小米自动驾驶技术:算法篇
小米汽车未公布小米自动驾驶算法的详细信息,不过通过小米汽车发布的学术论文可以一窥小米自动驾驶算法。目前,小米汽车的学术论文主要有两篇,一篇是《SOGDet: Semantic-Occupancy Guided Multi-view 3D Object Detection》,作者有新加坡国立大学的,小米汽车仅有两人。另一篇是《SurroundSDF: Implicit 3D Scene Understanding Based on Signed Distance Field》,署名作者有8位,其中六位是小米汽车的,还有两位是西安交通大学软件工程学院的,这两位当中还有一位是后来加盟小米汽车的。两篇论文的核心都是Occupancy占用网络,这一点雷军在小米汽车发布会上也有所提及。
这两篇论文前一篇侧重于3D感知,后一篇侧重于3D场景重建,3D感知的论文都不免要在nuScenes测试数据集上打榜。艰深晦涩的论文大多数人都没兴趣读完,所以我们先看小米这两篇算法论文的得分。
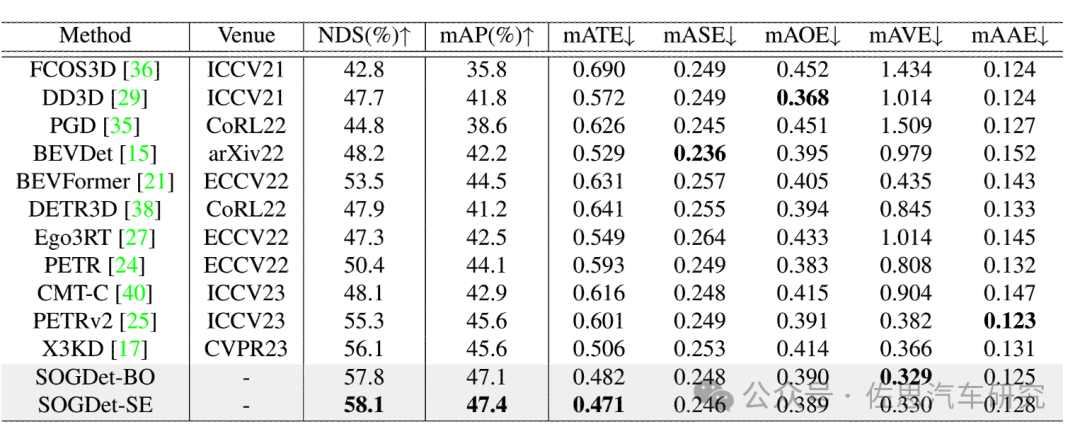
图片来源:《SOGDet: Semantic-Occupancy Guided Multi-view 3D Object Detection》论文
NDS得分58.1,这个得分应该说很低,华为在2021年10月的TransFusion得分都有71.7,零跑汽车的EA-LSS得分有77.6。不过后两者基本都是Bounding-Box的,而不是基于占用网络的,这样对比有一点不公平。

图片来源:《SOGDet: Semantic-Occupancy Guided Multi-view 3D Object Detection》论文
与另一个顶级占用网络结构TPVFormer比,基本相差不大,TPVFormer是北航提出来的。
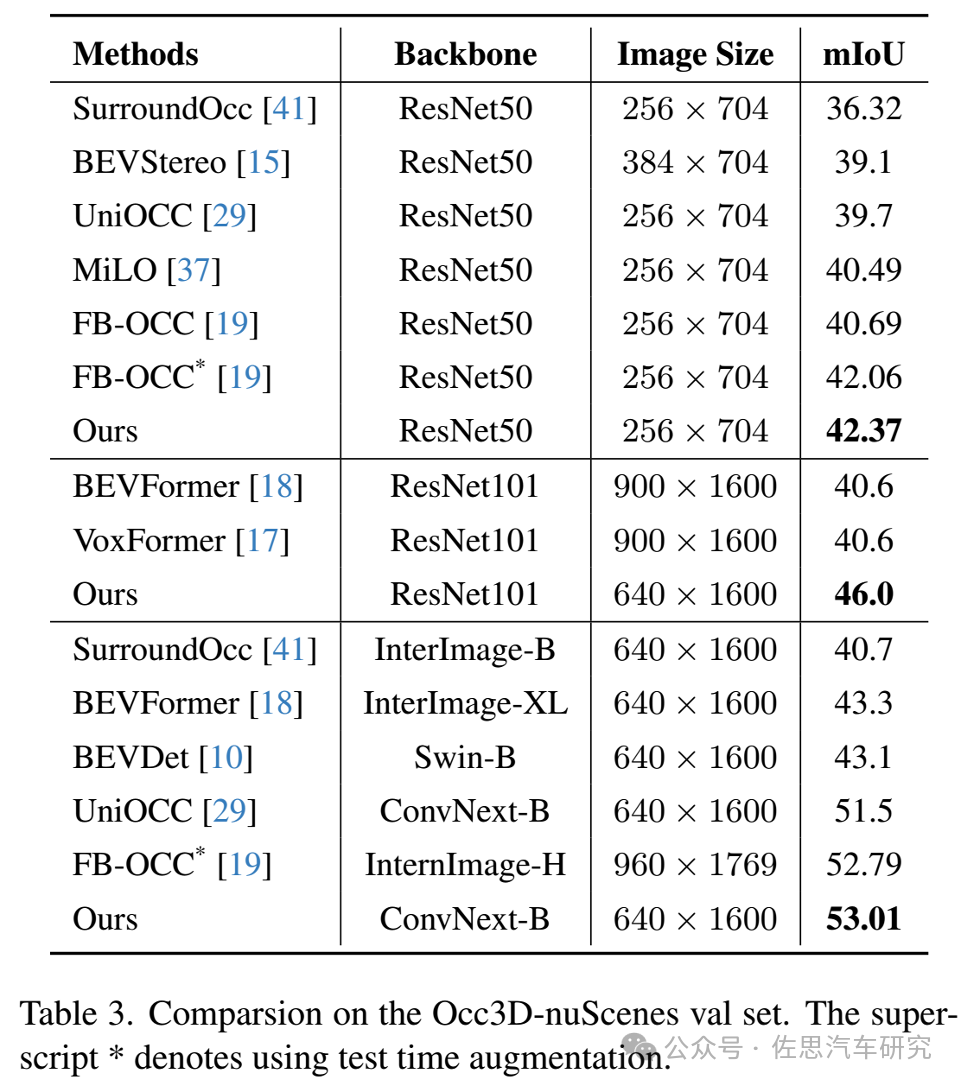
图片来源:《SurroundSDF: Implicit 3D Scene Understanding Based on Signed Distance Field》论文
《SurroundSDF: Implicit 3D Scene Understanding Based on Signed Distance Field》这篇论文算法的得分,在一众占用网络模式里mIoU得分第一。mIoU (Mean Intersection over Union,均交并比):为语义分割的标准度量。其计算两个集合的交并比,这两个集合为真实值(ground truth)和预测值(predicted segmentation)。计算公式如下: i表示真实值,j表示预测值:
