






 技术咨询
技术咨询 代买器件
代买器件 商务客服
商务客服 研发客服
研发客服智能手机10多年来,成像质量的提升超过了4EV。从直觉来看,这些提升最大的功臣应该是图像传感器及光学系统的发展。不过事实上,DxOMark总结认为,这4V的提升仅有1.3EV是来自图像传感器和光学系统的提升,还有3EV来源于图像处理,或传说中的计算摄影(Computational Photography)。
本文的标题所谓“1亿像素都是垃圾”,指的是1亿像素的图像传感器为画质的贡献可能并没有人们想象得那么大,并不是说1亿像素没有意义。既然这4EV主要不是1亿像素图像传感器的功劳,那应该就是ISP(图像处理器)的功劳了?
ISP是专门用于影像处理工作的,包括反拜耳(demosaic)、抑噪、自动白平衡、自动曝光、自动对焦、色彩对比度修正等等,尤其是其中的图像后处理。从图像传感器直接生成的原始影像实际上是不大能被人眼接受的,因此需要经过各种处理后才形成最终的照片输出。
不过无论是手机摄像头,还是车载、工业摄像头,在CV、图像后处理等方面,AI所占的比重都越来越大。AI专用处理器或单元都开始加入到图像处理流程中来。
去年华为和三星在其手机芯片发布会上,都提到了ISP与NPU的“融合”,NPU当然就是专用于AI计算的处理器了。三星还为此专门取了个名字叫AISP——应该就是AI+ISP的意思。华为当时宣称是“业界首次实现ISP+NPU的融合架构”。不管这个“业界首次”是否是真的,这种“融合”都相当值得探究。
本文尝试从现有资料,以及我所知的一些不成体系的信息来简单谈谈,这种“融合”究竟是怎么回事,以及AI对于拍照而言的价值在哪儿。本文将AI处理器或单元统称为NPU,不同的厂商对其有不同的称谓,如苹果称其为NE,联发科称其为APU,高通称其为AIE。
NPU与ISP的协同工作
事实上,迄今我们依然无法完整地搞清楚,现有智能设备的ISP和NPU之间是怎样协同工作的。华为在发布会上展示的一张图只是个简略的概要图(下图)。其中提到,针对“4K像素级AI Video处理”,ISP负责颜色/亮度还原、快速对焦,而神经网络完成细节还原、去噪。两者配合来输出影像。

三星方面对于其“AISP”的宣传也比较模糊,称之为“全新ISP架构”,让AI在影像拍照和视频上的使用“更加便捷和实时”,“并进一步升级了智能自动白平衡、自动曝光、降噪等功能”。三星在Exynos 1080的发布会上提到,NPU可以进行拍摄物体与风景的检测,并优化白平衡和曝光。
即便我们不清楚ISP和NPU具体如何协同,或者说图像处理通路是如何,NPU在此究竟扮演了什么角色还是有办法搞清楚的。
谷歌Pixel手机在此前的几代产品中引入了PVC(Pixel Visual Core)。这是谷歌设计的基于Arm的影像处理器。PVC内部的IPU(image processing unit)本质上是完全可编程的影像、视觉与AI多核专用架构。Pixel二代、三代的多款机型都采用了该处理器。Pixel 4之上,迭代产品更名为Pixel Neural Core,应该算是对其AI计算属性的一种强调吧。

