语音识别是以语音为研究对象,通过语音信号处理和模式识别让机器自动识别和理解人类口述的语言。语音识别技术就是让机器通过识别和理解过程把语 音信号转变为相应的文本或命令的高技术。语音识别是一门涉及面很广的交叉学科,它与声学、语音学、语言学、信息理论、模式识别理论以及神经生物学等学科都 有非常密切的关系。语音识别技术正逐步成为计算机信息处理技术中的关键技术,语音技术的应用已经成为一个具有竞争性的新兴高技术产业。
1、语音识别的基本原理
语音识别系统本质上是一种模式识别系统,包括特征提取、模式匹配、参考模式库等三个基本单元,它的基本结构如下图所示:
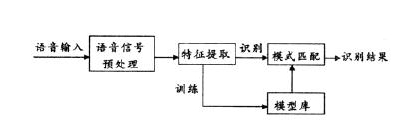
未知语音经过话筒变换成电信号后加在识别系统的输入端,首先经过预处理,再根据人的语音特点建立语音模型,对输入的语音信号进行分析,并抽取所需的特 征,在此基础上建立语音识别所需的模板。而计算机在识别过程中要根据语音识别的模型,将计算机中存放的语音模板与输入的语音信号的特征进行比较,根据一定 的搜索和匹配策略,找出一系列最优的与输入语音匹配的模板。然后根据此模板的定义,通过查表就可以给出计算机的识别结果。显然,这种最优的结果与特征的选 择、语音模型的好坏、模板是否准确都有直接的关系。
2、语音识别技术的发展历史及现状
1952年,AT&TBell实验室的Davis等人研制了第一个可十个英文数字的特定人语音增强系统一Audry系统1956年,美国普林斯 顿大学RCA实验室的Olson和Belar等人研制出能10个单音节词的系统,该系统采用带通滤波器组获得的频谱参数作为语音增强特征。1959 年,Fry和Denes等人尝试构建音素器来4个元音和9个辅音,并采用频谱分析和模式匹配进行决策。这就大大提高了语音识别的效率和准确度。从此计算机 语音识别的受到了各国科研人员的重视并开始进入语音识别的研究。60年代,苏联的Matin等提出了语音结束点的端点检测,使语音识别水平明显上 升;Vintsyuk提出了动态编程,这一提法在以后的识别中不可或缺。60年代末、70年代初的重要成果是提出了信号线性预测编码(LPC)技术和动态 时间规整(DTW)技术,有效地解决了语音信号的特征提取和不等长语音匹配问题;同时提出了矢量量化(VQ)和隐马尔可夫模型(HMM)理论。语音识别技 术与语音合成技术结合使人们能够摆脱键盘的束缚,取而代之的是以语音输入这样便于使用的、自然的、人性化的输入方式,它正逐步成为信息技术中人机接口的关 键技术。
3、语音识别的方法
目前具有代表性的语音识别方法主要有动态时间规整技术(DTW)、隐马尔可夫模型(HMM)、矢量量化(VQ)、人工神经网络(ANN)、支持向量机(SVM)等方法。
动态时间规整算法(Dynamic Time Warping,DTW)是在非特定人语音识别中一种简单有效的方法,该算法基于动态规划的思想,解决了发音长短不一的模板匹配问题,是语音识别技术中出 现较早、较常用的一种算法。在应用DTW算法进行语音识别时,就是将已经预处理和分帧过的语音测试信号和参考语音模板进行比较以获取他们之间的相似度,按 照某种距离测度得出两模板间的相似程度并选择最佳路径。
