对标特斯拉,大模型成为自动驾驶又一「强心针」?
8 月 3 日,马斯克在推特表示,特斯拉正在开发 FSD 的「最后一块拼图」——「车辆控制」,有望今年年底实现完全自动驾驶。
马斯克对自动驾驶前景充满乐观。
「车辆控制」是特斯拉 FSD AI 拼图上的最后一块拼图。
马斯克这句话表明,特斯拉将更多依赖 AI 来控制车辆,而不是依靠硬编码指令,来加速特斯拉 FSD 的落地过程。「车辆控制」的上车,将使原来 FSD 中 30 万行以上的 C++ 控制代码,减少约 2 个数量级。
完全自动驾驶的时间表,在业内仍然众说纷纭。
小鹏汽车创始人何小鹏表示,高阶的 L4 或者准 L5 可能在 2027 年到 2030 年才会出现。
特斯拉 FSD 基于 Transformer 的 BEV 感知路线,也是大模型技术首次被应用到自动驾驶行业。
在 ChatGPT 大火之前,大模型技术已经上「车」,如今几乎成为智能驾驶必备。
理想汽车创始人李想公开宣称,「大模型的研发和训练是智能电动车企业的必要能力」。
大模型技术支持下的完全自动驾驶未来将至,似乎毫无悬念。但是受限于算力、数据等,需要多久实现尚难以达成共识。
01 摸着特斯拉大模型能否「过河」?
特斯拉的自动驾驶技术正在进入一个新阶段。
马斯克透露,FSD V12 发布时将不再是「测试版(Beta)」。
特斯拉让外界看到了 Transformer 技术的潜力,国内车企陆续跟进这一感知路线。
李想曾表示,理想汽车对自动驾驶的投入是从特斯拉把大概逻辑跑通以后才正式开始的。
自动驾驶企业们效仿特斯拉向 BEV 架构转向,偏重算法、以摄像头与各种传感器作为硬件的路线开始吃香,背后主要驱动力来自从高速 NOA(自动辅助导航驾驶)走向城市 NOA。
与此同时,曾经被视为「香饽饽」的高精地图日渐失宠。
早在 2019 年,马斯克曾公开表示:「过分依赖高精度地图会让自动驾驶系统变得极其脆弱,普及起来更加困难。」
这种方案对芯片算力、传感器硬件、算法的要求更高,车企多年积累技术已经逐步赶上。
同时,在技术推进的角度考量,省去高精地图,利于加速城市 NOA 的普及。
在技术迭代道路上,中国智能车企正在摸着特斯拉探索出的 BEV 大模型之路「过河」。
这条貌似容易的模仿之路的关键问题在于,在中国正兴盛的 NOA 未曾脱离 L2 级辅助驾驶,而特斯拉的 FSD V12,号称将达到 L4/L5。
车企对此并不讳言。
据李想预测,今年年底,大部分头部企业的智能驾驶能够达到 2021 年年底特斯拉的水平;到 2024 年,企业普遍能做到 2022 年年底至 2023 年年初特斯拉在北美的水平。
这意味着,中国技术最领先的车企,和特斯拉的智能水平差距约达 2 年。
回溯获得特斯拉完全自动驾驶能力的过程,攻克 Transformer 技术是关键一步。
2021 年 7 月,特斯拉 FSD Beta 展示了基于 BEV+Transformer 的自动驾驶感知新范式。
基于 Transformer 的 BEV (Bird's Eye View) 的感知方案,这也让特斯拉得以摆脱激光雷达坚定地走上纯视觉路线。
所谓 BEV,指的是用神经网络将图像空间映射到 BEV 空间,通过摄像头 2D 图像拼接转化成 3D 图景,生成鸟瞰图。