从PVC,可一定程度理解这种专用处理器是如何做影像后处理的。PVC主体上包含8个IPU核心,据说是谷歌自己设计的,每个核心有512个ALU单元。谷歌为其配套了开发生态,针对图像处理采用Halide语言,机器学习则为TensorFlow,针对底层硬件有专门的编译器。而Android三方应用开发者直接使用Android Camera API,就能利用PVC的算力。
Pixel 5已经去掉了这种专用芯片,不知后续是否还会继续引入。PVC作为一种手机主SoC(如骁龙处理器)之外的一枚专用加速器,想必其处理时延会比较高,从直觉来看可能不及直接将NPU集成到SoC上的方案——毕竟如今手机SoC的AI算力也是越来越强的。猜测未来的Pixel设备极有可能会弃用这种专门的PVC。
最初那些年,PVC参与的影像后处理工作,包括了HDR+、自动白平衡、降噪等。后文借用谷歌这些年在计算摄影方面的研究成果,也会尝试谈谈AI具体是如何参与到影像后处理的。
不过谷歌毕竟不是专门的手机芯片制造商,很难直接自己造个专属的手机SoC,为其拍照的设想做最完美的服务(从这里也能看出苹果和华为的优势)。不难想象,当AI计算在影像处理方面的作用越来越大之时,华为、三星这些芯片制造商,也就开始了NPU与ISP的融合工作。
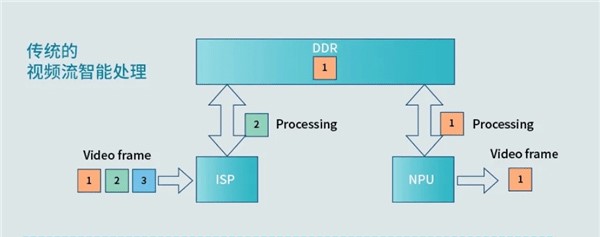
那么现在所谓的“融合架构”要如何体现呢?和此前谷歌这种外置一枚PVC的方案又有何不同?华为公布的少量资料,应该是我们获知ISP、NPU(以及谷歌PVC)如何协同工作的一部分知识碎片。
从上面这张图中可见,“传统的视频流智能处理”,ISP与NPU的数据共享还需要依托于DRAM主内存。也就是说,即便同在一枚SoC上,这两个处理单元之间还需要靠主内存这种慢速存储来做数据共享(就像CPU和GPU的常规工作模式那样)。那么AI影像处理的时延,自然就会比较高了,反映在拍照上可能是等待时间较长,AI视频处理则会“不可用”。虽然我们无法断言这个信息的真伪,不过PVC和手机主SoC之间,起码应该会是这样通信的。
我们现在仍然不清楚ISP+NPU完整的影像处理通路是什么样。比如可能是先给ISP做处理,然后再转交给NPU做后续各种处理,直接就输出图像了。但这也太过理想,更合理的方案应该是某些处理工作交给ISP(比如自动对焦、自动测光),某些则交给NPU(比如自动白平衡、AI降噪),两种处理器进行影像数据的交替处理。这对两种处理器的通信、协同提出了比较高的要求;另外对究竟哪些工作由ISP处理,哪些工作交给NPU处理这样的问题,也提出了要求。
华为在麒麟9000媒体沟通会上,在NPU环节提到过一个Smart Cache 2.0的概念。当时我并没有完全理解,始终认为无非麒麟9000有个系统级LLC,也就是现在手机SoC上普遍会出现的一种system cache——这种缓存在SoC上面向各种IP模块共享,包括CPU、GPU、NPU等。最早似乎是苹果在A系列芯片上采用此种设计,后续高通、华为也相继跟进。
当时华为Fellow艾伟说:“相对直接访问内存来说,带宽提升了一倍,能效提升15%。”这句话现在想来,可能是指ISP与NPU通信时,部分共享system cache,而不是去内存转一圈(不过smart cache也有可能是分层的缓存方案,内存或许也会参与)。
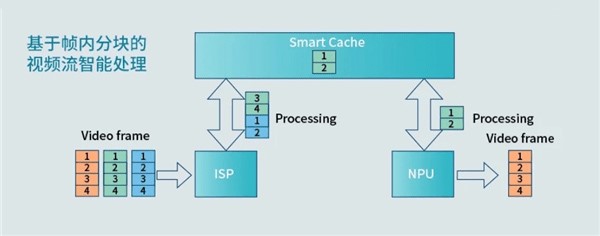
与此同时,ISP和NPU原本的工作方式是不同的。在视频处理时,ISP以行或者帧内分块为单位进行工作;而NPU则是以整个帧或整个画面为处理单位。所以ISP需要忙完整张画面后,才会将其传输给NPU。这样两者协同的工作效率是比较低的,NPU可能会有比较长的等待时间。
华为的这种ISP+NPU融合架构是将每一帧进行“切片”,也就是把每帧的整个画面拆分成更小的单元。ISP与NPU的处理最小单元都成为这种“切片”。ISP在完成一个切片后就可以传递给NPU去处理。这么做不仅降低了NPU的闲置率,应该也能降低带宽消耗。配合所谓的Smart Cache,也就提高了两者的工作效率。这应该就是ISP+NPU融合架构的关键所在。

