近日,清华大学集成电路学院在2024 ACM/IEEE第51届年度计算机体系结构国际研讨会(ISCA)上发表了国际首款面向视觉AI大模型的三维DRAM存算一体架构,可大幅突破存储墙瓶颈,并基于三维集成架构特点,实现相似性感知计算,进一步提高AI大模型的计算效率。
存算一体作为新一代计算技术,在数据运算和存储过程中实现了一体化设计,被认为是后摩尔时代最重要的发展方向之一,将为人工智能的大规模应用提供不竭的算力支撑。在更早之前,中科院和清华大学就在该领域不断钻研,逐步突破。
一
老问题:内存墙和IO墙的桎梏
理解该文前,需要对内存墙和IO墙现象进行基础理解,这两类现象来源于当前计算架构中的多级存储。如图所示,当前的主流计算系统所使用的数据处理方案,依赖于数据存储与数据处理分离的体系结构(冯诺依曼架构),为了满足速度和容量的需求,现代计算系统通常采取高速缓存(SRAM)、主存(DRAM)、外部存储(NAND Flash)的三级存储结构。
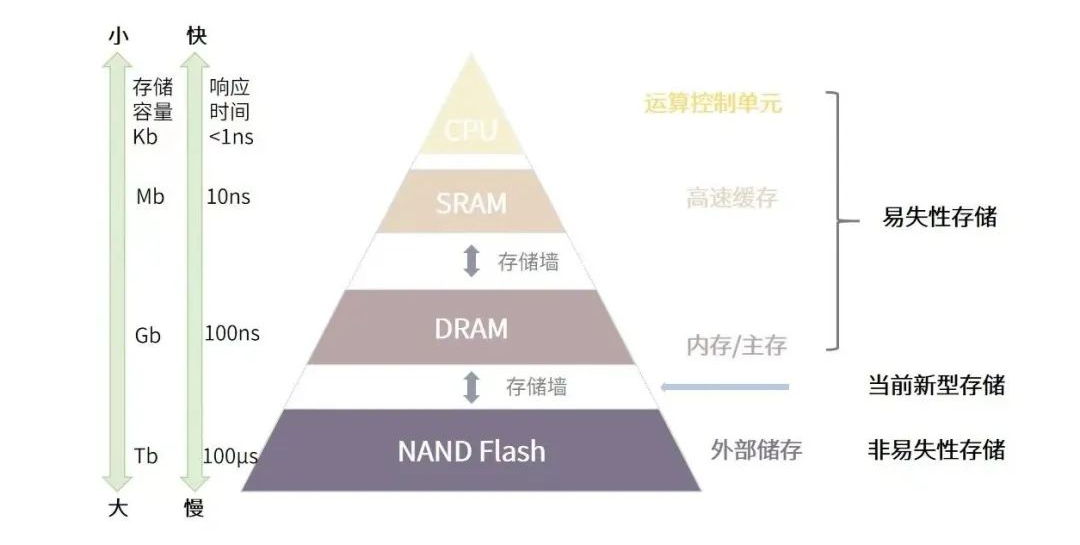
常见的存储系统架构及存储墙
(全球半导体观察制图)
每当应用开始工作时,就需要不断地在内存中来回传输信息,这在时间和精力上都有着较大的性能消耗。越靠近运算单元的存储器速度越快,但受功耗、散热、芯片面积的制约,其相应的容量也越小。如SRAM响应时间通常在纳秒级,DRAM则一般为100纳秒量级,NAND Flash更是高达100微秒级,当数据在这三级存储间传输时,后级的响应时间及传输带宽都将拖累整体的性能,形成“存储墙”。
IO墙则产生于外部存储中,因为数据量过于庞大,内存里放不下就需要借助外部存储,并用网络IO来访问数据。IO方式的访问会使得访问速度下降几个数量级,严重拖累着整体性能,这即是IO墙。
现代处理器性能的不断提升,而内存与算力之间的技术发展差距却不断增大。业界数据显示,在过去的20多年中,处理器的性能以每年大约55%速度快速提升,而内存性能的提升速度则只有每年10%左右。并且,当代内存容量扩展面临着摩尔定律的压力,速度在逐年减缓的同时,带来的则是成本的愈发高昂。随着大数据AI/ML等应用爆发,以上问题已经成为制约计算系统性能的主要因素。
二
新问题:近存计算与“滩前问题”
据悉,岳志恒该论文题目为Exploiting Similarity Opportunities of Emerging Vision AI Models on Hybrid Bonding Architecture,尹首一教授,胡杨副教授为本文通信作者,岳志恒为论文第一作者,论文合作者还包括香港科技大学涂锋斌助理教授,上海交通大学李超教授等。
更早以前,岳志恒就发表了题为Understanding Hybrid Bonding and Designing a Hybrid Bonding Accelerator《理解混合键合和设计混合键合加速器》的论文,可视为上文的前身。该文在3D DRAM基础上,提出了一种利用CSE加速视觉AI模型的混合键合设计,并提供了混合键合设计的全面分析,在多种基准工作负载和数据集上评估,该项工作平均提高了5.69×~28.13×的能效和3.82×~10.98×的面积效率。总体而言,该文涉及了混合键合DRAM技术发展、I/O密度的限制和扩展的难题、2.5D TSV先进封装的作用等内容。