这个拥有「上帝视角」的图,可以实现 360 度环视完成感知,并且进行时间、空间的融合进而形成 4D 空间。
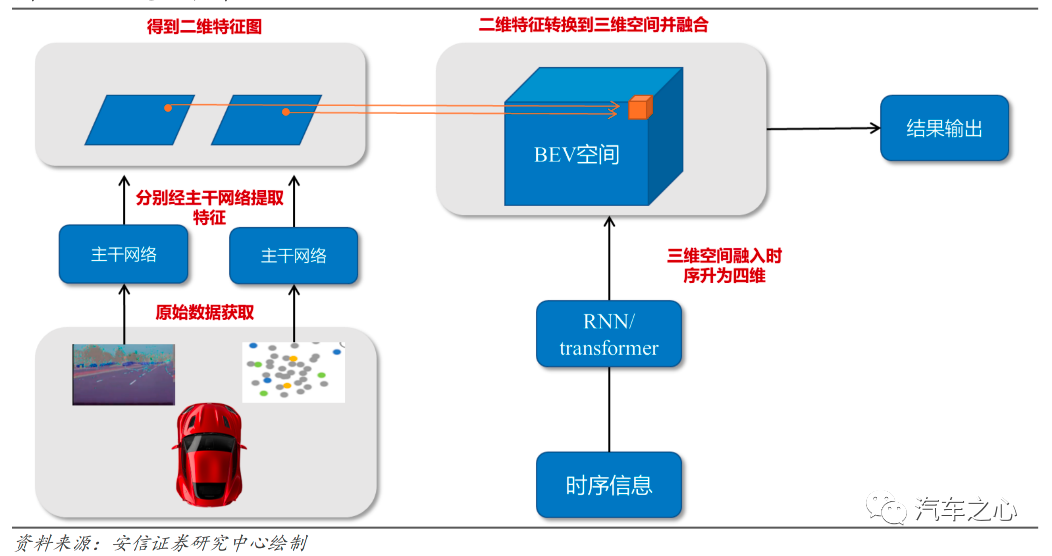
BEV 感知框架 来源:安信证券《AI 大模型在自动驾驶中的应用》
尽管晚了两年,中国车企们正在加速赶上特斯拉。
据不完全统计,目前包括「蔚小理」在内的车企,以及百度 Apollo、华为、大疆、毫末智行、轻舟智航、小马智行、元戎启行、地平线、商汤科技等自动驾驶企业都在使用 BEV 技术。
在尝试 Transformer 的 BEV 效果之后,小鹏汽车开始搭建 XNet。
小鹏 XNet 可以输出 BEV 下的 4D 动态信息(如车辆速度、运动预测等)和 3D 静态信息(如车道线位置等)。
小鹏称,这是国内首个量产的 BEV 感知方案。
理想发布的最新城市 NOA 导航辅助驾驶 AD Max 3.0,将于年底前完成 100 个城市的落地。
这一方案也搭载了三种神经网络大模型算法:静态 BEV 网络算法,动态 BEV 网络算法以及 Occupancy 网络算法。这是多家车企正在追求的目标。
BEV 技术落地最近的进展来自大疆。
7 月 27 日,大疆车载正式命名其高性价比的智能驾驶解决方案为「成行」,「成行平台」实现了行泊一体的 BEV 感知,并采用 OSP(Open Space Planning,开放空间决策规划技术),提升在城市、高速、停车场等环境智能驾驶的通行效率。
此前,百度 Apollo 已将视觉感知升级成了 BEV 感知,UniBEV 车端和路端感知数据在一个坐标系内;
华为的 ADS 1.0 据称已实现基于 Transformer 的 BEV 架构,而 ADS 2.0 进一步升级了 GOD 网络,类似于特斯拉的占用网络算法;
商汤研发出了自动驾驶的环视感知算法 BEVFormer++;
毫末智行发布了业内首个自动驾驶生成式大模型毫末 DriveGPT 雪湖·海若,通过引入驾驶数据建立 RLHF(人类反馈强化学习)技术;
轻舟智航的 OmniNet,实现前融合和 BEV 空间特征融合;
小马智行自研「伸缩网络」多任务大模型 BEV 算法架构,可基于不同算力平台调整网络大小及其对应的资源消耗率,更高的算力可识别更多的静态元素类型和动态障碍物细分类,以及更大的识别范围;
地平线发布了 SuperDrive 感知融合 BEV 技术;
蔚来的 NOP+ Beta 版将升级为正式版,采用 BEV 与占位栅格感知模型,并切换至 NAD 同一技术栈;
看起来千差万别,以上各家的 BEV 技术,实际均是基于现有算力大小、场景、落地速度,以特斯拉 BEV 方案为母本的创新。
但是 BEV 只是长征路上的第一站,特斯拉已拿下另一个技术高峰:占用网络。
2022 年年底,特斯拉将 BEV 升级到了占用网络(occupancy network),系统的感知将从 2D 变为了 3D,不需二度拼接,直接将车辆置于 3D 世界中,10 毫秒内车辆可以收到周围每个 3D 位置的占用概率,以预测周围障碍物分布情况。
这极大提升了车辆应对 Corner case 的可能,提升了泛化能力(即 AI 在识别一个物体后,进而可以识别一类物体的能力)。