隐马尔可夫模型(HMM)是语音信号处理中的一种统计模型,是由Markov链 演变来的,所以它是基于参数模型的统计识别方法。由于其模式库是通过反复训练形成的与训练输出信号吻合概率最大的最佳模型参数而不是预先储存好的模式样 本,且其识别过程中运用待识别语音序列与HMM参数之间的似然概率达到最大值所对应的最佳状态序列作为识别输出,因此是较理想的语音识别模型。
矢量量化(Vector Quantization)是一种重要的信号压缩方法。与HMM相比,矢量量化主要适用于小词汇量、孤立词的语音识别中。其过程是将若干个语音信号波形或 特征参数的标量数据组成一个矢量在多维空间进行整体量化。把矢量空间分成若干个小区域,每个小区域寻找一个代表矢量,量化时落入小区域的矢量就用这个代表 矢量代替。矢量量化器的设计就是从大量信号样本中训练出好的码书,从实际效果出发寻找到好的失真测度定义公式,设计出最佳的矢量量化系统,用最少的搜索和 计算失真的运算量实现最大可能的平均信噪比。
在实际的应用过程中,人们还研究了多种降低复杂度的方法,包括无记忆的矢量量化、有记忆的矢量量化和模糊矢量量化方法。
人工神经网络(ANN)是20世纪80年代末期提出的一种新的语音识别方法。其本质上是一个自适应非线性动力学系统,模拟了人类神经活动的原理,具有自 适应性、并行性、鲁棒性、容错性和学习特性,其强大的分类能力和输入—输出映射能力在语音识别中都很有吸引力。其方法是模拟人脑思维机制的工程模型,它与 HMM正好相反,其分类决策能力和对不确定信息的描述能力得到举世公认,但它对动态时间信号的描述能力尚不尽如人意,通常MLP分类器只能解决静态模式分 类问题,并不涉及时间序列的处理。尽管学者们提出了许多含反馈的结构,但它们仍不足以刻画诸如语音信号这种时间序列的动态特性。由于ANN不能很好地描述 语音信号的时间动态特性,所以常把ANN与传统识别方法结合,分别利用各自优点来进行语音识别而克服HMM和ANN各自的缺点。近年来结合神经网络和隐含 马尔可夫模型的识别算法研究取得了显著进展,其识别率已经接近隐含马尔可夫模型的识别系统,进一步提高了语音识别的鲁棒性和准确率。
支 持向量机(Support vector machine)是应用统计学理论的一种新的学习机模型,采用结构风险最小化原理(Structural Risk Minimization,SRM),有效克服了传统经验风险最小化方法的缺点。兼顾训练误差和泛化能力,在解决小样本、非线性及高维模式识别方面有许多 优越的性能,已经被广泛地应用到模式识别领域。
4、语音识别系统的分类
语音识别 系统可以根据对输入语音的限制加以分类。如果从说话者与识别系统的相关性考虑,可以将识别系统分为三类:(1)特定人语音识别系统。仅考虑对于专人的话音 进行识别。(2)非特定人语音系统。识别的语音与人无关,通常要用大量不同人的语音数据库对识别系统进行学习。(3)多人的识别系统。通常能识别一组人的 语音,或者成为特定组语音识别系统,该系统仅要求对要识别的那组人的语音进行训练。
如果从说话的方式考虑,也可以将识别系统分为三类: (1)孤立词语音识别系统。孤立词识别系统要求输入每个词后要停顿。(2)连接词语音识别系统。连接词输入系统要求对每个词都清楚发音,一些连音现象开始 出现。(3)连续语音识别系统。连续语音输入是自然流利的连续语音输入,大量连音和变音会出现。