存储计算随着时代的发展已出现各种新的问题和限制。在岳志恒的论文中,提到了近存计算与“滩前问题”两个概念。近存计算则是近年行业广泛采用HBM作为解决方案后,再辅以先进封装方式将HBM芯片与计算芯片在silicon interposer上集成,以此计算芯片与存储芯片近距离集成封装,实现了计算单元与存储单元之间数据的较短距离传输,通过“近存计算”提高处理性能。
在此突破下,此种高带宽近存方案仍受到“滩前问题”制约。滩前问题是指,假设计算芯片是一个海岛,则可以放置数据I/O通道的位置为岛的沙滩位置,而沙滩的长度则是可以放置I/O的总长度。当受到信号串扰等因素约束时,相邻的I/O位置受限,从而导致2.5D近存集成方案下I/O数量无法进一步提升,从而难以提升带宽。
为了解决滩前问题,目前业界正逐步提高计算单元可用带宽,如二维存内计算,就是基于DRAM的存内计算进一步将计算单元集成在存储阵列内部,具体而言,在每个存储Bank周围集成计算单元,Bank数据读出后,被相邻计算单元立即处理,实现了Bank级别的存内计算,有效解决了二维近存方案的滩前问题。
二维存内计算也有着缺陷,论文提到,与先进逻辑工艺相比,集成于DRAM阵列内的计算电路性能有差距、面积代价高。同时,引入的计算单元将挤占DRAM存储阵列面积,造成DRAM自身的存储容量下降。例如,Samsung HBM-PIM在引入存内计算单元后,存储容量减少了50%。
三
清华突破:创新三维存算融合架构
针对近存架构的带宽瓶颈和二维存内计算架构的工艺瓶颈问题,研究团队首次探索了三维立体存算一体架构方案。此方案通过将计算单元与DRAM存储单元在垂直方向堆叠,单元间以金属铜柱作为数据通道互联,有效解决了“滩前问题”,能任意位置放置数据I/O,大幅提高数据通路密度。DRAM阵列与计算逻辑可独立制造,逻辑电路不受DRAM工艺限制,不影响存储容量。
在本架构中,DRAM阵列由基本DRAM Bank组成,每个DRAM Bank与对应的计算Bank通过hybrid bonding工艺在垂直方向堆叠,二者通过高密度铜柱交互数据。互连铜柱距离短、寄生容抗小,数据通路等效于互连线直连,每个DRAM Bank与对应的计算Bank构成了Bank级存算一体单元(如图1所示)。
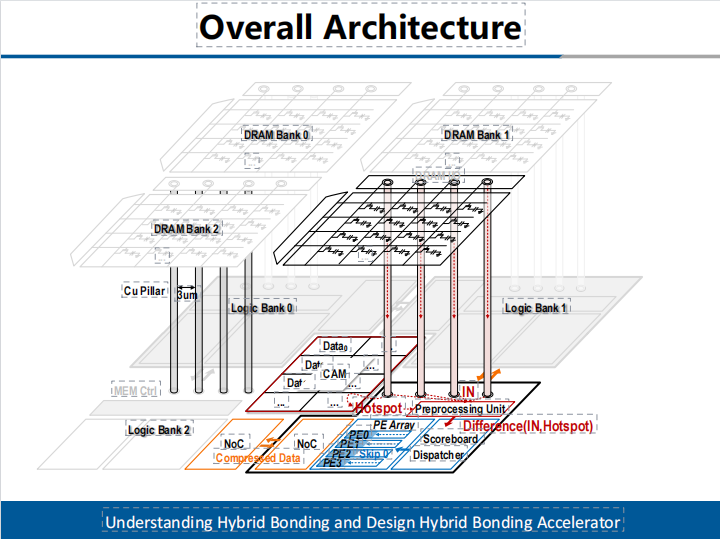
图1,三维DRAM存算一体架构
团队同时探索了Bank级存算一体架构下的设计空间,包括DRAM Bank适配的计算Bank算力,计算Bank的片上缓存大小,三维集成引入的面积开销等;并深入分析了三维架构的硬件可靠性及散热问题,实现了完整的存算一体架构设计,大幅突破了存储墙瓶颈,对AI大模型运算,提供了有力的支持。
四
相似性感知的三维存算一体架构
