






 技术咨询
技术咨询 代买器件
代买器件 商务客服
商务客服 研发客服
研发客服
引言

MV3D[1]使用的BEV视角特征
BEV方案的一大好处是可以直接套用成熟的2D检测器,但也有一个很致命的缺点:它限制住了感知范围。从上图可以看到,因为要套2D检测器,它必须形成一个2D的feature map,此时就必须给它设置一个距离阈值,而在上图范围之外其实也还是有LiDAR点的,只是被这个截断操作给丢弃了。那可不可以把这个距离阈值拉大,直到包住所有点呢?硬要这么做也不是不行,只是LiDAR在扫描模式、反射强度(随距离呈4次方衰减)、遮挡等问题作用下,远处的点云是非常少的,这么做很不划算。
BEV方案的这个问题在学术界并没有引起关注,这主要是数据集的问题,主流数据集的标注范围通常只有不到80m(nuScenes 50m、KITTI 70m,Waymo 80m),在这个距离下BEV feature map并不需要很大。但工业界使用的中距离LiDAR普遍已经可以做到200m的扫描范围,而近几年也有几款远距离LiDAR问世,它们可以做到500m的扫描范围。注意到feature map的面积和计算量是随距离呈二次方增长的,在BEV方案下,200m的计算量几乎都无法承受,更不用说500m了。

在认识到BEV方案的局限之后,我们进行了多年的研究,最终才找到了可行的替代方案。研究过程并非一帆风顺,经历了很多次挫折,论文和报告中一般都只会讲成功而不会说失败,但失败的经验也是弥足珍贵的,所以博客反而成了更好的媒介,下面就按时间线依次讲述一下。
Point-based方案
CVPR19上,港中文发表了一篇Point-based检测器PointRCNN[2],它是直接在点云上进行计算的,点云扫到哪它算到哪,没有拍BEV的过程,所以这类point-based方案理论上是可以做到远距离感知的。
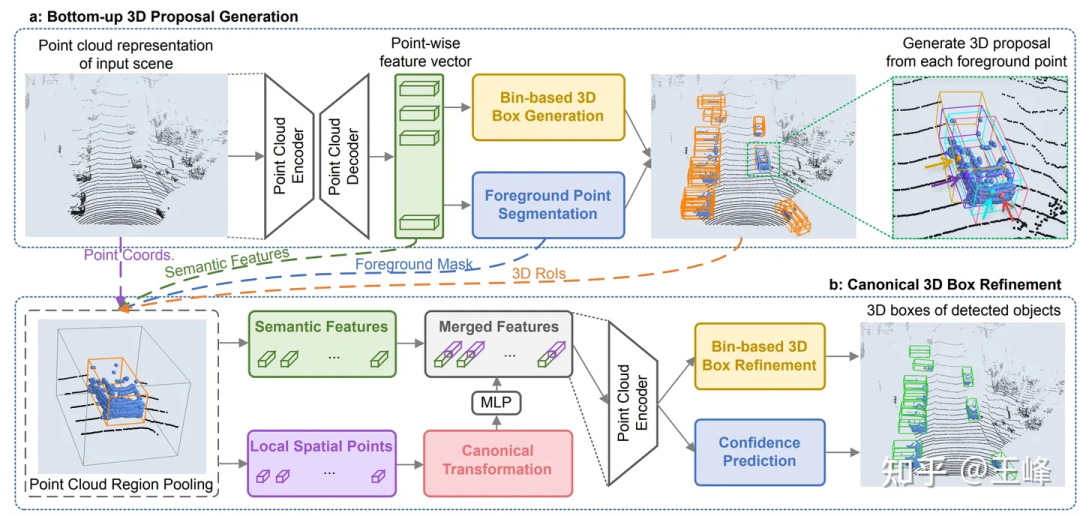
不过这段研究也并没有浪费,虽然backbone计算量过大,但它的二阶段因为只在前景上进行,所以计算量还是比较小的。把PointRCNN的二阶段直接套用在BEV方案的一阶段检测器之后,检测框的准确度会有一个比较大的提升。