Mate40有个录制功能,是将摄像头中拍摄到的画面进行逐帧的卡通化处理——非延后处理,而是拍摄当下就实时显示。这项应用,很类似于2016年德国图宾根大学研究人员用卷积神经网络,实现风格化转换的一项研究,包括为人像应用毕加索、梵高等各种风格。这也是NPU参与工作,并且做到实时处理的一种显著感知了。
AI在手机拍照中,扮演了什么角色?
不过NPU+ISP进行影像处理的关键还是在于,NPU究竟有什么用?如果只是做个画面卡通化处理,或者智能美颜之类,那也没什么太大的意思。事实上,现阶段AI参与影像增强,是部分替代了ISP的工作的。一个比较典型的例子是画面的自动白平衡,以前这是ISP的工作,现在则部分或者全部可转交给NPU去完成。
自动白平衡为什么需要AI去做呢?无非在于传统的自动白平衡修正方案,在很多情况下都没那么靠谱。白天光照充足时,或许还没什么问题,但到了夜晚情况就会比较复杂。

比如像上图这样夜间由于光照,色偏本就很严重的场景,针对很多拍摄对象是难以做颜色修正的。所以谷歌利用机器学习开发了一套算法。模型训练过程,是采用Pixel手机来拍摄多样化的场景,然后针对所有拍摄的照片,在色彩校准显示器上手动调整照片白平衡。以此来进行训练。而手机上的AI单元执行的是inference的过程,可得到上图这样的结果。
这是AI在自动白平衡中的一个典型应用。在这套方案中,可能涉及的问题主要包括AI算法是否能够获得比ISP传统后处理算法更优秀的结果,NPU如何与ISP协作(包括图像处理通路如何),训练数据如何获取等。
尤其是训练网络所需的数据从哪儿来。谷歌的数据是自己用Pixel手机,或者通过一些方案自行采集的,比如上面这个自动白平衡的例子。这似乎也是谷歌的老传统了。这里还可以举几个用AI实现画质增强的同类例子:
(1) 模拟背景虚化
去年《》一文详细介绍过这种方案。除了双摄+双像素这些原本实现背景虚化(浅景深模拟)的传统方案,谷歌另外用AI对照片背景虚化做了加强。

谷歌为了训练所需的神经网络,亲自打造了一台五摄装备,其实就是把5台Pixel 3手机固定在一起,拍了很多人像照片,“五摄”同时拍摄画面就能生成相对高质量的深度图。以此作为神经网络的输入。这样用户在用手机拍摄人像时,AI就能辅助推断人像深度了。
(2) 消除画面噪声
UC Berkeley和Google Research前两年发表过一篇多帧降噪的paper,题为Burst Denoising with Kernel Prediction Networks。用CNN网络预测运动向量+降噪kernel的方法。数据来源是Open Images dataset,针对每张图像生成N张裁剪图像,每张做随机偏移;而且每张照片做逆向gamma校正,转换为近似线性颜色空间,并利用噪声模型来添加噪声——也就模拟了多帧画面。这些作为训练数据。