为进一步提升系统性能,设计团队提出了相似性感知三维存算一体架构。实验发现,激活数据在存储阵列内连续存储时,局部区域数据具有相似性,本文归结为存储数据的簇相似效应。利用此特性,设计团队提出在三维存算一体架构内,每个计算Bank能够独立且并行地挖掘对应DRAM Bank内数据的相似性,并利用相似数据完成计算加速,提升系统性能。
该存算一体设计克服了三个关键技术难点:1.如何寻找相似数据。由于DRAM Bank空间大,遍历搜索相似数据将引入极大的功耗和时间开销;2.如何利用相似数据。先前存算一体单元并未针对数据相似性特点设计,无法充分挖掘其带来的性能增益;3.如何平衡相似数据。由于在三维存算一体架构内,不同的计算Bank独立并行,因此系统性能受制于负载最重的计算Bank。本存算一体架构为解决以上困难,提出了三项关键技术:
1
基于热点机制的DRAM Bank相似数据搜索方案
研究团队提出采用热点机制完成快速的相似数据搜索。热点数据为具有区域信息代表性的数据,即其与区域内多数数据有高相似性。本设计采用内容可寻址单元收集不同区域的热点数据,新数据从DRAM Bank读出时先在该单元内快速搜索匹配区域热点数据,此热点数据作为参考值与后续读出数据执行差分操作(如图2所示)。由于数据之间存在相似性,因此差分结果往往具有高稀疏特性,可被用于计算加速。

图2相似性感知的硬件加速单元
2
针对相似数据特性的渐进式稀疏计算单元
当DRAM Bank数据读出并经预处理单元差分操作后,由于热点数据与DRAM Bank内区域数据具有相似性,异或结果往往在高比特位存在大量0值。针对这一稀疏特性,存算一体架构设计了渐进式稀疏检测机构。先将完整数据按权重位置分块,判断数据比特块是否全为0,若全0则直接跳过对应数据块计算,非0部分由计分牌硬件单元迅速定位有效数据。完成稀疏检测后,计分牌单元选择将非冗余数据块送入PE阵列进行计算,从而跳过了稀疏比特,提高了计算效率(如图3所示)。

图3渐进式稀疏计算单元
3
针对数据相似性差异的负载均衡机制
本存算一体架构采用Bank级并行,不同计算单元对应的DRAM Bank内数据相似性可能存在较大差别(如图4所示)。这是因为数据相似性由硬件单元在运行时动态检测,无法在任务映射时提前判别。针对不同计算Bank任务不均衡的问题,本方案借助DRAM Bank间的数据相似性,对任务负载进行压缩处理,并在不同计算Bank间重分配任务,减少对片间路由网络带宽的挤占,实现Bank级别的负载均衡和性能提升。

图4由于数据相似性差异导致的负载不均衡
本工作完成了存算一体架构设计、单元电路实现及性能功耗面积分析。实验结果显示在系统性的AI任务负载上,本架构相比公开报道的高算力AI芯片,如Wormhole和TPUv3,3D基线实现了6.72倍和2.34倍的吞吐量提升。相似性技术进一步将吞吐量提高了1.21倍。(如图5所示)在能效方面,3D基线相较于Wormhol和TPU实现了3.49倍和2.89倍的提升。数据相似性进一步提升了1.97倍的能效。(如图6所示)
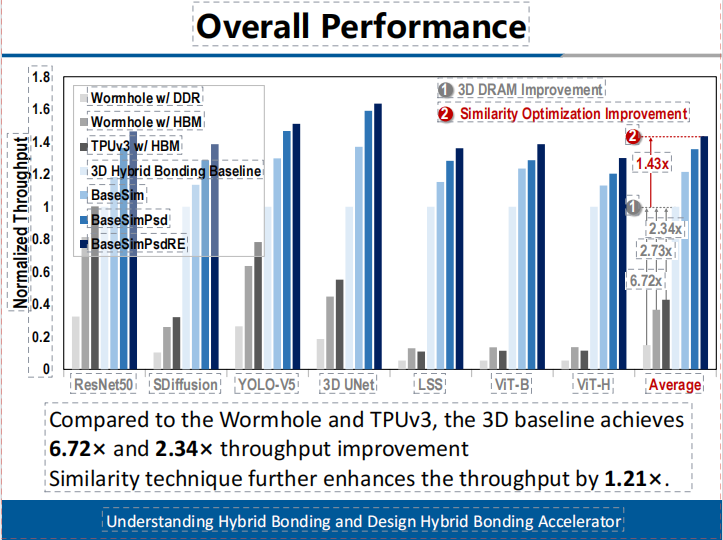