如果从识别系统的词汇量大小考虑,也可 以将识别系统分为三类:(1)小词汇量语音识别系统。通常包括几十个词的语音识别系统。(2)中等词汇量的语音识别系统。通常包括几百个词到上千个词的识 别系统。(3)大词汇量语音识别系统。通常包括几千到几万个词的语音识别系统。随着计算机与数字信号处理器运算能力以及识别系统精度的提高,识别系统根据 词汇量大小进行分类也不断进行变化。目前是中等词汇量的识别系统,将来可能就是小词汇量的语音识别系统。这些不同的限制也确定了语音识别系统的困难度。
5、语音识别的应用
语音识别可以应用的领域大致分为大五类:
办公室或商务系统。典型的应用包括:填写数据表格、数据库管理和控制、键盘功能增强等等。
制造业:在质量控制中,语音识别系统可以为制造过程提供一种“不用手”、“不用眼”的检控(部件检查)。
电信:相当广泛的一类应用在拨号电话系统上都是可行的,包括话务员协助服务的自动化、国际国内远程电子商务、语音呼叫分配、语音拨号、分类订货。
医疗:这方面的主要应用是由声音来生成和编辑专业的医疗报告。
其他:包括由语音控制和操作的游戏和玩具、帮助残疾人的语音识别系统、车辆行驶中一些非关键功能的语音控制,如车载交通路况控制系统、音响系统。
未来随着手持设备的小型化,甚至穿戴化,各种智能眼镜,手表等层出不穷,当然找准市场突破口很重要,好的解决方案和系统设计参考也是必不可少的。
Nuance语音识别技术及解决方案
1.语音识别概述
语音识别技术,Automatic Speech Recognition,简称ASR,是一种让机器听懂人类语言的技术。语言是人类进行信息交流的最主要、最长用、最直接的方式。语音识别技术是实现人机 对话的一项重大突破,在国外近年来发展十分迅速,其应用也逐步得到推广。近几年逐渐普及的IVR(自动电话应答)处理了不少简单而又重复的咨询工作,节省 了不少人力,但这种按键式的语音自动应答却让客户花费很多时间按指引来完成简单的查询,令用户倍感不便。
语音识别无疑可以解决该方面的问题。语音识别系统的开发成功,充分发挥了计算机技术和网络技术的优势,采用先进的人机对话方式,摆脱电话按键的束缚,人们只要象平常一样对着电话简单的说出所需服务项目,即可轻松获取自动系统提供的所需信息。
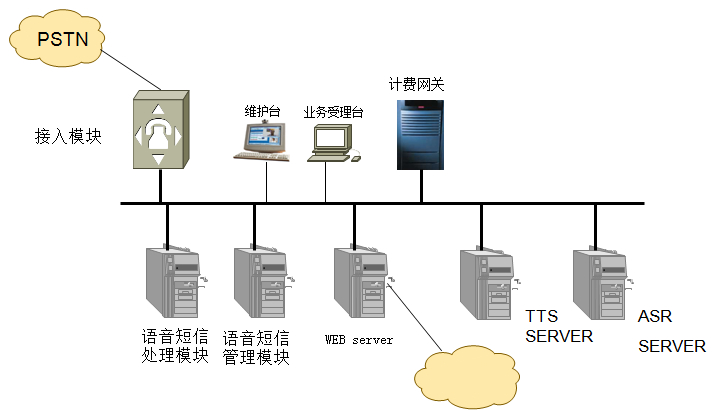
语音识别系统结构
2.语音识别应用
Nuance公司是自然语音接口软件的佼佼者。使用自然语音接口软件,人们可以通过电话方便安全地获取信息、服务并进行交易。每天,千千万万的人通过拨 打运行Nuance公司语音识别、语言理解和声纹鉴别软件的电话,进行出游预订、股票交易、与其它通讯媒体、企业和互联网系统进行交往等活动。 NUANCE的应用:美国航空、Bell Atlantic、Charles Schwab、家庭购物网络、Lloyds TSB、Sears、UPS 。
3.NUANCE语音识别特点
(1)海量词汇、独立于讲话者的健壮识别功能
Nuance系统能可靠地对多种语言进行大词汇量的识别,并可提供识别结果的置信度。该系统对商业上使用的大量词汇提供最准确的语音识别技术。利用Nuance系统开发的应用程序,在市场上具有最高的准确率。生产中的应用程序经测试,准确性超过96%。
(2)基于主机的客户/服务机结构
Nuance系统基于开放式客户/服务机结构,特别为大型应用程序所需的健壮性和可伸缩性而设计。呼叫者的讲话由客户端收集,而识别和鉴别处理的负载被平均分配到网络上的多个分开的服务器上。
(3)N-Best处理