Range-View方案

在Range View下,点云不再是稀疏的形式而是致密地排列在一起,远距离的目标在range image上只是比较小,但并不会被丢掉,所以理论上也是能检测到的。
可能是因为与图像更相似,对于RV的研究其实比BEV还早,我能找到的最早记录也是来自于百度的论文[4],百度真的是自动驾驶的黄埔军校啊,不论是RV还是BEV的最早应用都来自于百度。
于是当时我就随手试了一把,结果跟BEV方法相比,RV的AP狂掉30-40个点...我发现其实在2d的range image上检测得还可以,但输出出来的3d框效果就非常差了。当时分析RV的特性,感觉它具备图像的所有劣势:物体尺度不统一、前背景特征混杂、远距离目标特征不明显,但又不具备图像语义特征丰富的优势,所以当时对这个方案比较悲观。
因为正式员工毕竟还是要做落地的工作,对于这种探索性问题还是交给实习生比较好。后来招了两名实习生一起来研究这个问题,在公开数据集上一试,果然也是掉了30个点...还好两位实习生比较给力,通过一系列的努力,还有参考其他论文修正了一些细节之后,将点数刷到了跟主流BEV方法差不多的水平,最终论文发表在了ICCV21上[5]。
虽然点数刷上来了,但问题并没有被彻底解决,当时lidar需要多帧融合来提高信噪比的做法已经成为共识,远距离目标因为点数少,更加需要叠帧来增加信息量。在BEV方案里,多帧融合非常简单,直接在输入点云上加上一个时间戳然后多帧叠加起来,整个网路都不用改动就可以涨点,但在RV下变换了很多花样都没有得到类似的效果。
并且在这个时候,LiDAR从硬件的技术方案上也从机械旋转式走向了固态/半固态的方式,大部分固态/半固态的LiDAR不再能够形成range image,强行构造range image会损失信息,所以这条路径最终也是被放弃了。