图5有效吞吐提升
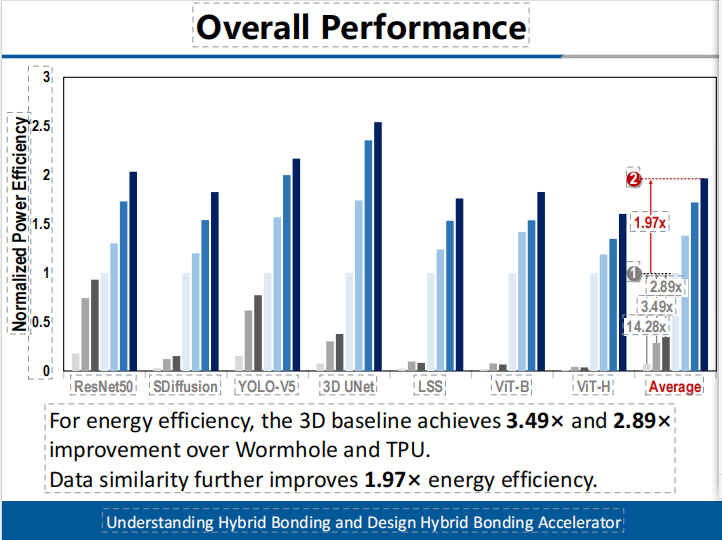
图6有效能效提升
五
存算一体新突破,中科院、清华齐发力
在存算一体领域,我国科学院、高校坚持研发钻研。今年2月,中国科学院微电子研究所刘明院士团队研发出基于外积运算的数模混合存算一体宏芯片,设计了一种数模混合浮点SRAM存内计算方案,提出了模拟与数字存算宏的混合方法,结合了使用模拟存算方案进行高效阵列内位乘法和使用数字存算方案进行高效阵列外多位移位累加的优点,达到整体上高能量效率与面积效率。通过残差式数模转换器架构,使数模转换器所需分辨率仅为输入位精度的对数,实现了高吞吐率和低开销。通过基于矩阵外积计算数学原理的浮点/定点存算块架构,矩阵-矩阵-向量计算可通过累加器元件完成。
该突破以“A 28nm 72.12TFLOPS/W Hybrid-Domain Outer-Product Based Floating-Point SRAM Computing-in-Memory Macro with Logarithm Bit-Width Residual ADC”为题发表在ISSCC 2024国际会议上,微电子所博士生袁易扬为第一作者,张锋研究员与北京理工大学王兴华教授为通讯作者。该研究得到了科技部重点研发计划、国家自然科学基金、中国科学院战略先导专项等项目的支持。
据悉,同之前的数字存算方案使用矩阵内积原理的大扇入、多级加法器树相比,吞吐率更高。该架构还支持细粒度的非结构激活稀疏性以进一步提升总体能效。该存算一体宏芯片在28nm CMOS工艺下流片,可支持BF16浮点精度运算以及INT8定点精度运算,BF16浮点矩阵-矩阵-向量计算峰值能效达到了72.12TFLOP/W,INT8定点矩阵-矩阵-向量计算峰值能效达到了111.17TFLOP/W。这一研究结果为采用数模混合方案的存算一体架构芯片提供了新思路。
此外,去年10月,清华大学集成电路学院教授吴华强、副教授高滨团队基于存算一体计算范式,研制出全球首颗全系统集成的、支持高效片上学习的忆阻器存算一体芯片,在支持片上学习的忆阻器存算一体芯片领域取得重大突破。该研究成果以“面向边缘学习的全集成类脑忆阻器芯片”(Edge Learning Using a Fully Integrated Neuro-Inspired Memristor Chip)为题在线发表在《科学》(Science)上。
相同任务下,该芯片实现片上学习的能耗仅为先进工艺下专用集成电路(ASIC)系统的3%,展现出卓越的能效优势,极具满足人工智能时代高算力需求的应用潜力,为突破冯·诺依曼传统计算架构下的能效瓶颈提供了一种创新发展路径。
吴华强介绍,存算一体片上学习在实现更低延迟和更低能耗的同时,能够有效保护用户隐私和数据。该芯片参照仿生类脑处理方式,可实现不同任务的快速“片上训练”与“片上识别”,能够有效完成边缘计算场景下的增量学习任务,以极低的耗电适应新场景、学习新知识,满足用户的个性化需求。
封面图片来源:拍信网