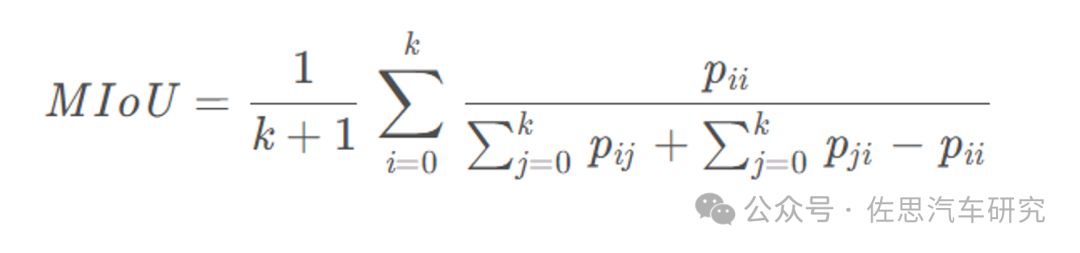

图片来源:《SurroundSDF: Implicit 3D Scene Understanding Based on Signed Distance Field》论文
3D场景重建的得分,基本上也可以算是第一。
下面来具体看这两篇论文。

图片来源:《SOGDet: Semantic-Occupancy Guided Multi-view 3D Object Detection》论文
SOGDet就是将3D感知与3D语义分割占用网络预测结合,主要是提高非道路环境的感知,构建一个完整的真实3D场景,使得自动驾驶决策系统更好地理解周边环境,给出正确的道路规划,非道路环境包括了植被(绿化带、草地等等)、人行道、地形以及人工建筑。
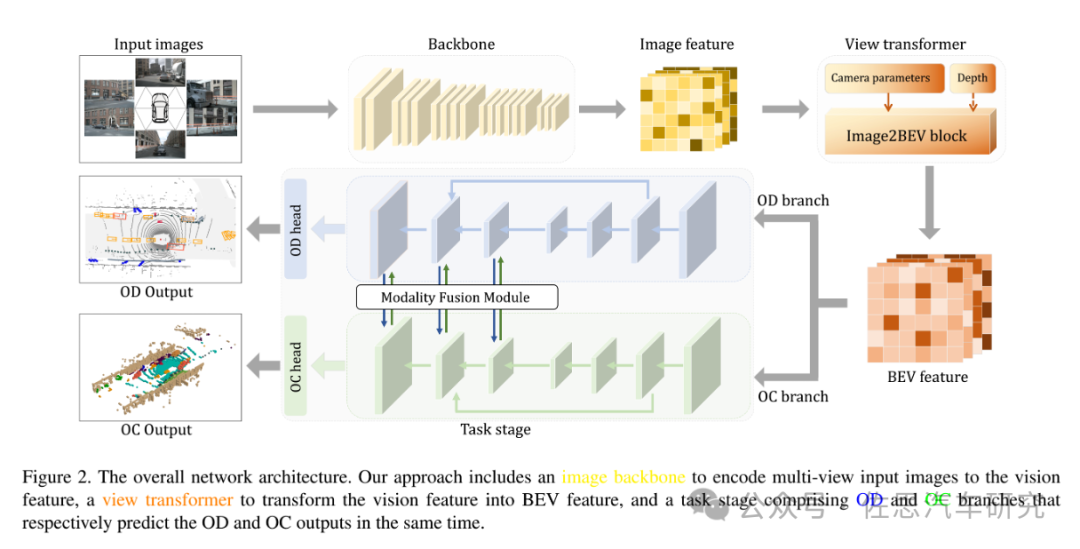
图片来源:《SOGDet: Semantic-Occupancy Guided Multi-view 3D Object Detection》论文
小米SOGDet的网络架构,并无独特之处,毕竟网络基础都是谷歌和META构建的。目前顶级自动驾驶网络基本都是三部分,其中骨干Backbone部分,还是基于CNN,没办法,Transofrmer运算量太大,无法使用,大家基本还是用ResNet50/100。也有少数使用谷歌的ViT,但实际无法落地。多头部分使用View Transformer做BEV变换。这里仍然使用英伟达提出的经典的LSS方法,其中:
Lift——对各相机的图像显性地估计像平面下采样后特征点的深度分布,得到包含图像特征的视锥(点云);
Splat——结合相机内外参把所有相机的视锥(点云)分配到BEV网格中,对每个栅格中的多个视锥点进行sum-pooling计算,形成BEV特征图;
Shoot——用task head处理BEV特征图,输出感知结果。LSS是2020年提出的,目前还做了不少改进,主要是深度修正(Depth Correction)和具有相机感知能力的深度估计(Camera-aware Depth Prediction)。
另外,还提出了高效体素池化(Efficient Voxel Pooling)来加速BEVDepth方法,以及多帧融合(Multi-frame Fusion)来提高目标检测效果和运动速度估计。任务级用反卷积和MLP输出语义分割网络占用或目标检测Bounding Box。