BEV 与占用网络效果对比 来源:安信证券《AI 大模型在自动驾驶中的应用》
NOA 场景落地带火了 BEV,「去高精地图+占用网路」模式或将成为车企的下一站。
虽然特斯拉的 FSD 自动驾驶系统功能丰富,但仍然需要驾驶员接管,这意味着 FSD「尚未达到真正的 L3 级别」。
从 L2 级自动驾驶到完全自动驾驶,车企们的大模型之路,依旧征程漫漫。
02 通往大模型技术终局:瞄准、成为、超越「端到端」
今年 5 月,上海人工智能实验室青年科学家李弘扬团队发表的一篇论文,首次提出感知决策一体的自动驾驶通用模型,并于获得「CVPR 2023 最佳论文」。
这是顶级会议 CVPR 在 40 年历史上,首次授予自动驾驶领域「最佳论文奖」。
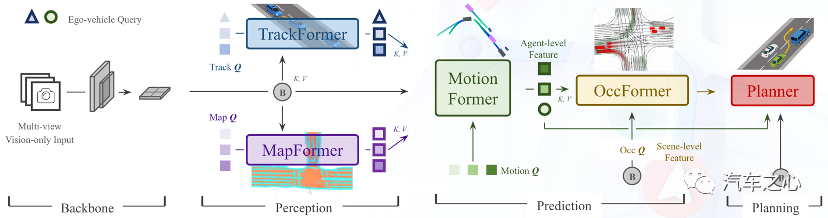
来源:上海人工智能实验室
李弘扬团队提出一套目标导向的自动驾驶算法方案(UniAD, Unified Autonomous Driving),其设计理念是采用端到端架构,把 Planning(规划)作为最终目标,整合所有自动驾驶模块。
李弘扬表示,该方案与 MTL、特斯拉等方案的区别是,后者想把所有任务的性能都做到最好,「而我们的方案只盯着 Planning 的结果」。
除了技术阐释,李弘扬提出了一个尖锐观点:
「我认为现在这个行业没有自动驾驶大模型。我们给 UniAD 工作的定义也是『自动驾驶通用模型』,而不是大模型。」「如果自动驾驶大模型最后是发展成感知大模型,是不完善的,那完全可以在通用视觉里做。」
李弘扬这一观点,让不少人开始反思:
当下正火的这条特斯拉开创的「自动驾驶大模型」道路,距离真正的自动驾驶技术终局,还有多远?
解决低频但又繁杂的长尾场景(Corner Case),是迈向自动驾驶最大的困境。
7 月 27 日,马斯克在推特宣布:已经测试 FSD Beta 的 V12 Alpha 版。此前马斯克透露,相比目前的 V11.4,V12 将真正实现「端到端」。
端到端「End-to-End」,是深度学习(Deep learning)中的概念,指利用一个 AI 模型,只要输入原始数据就可以输出最终结果。
在自动驾驶语境下,「端到端」意味着感知、预测和规划所有环节将被视为一个整体。
借助 Transformer,图像输入至 AI,将直接输出方向盘转角、油门、刹车和速度的输出信号。行业里现有的端到端自动驾驶系统,缺乏一个将全部模块统合的网络框架可,而是只能融合部分模块。
特斯拉若能让模仿人类神经网络的「端到端」真正跑通,那么将无限靠近人类真实的驾驶水平。
模块化的设计让各部分隔离,跨模块信息整合或存在误差,这导致必须有驾驶员在场做监督员——这些均是进化「端到端」技术的背后动力。
值得注意的是,端到端自动驾驶大模型也不意味着完美,或将存在一些难以跃过的弊病。
这可以参考 ChatGPT 不完善版会出现的「胡言乱语」现象。
端到端尽管简化了中间环节,这导致 AI 模型将成为一个黑盒子,其内部工作原理无法被外界所掌控。它不再是由数据规则、先验知识驱动,而是依赖人类驾驶的数据进行模仿。
一旦出现差错,无法找到对应的模块加以调整优化,对于处理长尾场景 Corner Case,是否能如预期?如何保障 100% 的安全率?