最终期望达到的,就是用手机拍照,一次快门就拍下多张图片,通过这种多帧堆栈来获得一张纯净度比较高的照片。这是利用机器学习实现多张堆栈降噪的典型方法了。
(3) 视频拍摄防抖
谷歌针对Pixel 2手机应用过一种名为Fused Video Stabilization的视频拍摄防抖方案。这套方案包含3个处理阶段:第一阶段做位移分析,获取陀螺仪的信号、光学防抖的镜头运动,来精确预估摄像头的位移。然后在位移过滤阶段,结合机器学习和信号处理,来预测拍摄者移动摄像头的意图。最后进行帧合成,达成优于传统光学、数字防抖的效果。AI属于其中的一个阶段。

(4) HDR+高动态范围
HDR+其实是谷歌一次按下快门,多张短曝光照片堆栈的一种算法。这项特性本身应该并没有加入AI。不过2018年,谷歌宣布向研究社区公开HDR+的这些堆栈照片数据,包括不同对象、亮度、动态范围和亮度的。据说有不少做神经网络研究的paper都采用了这套数据集。HDR+因此也能算是AI拍照的组成部分了吧。

Pixel手机更多应用了AI的功能和特性,这里就不再多做介绍了,有兴趣的可参见谷歌的AI Blog。比如说前两个月谷歌才公布的“人像光照”特性,是对2D照片的人像做模拟打光——即为照片加人造光源。人像光照主要应用的就是机器学习,谷歌动用到了位于不同角度的64个摄像头+331个LED光源,从各个角度来拍摄不同方位的打光照片,以此作为神经网络的训练数据来源。效果还是比iPhone用3D结构光实现的打光效果更靠谱的。

华为这边因为硬件实现上有了NPU+ISP融合架构的加成,所以更多的AI特性得以应用到了视频后处理、实时处理以及AR之上。有兴趣的可参见《》一文的NPU部分。
AI拍照将走向何方
前面列举AI加强成像画质的,典型如降噪、自动白平衡,本质上都是传统摄影的构成部分,而不是类似于“趣味摄影”的小特性,或者在很多人看来可有可无的部分。它们在手机中是真真切切地影响到了最终的成像画质的。华为有底气宣称Mate40的5000万像素碾压别家1亿像素,AI在其中应当占了较大比重。
本文仅作为拓宽见闻的一篇文章,让各位读者了解,AI在如今的手机摄影中大致有着怎样的作用(以谷歌为代表),以及从硬件的角度尝试管中一窥NPU+ISP的新融合架构(以华为为代表)。未来手机乃至相机拍照,越来越多地引入AI,也是必然的。且计算机摄影相关的研究也还在持续中。
未来手机上的AI摄影会走向何方,这个话题太大了。不过本文的最后再分享一篇相当有趣,来自苏黎世联邦理工学院去年发布的一篇paper(),大致意思是将ISP彻底替换为NPU。
几名研究人员采用华为P20 Pro,以及单反佳能5D4拍的照片为神经网络的训练数据,包括两者拍摄的原始RAW图像(未经过反拜耳的原始数据),以及经过ISP后处理最终输出的JPG照片。训练过程就是将P20 Pro拍摄的RAW Bayer数据,转成佳能5D4同场景拍摄的JPG照片(也就是将图像传感器输出的原始数据,映射到高质量的照片)。数据集包含10000张实拍照片。

用训练得到的PyNET网络所做的后处理,与华为P20自己的ISP所做后处理的比较
最终获得的PyNET模型,就可以直接将手机图像传感器获取到的原始数据,经过inference——也就是类似NPU这样的AI处理器,来输出JPG照片了。也就是AI单元学习了ISP的工作流程,并替代了ISP。“在不需要有关传感器、光学相关的知识”的情况下,就能做到原本ISP需要各种tuning才可达成的工作。(不过要是图片后处理流程本来就包含了AI过程,是否就是个嵌套了?)
听起来是个很有意思的思路,当然其实际效果如何又是另一个话题了,有兴趣的同学可前往查看。
相关文章