对于有些应用程序,可能需要识别引擎产生可能的识别结果集,而不是一个最好的结果。Nuance系统的N-best识别处理方法便有这个功能,它提供了可能的识别结果列表,并按可能性从高到低排列。
(4)语法概率
Nuance系统允许对呼叫者所讲的特定词语或短语的在语法中的概率进行指定。当被讲的词语或短语的概率可根据实际使用进行估计时,非常有用。对语法增加概率可提高识别的准确率和速度。
(5)降低噪音
当进来的呼叫包含稳定的背景噪音时,Nuance系统通过一种机制,使识别服务器更准确地进行识别。识别服务器将进来的话语进行增强,以有效地将语气、 嗡嗡声、哼叫声、嘘嘘声等噪声过滤。如果相当数量的电话均含有稳定的背景噪声,比如在汽车上免提打电话时,这个机制效果较理想。
4.基于识别的应用
语音短信本身业务、公司电话簿、个人电话簿、智能点歌、股票查询和交易、智能信息点播、列车时刻查询
(1)基于语音识别的公司电话簿
公司电话薄应用描述
系统能支持多个接入号码,虚拟多个公司的总机。并依靠语音识别技术,智能转接到相应的用户。
流程
用户拨打接入码,系统根据接入码找到相应的公司数据库,同时提醒用户说出相应的用户,系统依据相应的用户查询数据库,并得到该用户的号码,并通知交换机将该号码接通。
公司电话簿特点
•系统支持电话接入方式
用户可通过电话修改个人密码,个人上班电话和非上班电话
•系统支持WEB接入方式
• 系统管理员可修改所有信息
• 各公司管理员可增加,删除,修改本公司的电话信息
(2)基于语音识别的点歌功能
功能描述
用户接入系统,提示用户说出歌名,并依靠语音识别技术,查找到该歌名,并播放给用户。
应用流程
用户拨打接入码,提示用户说出歌名或歌手名,并依靠语音识别技术,查找到该歌名或歌手名,若为歌名查询数据库,得到该歌存储的路径,并播放给用户,若为 歌手名,则读出该歌手的专辑,并提醒用户选择,用户选择后,读出该专辑的歌名,并提醒用户选择,用户选择后,给用户播放该歌曲。
基于ZigBee节点的智能家居系统语音控制设计
1 系统总体设计
系统总体结构如图1所示,主要包括基于Samsung的S3C6410平台的网关、基于SPCE061A的语音ZigBee子节点、电器继电器控制ZigBee子节点、电器红外控制ZigBee子节点等。其中各子节点与网关之间通过星型拓扑结构进行连接。

在对语音子节点进行训练之后,当语音节点采集接收到语音控制命令时,执行语音识别指令,通过CC2530收发模块发送相应的控制指令到网关的主节点上。 主节点将接收到控制指令通过串口上传到网关主机,主机在处理信息之后,再通过主节点发送相应的控制指令到控制子节点上,控制子节点在接收到相应的命令之后 就会执行相应的动作,对被控对象进行控制。
2 系统硬件设计
(1)网关。采用基于ARM11架构的三星S3C6410处理器,与ZigBee主节点之间通过串口方式进行通信。S3C6410是基于ARM1176JZF-S的16/
(2)语音子节点。由凌阳科技的SPCE061A单片机与ZigBec收发节点模块组成。SPCE061A是凌 阳科技推出的以μ’nSPTM为核心的16位结构的微控制器。具有8通道10位A/D转换输入功能,内置自动增益控制功能的麦克风输入方式以及双通道10 位DAC方式的音频输出功能。在使用SAC M_S240凌阳音频编码方式时,可以容纳长达210 s的语音数据。因此被广泛应用于数字语音识别领域中。
