3.0时代。“每一个时代里面的感知、认知和模型是什么样方式来实现的,都完全不一样。”他说。
智能驾驶1.0 时代,是以硬件驱动为主;2.0 时代,是以软件驱动为主;3.0 时代,则是数据驱动为主的大模型时代。
“端到端一定是未来很重要的方向,但它不会这么快到来,”顾维灏表示。他认为还需要几年的发展。“把过去的离散的部分逐渐地聚集化、模型化,把感知的模型聚集到一块,把认知的模型聚集到一块,控制的模型聚集到一块,然后再来实践车端模型和云端模型的联动。”
在 3.0 时代中,顾维灏指出端到端是最重要的方向,目前行业的发展趋势是一个从分散到聚集的过程。
在谈到算力需求时,王晓刚认为,过去发展的过程当中,从2012年AlexNet出现,深度学习神经网络大规模的应用,对于算力的需求是上千倍的提升。随着ChatGPT、GPT-4,甚至更大规模的大模型,我们有上亿倍算力需求的提升。
如何分配技术和下一代技术算力的精力、资源也是一针见血的问题。
百度智能驾驶事业群组首席研发架构师王亮在百人会活动上接受媒体采访时透露:“我们选择纯视觉路线,放弃了激光雷达把它拿掉也是资源的原因。我们希望把所有算力、数据、处理资源、人才、模型参数规模都给到纯视觉,看准了就把资源all in上去,同时也会保留一批像滚筒式的迭代。”
王亮很明确的一点是,初速度决定了产品原型的研发速度,这点上激光雷达占优,能让感知算法实现的难度大幅降低。
而视觉的初速度慢得多,从二维像素恢复三维信息是计算机视觉领的难题,不过一但技术进入轨道,图像里天然蕴含的信息量优势会在其在迭代加速度上更迅猛。
特斯拉 CEO 埃隆·马斯克(Elon Musk)去年在财报会上谈到了数据对自动驾驶模型的重要性:“用 100 万个视频 case 训练,勉强够用;200 万个,稍好一些;300 万个,就会感到 Wow;到了 1000 万个,就变得难以置信了。”
而只有当算法不断被创新满足,足够高算力的智能驾驶芯片才会诞生。
03.
时代呼唤“端到端”到机器人领域
智驾时代变革起点是汽车“驾驶权”由人类向AI转移,但远不止于此。端到端模型的潜力如果继续迭代下去,可能会做出物理世界的AGI。
目前,FSD V 12的算法体系同时应用在了人形机器人及汽车上,加速提升识别算法的泛化能力。
如果说各家公司将战略目标放浅至5年来看,可能是推动端到端模型上量产车积累算法数据,但如果拉长,则是希望找到一条通过具体的实体与现实世界直接接触和互动——即具身智能(Embodied AI),它不再仅仅是软件和算法的集合。
如果你有参加2024年的GTC,会发现黄仁勋在GTC上的主要叙事也是围绕具身智能,而不是LLM。
阿里云智能集团副总裁李强在百人会上的演讲中,非常笃定的表达“具身智能”已成为大模型公司的下一重点共识,同时李强还提出了“具车智能”的概念。

而一个能承载更多想象的具车智能,最关键甚至起到决定性作用的技术底座一定是强大的基础模型。
怎么诞生强大的基础模型?李强总结为几点:全规格和开源。他认为与友商大模型最核心的区别在于开源。从算力角度来看,李强更希望未来能够为所有的模型公司,包括未来更多的开源模型一起提供一个异构的基础设施。
而在具身智能的世界里,端到端自动驾驶又被视为一个子集,专注于智能体如何通过感知来指导行动,在自动驾驶的背景下,这意味着车辆需要理解周围环境并据此做出驾驶决策。
这种尤其强调动态交互和深度学习的具身智能,往往比端到端自动驾驶系统更强调数据质量性和泛化性能力。不过,“暴力美学”是否可以同样应用在机器人上,目前还没有一家实现的公司。
接下来,让我们一起等待机器人领域的Scaling Law时刻吧。