再来看小米汽车成份更高的那篇论文即《SurroundSDF: Implicit 3D Scene Understanding Based on Signed Distance Field》,这篇论文主要就是3D语义分割占用网络,因此主要指标就是mIoU。
小米汽车SurroundSDF的网络架构

图片来源:《SurroundSDF: Implicit 3D Scene Understanding Based on Signed Distance Field》论文
简单解释一下SDF,有符号距离场(SDF:Signed Distance Field) 是距离场的一种变体,它在 3D(2D) 空间中将位置映射到其到最近平面(边缘)的距离。距离场在图像处理、物理学和计算机图形学等许多研究中都有应用。在计算机图形的上下文中,距离场通常是有符号的,表示某个位置是否在网格内。无论2D或者3D图形都有隐式(implicit)和显式(explicit)两种存储方式,比如3D模型就可以用mesh直接存储模型数据,也可以用SDF、点云(point cloud)、神经网络(neural rendering)来表示,2D资产(这里指贴图)亦是如此。比如贴图一般直接使用RGB、HSV等参数来进行表示,但这样子再放大图片后会出现锯齿,所以想要获取高清的图像就需要较大的存储空间,这时候就需要矢量表示,SDF就是为了这种需求产生的,也就是雷军所说的超高分辨率矢量。这个技术是用在手机游戏中的,最典型的就是手机游戏第一名《原神》,面部阴影就是用SDF做的。
小米汽车SurroundSDF的网络架构和上一篇论文只有最后输出头有区别,骨干网、LSS和Voxel都是完全一致的。
SurroundSDF旨在解决自动驾驶系统中基于视觉的3D场景理解的挑战。具体来说,它试图解决以下问题:连续性和准确性:现有的无对象(object-free)方法在预测离散体素网格的语义时,未能构建连续且准确的障碍物表面。SurroundSDF通过隐式预测有符号距离场(Signed Distance Field, SDF)和语义场,来实现从环绕图像连续感知3D场景。
缺乏精确的SDF真实值(ground truth):由于获取精确的SDF真实值是困难的,论文提出了一种新的弱监督范式,称为Sandwich Eikonal formulation,通过在表面两侧施加正确和密集的约束来提高表面的感知精度。Eikonal方程是在处理波传播问题时需要求解的一类非线性偏微分方程。这里科普一下:Eikonal方程可以求出地震波从源点到空间任意一点的传播时间,从而描述波在介质中的传播时间场;快速求解Eikonal方程对于加速重建地震波传播时间场从而减少地震灾害对社会财产的损失具有重要意义。在图像处理领域,Eikonal方程被用于计算多个点的距离场、图像去噪,提取离散和参数化表面上的最短路径。