(3)电器控制继电器子节点。由继电器模块与ZigBee收发节点组成。由于我国市电电压在220 V左右,为了实现对部分家电开关的控制,采用继电器模块,并通过ZigBee通信模块的CC2530芯片的I/O引脚及其外围驱动电路,实现对继电器模块 的吸合与释放控制。可以控制窗帘、灯光等开关型电器。
(4)红外控制子节点。由学习型红外控制模块与ZigBee收发子节点组成。目 前,红外遥控类型的家用电器的比例正逐步攀升。因此本文在设计研究中采用了学习型的红外控制模块,它与ZigBee收发子节点之间通过串口进行通信。首先 使用一个或多个红外模块对现有的家电(如电视机、DVD、空调、投影仪等)红外遥控器的信号进行学习,把相应的编码存放到红外模块的存储器E2PROM 中,每条代码对应一个地址。当该
(5)基于CC2530的ZigBee无线收发模块。CC2530是TI公司推出的基于IEEE 802.15.4协议的片上系统。内嵌增强型单周期的8051CPU,具有8 KB的SRAM、2个支持多种串行通信协议的USART、21个通用的I/O引脚、宽电压范围(2~3.6 V)、低功耗(主动模式RX:24 mA;主动模式TX在1 dBm:29 mA)以及电源电量可监控等特点。在ZigBee协议栈中UART具有中断、DMA两种模式,本文设计中均采用了UART的中断模式。
3 系统软件设计
系统软件设计主要包括下位机软件与上位机软件设计。在下位机程序设计过程中有2个关键点:对数字语音信号的采集、处理与识别;ZigBee收发模块对控制信号的接收、发送与执行。而在上位机软件设计中,主要是基于Visual C++的串口通信的编程。
上位机主程序流程图如图2所示。
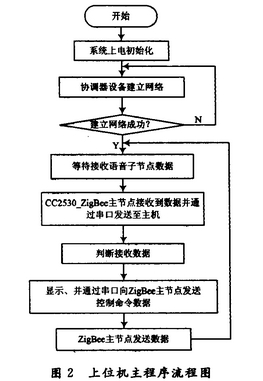
S3C6410开发平台具有4个UART接口,在研究设计中,采用了芯片MAX 3232来解决ZigBee通信模块的CC2530芯片与该开发平台之间的串口通信电平转换。上位机通过串口接收语音子节点的控制指令数据,将数据处理后 用文字显示控制命令,并通过与ZigBee主节点之间的串口通信,向子节点发送控制指令数据。
4 实验及结果
4.1 实际应用举例
在对电动窗帘进行开关控制时,首先将本系统的电器控制继电器子节点与电动窗帘的开关量电机控制器相连接,准备好硬件电路。然后,通过串口编程使上位机的 ZigBee主节点在接收到语音子节点的窗帘开关命令时,向ZigBee子节点发射窗帘控制信号,从而当控制窗帘的继电器子节点接收到控制指令时,能够控 制窗帘执行相应的开关动作。通过如依次说出“控制器”、“打开”、“窗帘”的命令时,语音子节点语音提示设备打开,主机界面显示设备所处控制的状态,同时 窗帘打开。
该语音控制智能家居系统能够实现家用电器的联动。例如,可以通过依次说出“控制器”、“家庭影院”的语音命令。这时上位机能够按照程序设定逐步延时:打开红外遥控投影仪,红外遥控幕帘,关闭窗帘,关闭部分灯光等来开启家庭影院模式。让人们体验真正的家居智能化。
4.2 ZigBee控制节点通信距离测试结果
(1)空旷场合测试。测试条件:CC2530模块采用PCB天线,发射功率在1 mW,发射频率在2.4 GHz。测试结果:通信距离最远可达120 m。
(2)居家场合测试测试条件:同上。测试结果:由于墙体阻碍,通信距离约在20 m。
4.3 语音控制红外型电视开关测试