这些需要等到 FSD Beta 的 V12 版真正上路才能获知。
即将 FSD Beta 的 V12 版的端到端感知决策一体化模型顺利出炉,大模型在自动驾驶的应用仍然存在局限性——束缚在长尾场景 Corner Case 和更通用的泛化能力之间。
技术迭代从来没有终点。
正如李弘扬所指出的,自动驾驶大模型,不等于感知大模型。
除了基于视觉感知,自动驾驶需要多模态端到端感知模型,提升车辆在决策和规划上的表现。
英伟达创始人兼首席执行官黄仁勋称,「未来的生成式 AI、大模型以及推荐系统式,是现代经济的一个引擎」。
大模型应用的第一站是自动驾驶。一张前景更加广阔的产业蓝图,已经绘在了遥远的珠穆朗玛峰之上。
兄弟登山,车企们正在「各自努力」。
03 智能汽车的未来是人工智能?自动驾驶的「星辰大海」还有多远
何小鹏曾指出,过去一直不认为高端的 L4 或 L5 能真正到来。因为告诉车一个简单的规则后,它在碰到各种特殊情况下,做不到像一个真正的司机一样。「但 GPT 再往前走三年,跟车的融合会完全不一样。有了 GPT 之后,高阶的 L4 或者准 L5 可能在 2027 年到 2030 年之间大家就会看到。」
在自动驾驶大模型落地的过程中,除了重感知能力外,计算能力的演进,以及海量数据的训练均缺一不可。
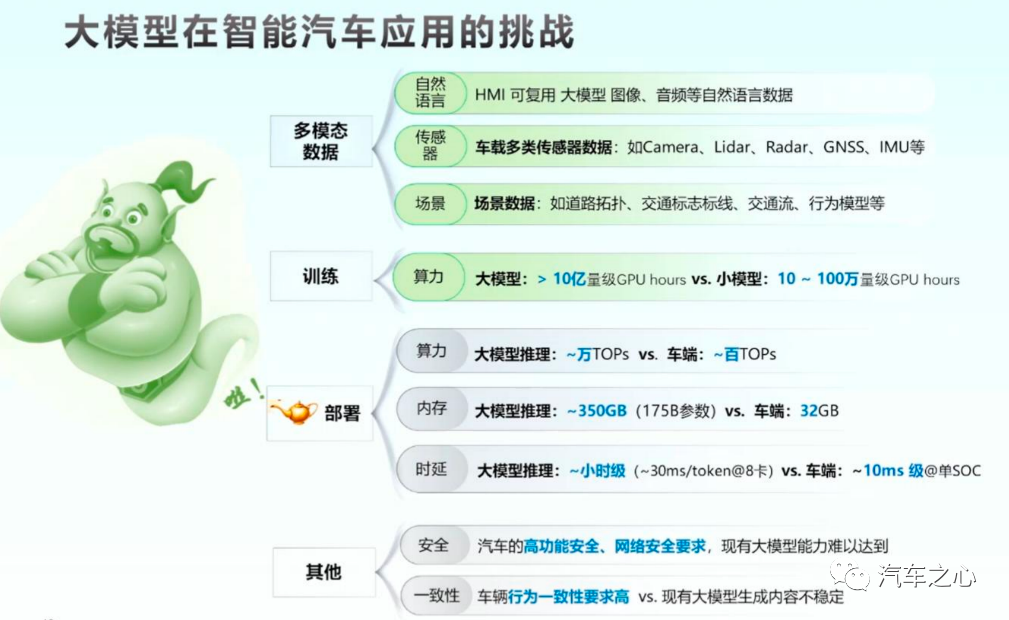
来源:《大模型与智能汽车的预见》
推动互联网发展的核心动力是带宽,而 AI 背后的关键推动力是模型的算力。
李想在《理想汽车的品牌与组织》称,为什么自动驾驶暂时不能在控制和执行层做到深度学习?