3D语义分割和连续3D几何重建:SurroundSDF旨在在一个框架内同时解决3D语义分割和连续3D几何重建的问题,利用SDF的强大表示能力。
长尾问题和3D场景的粗糙描述:尽管3D目标检测算法取得了进展,但长尾问题和3D场景的粗糙描述仍然是挑战,需要更深入地理解3D几何和语义。
特斯拉的AI Day上也提出了“隐式神经表示“ (Implicit Neural Representation,INR)。以图像为例,其最常见的表示方式为二维空间上的离散像素点。但在真实世界中,我们看到的世界可以认为是连续的,或者近似连续。于是,可以考虑使用一个连续函数来表示图像的真实状态,然而我们无从得知这个连续函数的准确形式,因此有人提出用神经网络来逼近这个连续函数,这就是INR,在3D图像、视频、Voxel重建中,INR函数将二维坐标映射到RGB值。对于视频,INR函数将时刻t以及图像二维坐标XY映射到RGB值。对于一个三维形状,INR函数将三维坐标XYZ映射到0或1,表示空间中的某一位置处于物体内部还是外部。INR是一个连续的函数,函数(网络)的复杂程度和信号的复杂程度成正比,但与信号的分辨率无关。比如一个16*16的图像,和一个32*32的图像,如果内容一样,那么INR就会一样。也就是再低的分辨率也可以连续扩展高分辨率的效果。
SurroundSDF使用有符号距离函数(SDF)来隐式地表示3D场景,这允许连续地描述3D场景并通过重建平滑表面来表达场景的几何结构。利用SDF约束通过Eikonal公式来准确描述障碍物的表面。这种方法可以准确地从环绕图像中感知连续的3D场景。为了减少几何优化和语义优化之间的不一致性,论文设计了一种联合监督策略。该策略使用SoftMax函数将每个体素网格的最小SDF值转换为自由概率,并将其与语义logits结合,通过Dice损失进行联合优化。
自动驾驶算法的基础部分基本上都被谷歌和META定型了,即骨干2D CNN网络加FPN,中间Transformer变换,最后任务级MLP或隐式表达。包括特斯拉在内都跳不出这个框架,没有人的算法水平会特别好,大家基本都在一个水平上,比拼的不是数据,而是投入的人力,足够的人力才能做反复的实验微调,才能略略胜出一点,能做彻底改变的只有谷歌或META抑或是微软。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。