在语音识别程序设计中,为了增加语音节点所能识别命令的条数而采用了分组法。利用红外遥控子节点对电视遥控器的开/关信号进行学习,对语音子节点进行训 练结束后,启动系统。依次说出“控制器”、“打开”、“电视”连续三条命令,再说出“控制器”、“关闭” “电视”连续三条命令。测试结果如表1所示。

5 结语
将具有数字语音识别功能的SPCE061A单片机与低功耗、低成本的ZigBee技术相结合,开发了基于单芯片CC2530的ZigBee语音节点,并 利用ARM11架构的开发平台S3C6410作为网关,WinCE 6.0的操作系统,有着良好的人机交互界面,来共同应用于智能家居系统的语音控制中,实现了对开关型及红外型家电设备的语音控制和家居智能化,实现人与家 电之间的对话,方便了人们的生活,具有广阔的应用前景。
设计详情:基于ZigBee节点的智能家居系统语音控制设计
实时语音识别系统在家庭监护机器人的实现
文中阐述的是家庭监护机器人项目中语音识别系统设计的部分,通过DSP、 DMA和ARM Cortex-A8的并行处理,利用双缓冲的方法,在嵌入式Linux上实现了基于ATK的实时语音识别系统。文中对该系统的软硬件进行了设计。在硬件方 面,给出语音识别系统的硬件组成原理,并提供了关键部分原理图;在软件方面,提出实时语音识别的方法,给出应用程序实现流程。最后通过真人说话来进行语音 识别实验,实时语音识别率达到了94.67%以上,实验验证了系统的软件硬件设计的正确性。
1 系统设计
文中是家庭监护机器人项目中的语音识别系统设计部分,设计目的是设计出一种可以识别语音的、协助监护家庭行动不方便人员的机器人。为实现该语音识别系统,设计了语音识别系统总体结构框图,如图1所示。
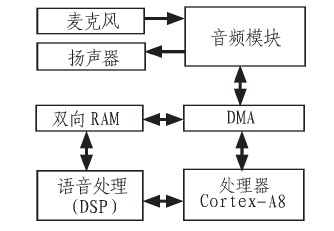
图1 系统总体结构框图
1.1 硬件设计
文中所研究和设计的功能,都是应用在移动机器人上的。因而系统的研究设计需要考虑到体积小、省电、便于移动的特性,并需具有便于家庭用户操作的友好显示 界面。对于语音识别部分,需要用到用于语音识别算法处理的处理器、语音采集电路和语音输出电路,如图 2所示。其中语音识别算法运算的处理器主要负责算法的运算处理,相当于机器人的大脑;语音采集电路负责采集外部的声音信号,相当于机器人的耳朵;语音输出 电路负责输出话语声音,相当于机器人的嘴巴。
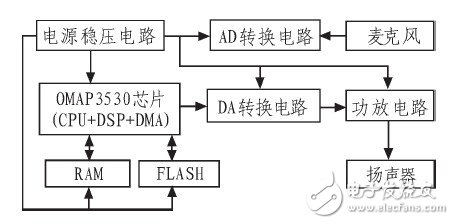
图2 系统硬件结构图
1.2 软件设计
HTK(Hidden Markov Model Toolkit)是一套专门的建立和处理隐马可夫模型(HMMs)的实验工具包,由英国剑桥大学工程系(Cambridge University Engineering Department,CUED)开发的,主要应用于语音识别领域,也可以应用于语音合成、字符识别和DNA排序等研究领域。HTK经过剑桥大学、 Entropic公司及Microsoft公司的不断增强和改进,使其在语音识别领域处于世界领先水平。
基于HTK的语言识别时,识别 结果适用只能显示在DOS或终端上,而且不利于将结果保存、移植或者二次开发利用。在本语音识别系统中使用了HTK接口工具 ATK(AnApplication Toolkit for HTK)。ATK是由英国剑桥大学开发的开源语音识别工具,是对HTK的C++多线程封装,跟HTK一样,它支持Linux和Windows,它包括 HTK(HTKLib)、AHTK、AGram、ANGram、ADict、AHMMs、AResource、ARMan、ARec、ACode、 ASour ce、ATee、AComponent、ABuffer、APacket、Asyn、FLite(SYNLib)、ALog模块部件。
