STM32 IAR 优化选项介绍
这篇文章给大家介绍一下STM32 IAR优化选项的设置
IAR优化选项包括:无优化、低等级优化、中等优化、高等优化。


公共子表达式压缩
公共子表达式压缩是较为常见的优化方式,这种方式既可以较少代码的大小,也可以缩短运行的时间,编译器可能会根据代码上下文产生更加复杂的优化结果,比如对数组或矩阵进行访问时,需要的数组索引计算,有的时候代码中可能会使用大量的宏,虽然在代码中比较简洁,但也可能在代码中产生很多重复计算,编译器使用这种优化也会有很好的结果。
在公共子表达式压缩优化中,不仅会使用寄存器,也有可能会使用在内存中的临时变量,但是因为部分代码的执行被优化,所以优化后的代码可能会比较难进行调试。

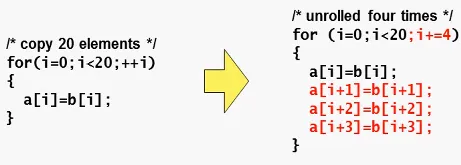
循环展开
循环展开是在编译时已确定需要循环的次数,将循环体展开,来降低每次循环循环体外的运算开销。
这种优化适用于小循环,因为小循环的循环体外运行开销比重比较大,降低循环次数会明显提高整体的执行效率。显然,这种循环的展开会增加代码的大小,但是编译器会多次进行试探性编译,然后计算编译后代码的执行速度和大小,并根据用户的选择来决定如何进行优化。同样,优化后的代码与原来的代码有很大的不同,也会造成调试上的困难。
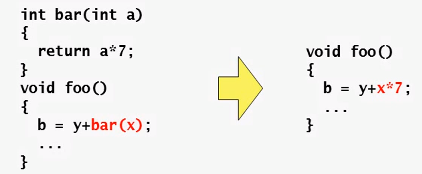
函数内联
函数内联可以减少函数调用时产生的运行开销,缩短执行时间,但可能会增加代码的大小,一般情况下,选择代码量优先时使用该优化不会增加代码的大小。
是否进行函数内联优化取决于编译器进行的试探性编译。
同样,优化后的代码可能比较难进行调试。
循环不变量外提
在许多循环中,通常有一些表达式或运算的结果在循环中是不会改变的,那么这部分内容可以将其转移到循环外部,就可以节省许多循环的工作量。
这种优化通常既可以节省代码空间,也可以提高运行的效率,但同样会导致优化后的代码比较难进行调试。

基于类型的别名分析
当两个或者更多的指针访问同一个地址时,其中任意一个变量或者指针就称为其他变量或者指针的别名变量。
如果程序中存在别名变量,会使程序优化变得非常困难,因为在编译时不可能知道一个指定地址上的数据是否被改变了。
基于别名分析的优化,假设所有访问都是基于被访问对象所声明的类型,这样可以由编译器来判断是否有多个指针访问了同一块存储区。
对于标准C或者C++程序,这种优化可以减少代码的大小,降低执行时间。
对于非标准的C或者C++程序,可能会导致生成错误的代码。
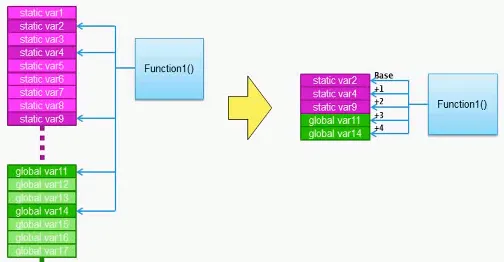
静态变量重组
一般情况下,全局和静态变量的位置是根据编译器编译的先后次序进行分配。使用静态变量重组优化后,同一模块中的静态和全局变量会被重新组织,尽量靠近在一起,这样编译器就可以使用同一个机制来访问多个变量。
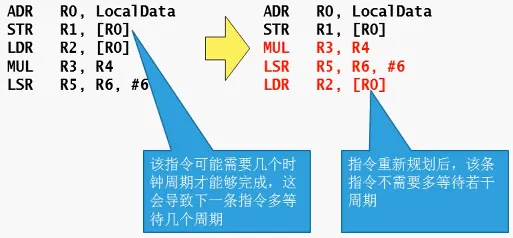
指令规划
合理的汇编指令规划能够有效发挥处理器的处理能力,能够将资源访问冲突导致的流水线等待降到最低。
其他代码优化

优化选项调整的次序:从低级到高级,从部分到全局。
在程序设计中,如果对个别等级的函数需要进行精确的优化调整,可以使用预处理命令,单独定制函数的优化选项。
有些时候在进行读写共享变量、读写外设寄存器端口或者运行存在副作用的其他操作时,不希望编译器进行调整运算或赋值次序、删除认为没有作用的代码、将变量分配在通用寄存器里等等这些优化操作,那么可以使用volatile对所要操作的对象进行声明。
一般可以在以下情况使用volatile
对象的值会在编译器不知道的情况下发生改变,例如外设寄存器的值发生改变;
程序进行的操作具有副作用,例如连续读或写某外设寄存器两次,硬件上具有特定的意义;
有多个程序共享被操作的对象,例如操作系统中的多个任务,主程序和中断服务程序。
使用volatile后,被声明的变量不会被分配在通用寄存器中,程序对这些变量的访问次序也不会被编译器改变,对变量的访问不会被删除。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。