Sparse Voxel方案
因为SECOND[6]的作者闫岩加入了图森,所以我们在早期就曾经尝试过sparse conv的backbone,但因为spconv并不是一个标准的op,自己实现出来的spconv仍然过慢,不足以实时进行检测,有时甚至慢于dense conv,所以就暂时搁置了。
后来第一款能扫描500m的LiDAR:Livox Tele15到货,远距离LiDAR感知算法迫在眉睫,尝试了一下BEV的方案实在是代价太高,就又把spconv的方案拿出来试了一下,因为Tele15的fov比较窄,而且在远处的点云也非常稀疏,所以spconv勉强是可以做到实时的。
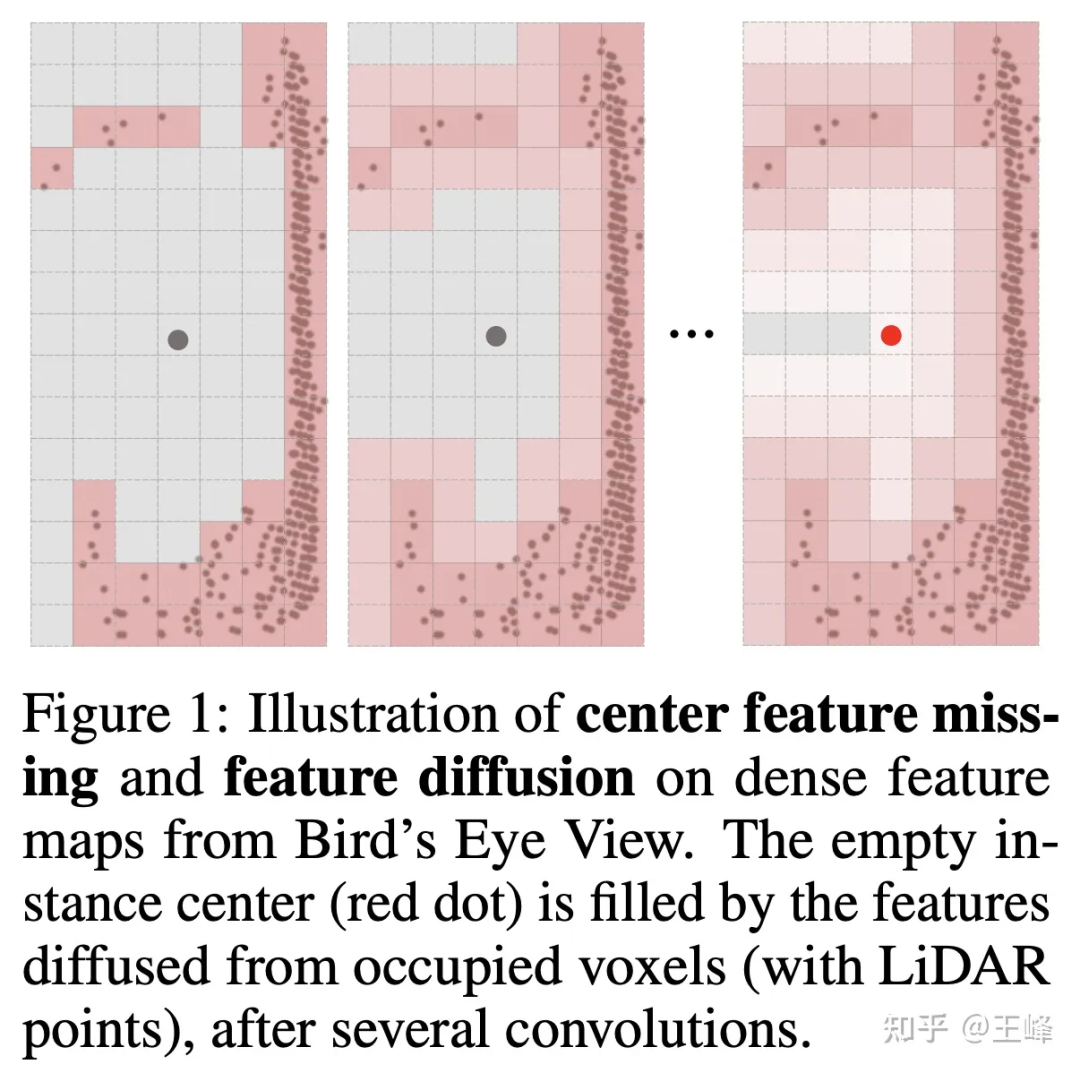
但不拍bev的话,检测头这块就不能用2D检测中比较成熟的anchor或者center assign了,这主要是因为lidar扫描的是物体的表面,中心位置并不一定有点(如下图所示),没有点自然也无法assign上前景目标。其实我们在内部尝试了很多种assign方式,这里就不细讲公司实际使用的方式了。
可惜的是,这个方法在公司数据集上一直刷不过BEV类方法,差了接近5个点的样子,现在回想起来可能还是有一些trick或者训练技巧没有掌握,按理说Transformer的表达能力是不弱于conv的,但后来也并没有再继续尝试。不过这个时候已经对assign方式进行了优化降低了很多计算量,所以就想再尝试一把spconv,结果令人惊喜的是,直接把Transformer替换为spconv就可以做到近距离与BEV类方法的精度相当,同时还能检测远距离目标的效果了。
也是在这个时候,闫岩同学做出了第二版spconv[9],速度有了大幅度提升,所以计算延迟不再是瓶颈,终于远距离的LiDAR感知扫清了所有障碍,能够在车上实时地跑起来了。
下面展示一下最终的远距离检测效果,大家也可以看看图森ai day的视频的01:08:30左右的位置看一下动态的检测效果:

虽然是最终的融合结果,但因为这天起雾图像能见度很低,所以结果基本上都来自于LiDAR感知。

后记
很长时间不写这么长的文章了,写得跟个流水账似的而没有形成一个动听的故事。近年来,坚持做L4的同行越来越少,L2的同行们也逐渐转向纯视觉的研究,LiDAR感知肉眼可见地逐步被边缘化,虽然我仍然坚信多一种直接测距的传感器是更好的选择,但业内人士似乎越来越不这么认为。看着新鲜血液们的简历上越来越多的BEV、Occupancy,不知道LiDAR感知还能再坚持多久。
参考资料与文献
【0】图森ai day视频:乘大势,驭未来——图森未来首届AI Day完整回放_哔哩哔哩_bilibili
【1】 Multi-View 3D Object Detection Network for Autonomous Driving
【2】PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud
【3】LiDAR R-CNN: An Efficient and Universal 3D Object Detector
【4】Vehicle Detection from 3D Lidar Using Fully Convolutional Network
【5】RangeDet:In Defense of Range View for LiDAR-based 3D Object Detection
【6】SECOND: Sparsely Embedded Convolutional Detection
【7】Fully Sparse 3D Object Detection
【8】Embracing Single Stride 3D Object Detector with Sparse Transformer
【9】GitHub - traveller59/spconv: Spatial Sparse Convolution Library