基于ATK的语音识别软件应用系统的由语音信号采集模块、基于DMA的双向高速RAM存取模块、ATK语音识别模块、系统管理模块、语音输出模块等模块组成,如图4所示。
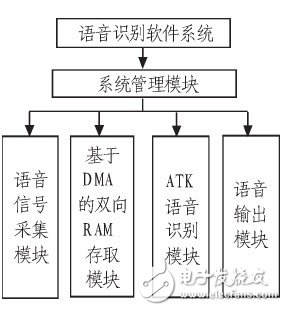
图4 系统软件设计结构图
在软件设计中,系统管理模块主要负责系统的总体管理调度,是应用系统的调度中心;语音信号采集模块主要负责控制数据采集芯片TPS 65930;基于DMA的双向RAM存取模块主要负责实现DMA驱动及双向RAM的读写存取,使用了通道1来实现高速地把语音信号采集到的数据存储到 RAM上,并使用通道2实现高速地把RAM的数据取出来,用于语音的识别;语音输出模块主要负责把相应的音频数据送到TPS65930,并控制TPS6 5930对接收到的音频解码输出到功放电路,实现语音输出的功能。软件的设计流程图如图5所示。
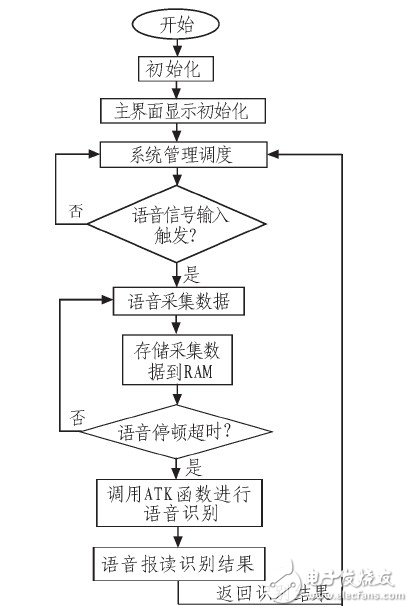
图5 软件设计流程
2 语音识别系统实验及结果
文中设计的语音识别系统如图6所示。在实验中总共进行了3轮话语测试,每轮300句话语测试,其中 150句为家庭监护机器人需要识别的话语,150句话语为机器人不予置理的无关话语。从实验测试结果可看出,对于识别10个需要识别的话语的识别率高达94.67%以上,具有较高的识别率,因而该语音识别系统较好达到了家庭监护机器人使用的要求。
3 结论
文中通过DSP、DMA和ARM Cortex-A8的并行处理,利用双缓冲的方法,在嵌入式Linux上实现了基于ATK的实时语音识别系统。该系统可以实时地实现语音识别,具有较高识别率,较快的响应速度。可以应用在家庭监护机器人及其相关领域中。
设计详情:实时语音识别系统在家庭监护机器人的实现
基于语音识别的汽车空调控制系统设计
现在汽车上使用的电器越来越多,驾驶员需要手动操作的电器开关也越来越多, 不但增加了驾驶员的负担,还影响了行车安全。本文以 STM32F103VET6(以下简称STM32)芯片为控制核心,采用高性能LD3320语音识别芯片,设计基于语音识别的汽车空调控制系统。该系统可 以用语音有效控制汽车空调,减轻了驾驶员的操作负担,保证行车过程中的安全。
1 系统硬件设计
运用语音识别技术,结合各种传感器对车身内外的环境(如气温、阳光强度等)以及制冷压缩机的状态等多种参数进行实时检测,与设定参数相比较,微控制器经 过运算处理做出判断,输出相应的调节和控制信号。执行机构经过实时调整和修正,实现对车厢内空气环境全方位、多功能的调节和控制。系统的执行机构主要包括 温度风门电机、模式风门电机、循环风门电机、鼓风机、压缩机、除霜控制继电器等。图1为系统结构框图。

1.1 主控制器
主控制器为基于ARM Cortex—M3内核的32位微控制器STM32F103VET6,内置64 KB RAM、512 KBFlash,以及丰富的增强I/O端口和联接到两条APB总线的外设,主要控制传感器模拟信号的采集、语音信号的收发和汽车空调控制信号的输出。
1.2 语音识别模块