很重要的原因是计算能力远远不够。「计算能力要到 2000TOPS 以上,才能勉强接近人类大部分的能力,要做到上亿 TOPS 才能跟人类思维方式接近,跟三维的思维方式接近」。
英伟达最新一代的 SoC 芯片 Thor 的算力,高达 2000TOPS 堪称史上最强,可以全部支持自动驾驶工作流。
与之相比,特斯拉的 FSD 自研芯片的算力为 144 TOPS,仅仅为前者的 1/14。
不过,特斯拉并不一味强调算力,而是在芯片与整车的适配方面做到了领先。
该自研芯片算力可以支持 FSD 芯片的 8 个摄像头,顺利完成视觉方面的处理工作。有消息称,特斯拉正与台积电开发下一代 HW 4.0 平台,性能是上一代的 3 倍。
算力,对大模型落地意味着什么?
地平线 CTO 黄畅认为,在自动驾驶场景中,大模型在车端会优先从环境模型的预测和交互式规控和规划开始应用。
「这个场景不需要特别的大规模参数模型,在百 Tops 级别的算力平台上就能应用,3~5 年内就可以初步上线」,「但如果从感知到定位地图到规控,整个端到端的闭环做出来,则需要一个更大规模的参数模型,大概需要 5~10 年的时间」。
现有算力局限下,在大模型方面有所进展,国内车企或只能在一些技术领域率先突破。
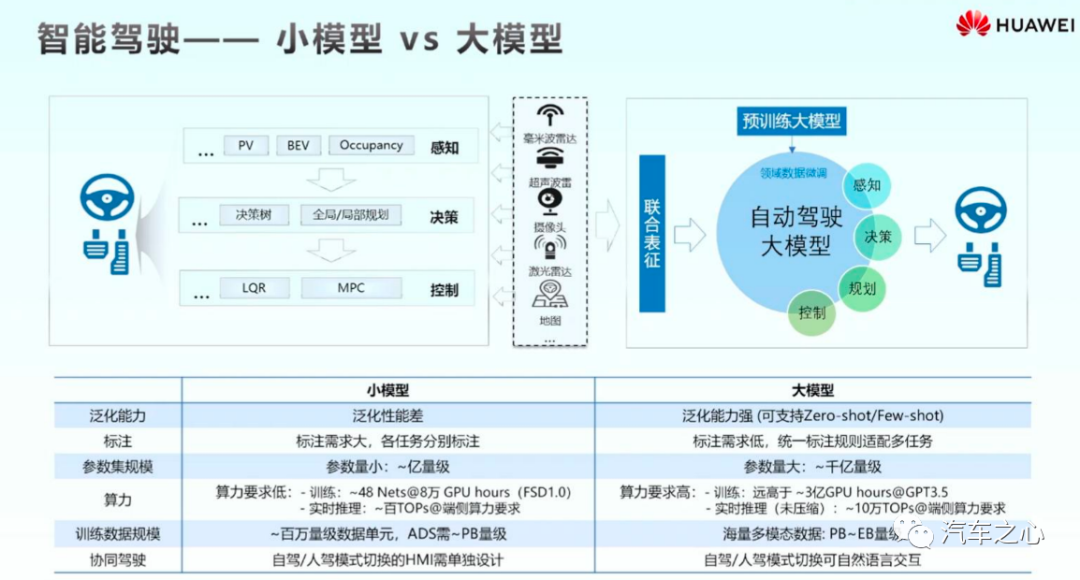
来源:《大模型与智能汽车的预见》
在车载部署场景下,只有数百 Tops 的芯片算力,远远达不到大型模型的要求。
为了顺利推动大模型上车,自建超算中心成为车企下一步的必选项。
毫末智行董事长张凯曾表示,「超算中心会成为自动驾驶企业的入门配置」。
目前,「上云端」的车企,包括特斯拉、吉利、蔚来、毫末智行、小鹏、理想等,均在搭建云端超算中心。
7 月 20 日,特斯拉 CEO 埃隆·马斯克透露了特斯拉超级计算机 Dojo 的最新进展。
虽然这台超算目前仅用于人工智能机器学习和计算机视觉培训目的,但未来会向大模型方向发力。Dojo 超级计算机系统的算力高达 1.1EFLOP。
在国内,吉利星睿智算中心的云端总算力达 81 亿亿次每秒(81000TFLOPs);
小鹏汽车智算中心「扶摇」,具备 60 亿亿次浮点运算能力(60000TFLOPs);
毫末智行联合火山引擎推出智算中心雪湖•绿洲 (MANA OASIS),浮点运算可以达到每秒 67 亿亿次(67000TFLOPs)。
它们相比 Dojo,仍然存在一定距离。
最终要实现高阶智能驾驶的能力,另一大关键在于数据训练。
大模型下的高阶智能驾驶要想实现数据快速迭代,大概需要数据量至少积累 1 亿公里。
2022 年 11 月前后,特斯拉的车队已累计行驶了 30 亿英里(约 48 亿公里),其中有 13 亿英里是配备 Autopilot 硬件的特斯拉汽车行驶所得。与之相比,「国内厂商的数据量大概会小 1-2 个数量级」。
大模型技术在提升数据标注速度方面亦有贡献。
在 Mind GPT 发布之后,李想称:
「我们一年要做大概 1000 万帧的自动驾驶图像的人工标定,外包公司价格大概 6 元到 8 元钱一张,一年成本接近一亿元。当我们使用大模型,通过训练的方式进行自动化标定,过去需要用一年做的事情基本上 3 个小时就能完成,效率是人的 1000 倍。」
最终,车企之间比拼的是谁的闭环数据更多。
在不同国家、不同场景下的训练数据不同,因此不能直接复用。
汽车销量至关重要,需要更多数据以帮助大模型解决 AI 的泛化能力。这不仅要求企业要给车辆装满传感器和计算平台,卖出去的数量也要足够多。
基于此,有观点认为,动驾驶技术最先落地的国家可能是中国。中国的汽车保有量更多,道路系统更加复杂。
不过,这个观点尚未成为业内共识。
瑞银(UBS)对外称,在实现完全自动驾驶之前,还需要几年的时间,而且「首先会在北美实现」。
瑞银认为,特斯拉可以利用自己的超级计算机 Dojo 来实现人工智能能力,但要实现完全自动驾驶,还需要几年的时间。
无论超算平台的建设,数据训练等均是烧钱的生意。
为了提升 ChatGpt 的能力,Open AI 在 8 年间耗费十多亿美元的训练成本。
如何在有限成本的情况下,尽可能实现高算力,走好这个「平衡木」,车企或将掀起下一场的「卷」王之争——抢占大模型技术能力第一/场景落地第一/商业化第一。
04 尾声
在一次演讲中,计算机领域知名专家、奇绩创坛创始人陆奇称,「人工智能的下一个拐点是什么?下个拐点将是自动驾驶+机器人+空间计算的组合,也就是说人在物理空间当中行动的代价也从边际成本走向固定成本。」
陆奇认为,机器人和自动驾驶将是人类最大的两个产业。
「那谁会站住未来这个拐点?我认为特斯拉会有很高概率站住这个拐点,因为它的自动驾驶和机器人非常厉害。」
成为一家人工智能企业,不仅是特斯拉的愿景,也是国内车企的新目标。
比如,李想在 2023 年年初发布的理想汽车全员信中称,「理想汽车的愿景是到 2030 年成为全球领先的人工智能企业」。
从自动驾驶到人工智能,智能汽车企业拥有广阔无垠的星辰大海。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。