






 技术咨询
技术咨询 代买器件
代买器件 商务客服
商务客服 研发客服
研发客服|底层智能驾驶芯片成为国内竞争焦点
汽车智能化的趋势日益明显,底层智能驾驶芯片成为国内公司竞争的焦点。成立于2022年1月的奕行智能定位于汽车AI计算芯片公司,其核心团队拥有多年的车载芯片和AI行业经验,现已经完成了累计数亿元的融资。目前其产品主要聚焦于智能汽车的AI场景。今年奕行智能计划推出两款基于AI计算架构的端侧算力产品,明年将计划推出更大规模的大算力芯片产品。
刘珲指出,智能汽车对应的AI应用场景非常丰富,而智能驾驶又是车上AI应用场景中对模型泛化和通用性要求最高。在智驾领域里能够把通用做好的产品除英伟达以外并不多,因此围绕通用性这个需求特点智驾芯片的市场机遇还是比较大的。智驾场景从当前辅助驾驶阶段,到正在落地的开放道路的部分自动驾驶,再到更远未来全局智能交通系统驱动的高阶无人驾驶。在一次次重构中,不仅革新人们的出行方式,更是在推动底层的软硬件迭代和重构。
比如在智驾领域的算法从过去基于CNN算法的多个不同任务的感知的网络向以Transformer为基础框架的BEV大模型演进。在特斯拉证明BEV的可行并成功量产后,BEV技术正被各大车厂作为今明两年重大落地的新一代算法模型。然而BEV作为新一代自动驾驶感知算法,在传统AI加速芯片部署上会存在一定难度。“Transformer的算法特点让过去围绕CNN模型定制的AI芯片很难高效部署”,Transformer模型对访存要求相对传统CNN算法会高出很多,同时Transformer内的非线性层有非常高的精度要求,相应需要更多的浮点计算资源。其次Attention模块是一个matmul-softmax-matmul的结构,在序列长度比较大时,Reduce维度的计算对Vector(向量)计算资源要求非常多。此外BEV模型里Grid Sample算法里还有一些类似聚合、分散的特殊算子。所有这些计算需求在传统的AI芯片在硬件上难以满足,使得对于BEV这种复杂的大模型部署难以高性价比的方式量产落地。
刘珲还提到另一个挑战,作为一个端侧设备,车载芯片的成本和功耗都是有约束的,怎么在算力红线下,提高NPU的硬件效率和可编程性显得尤为重要。从提高效率层面需要NPU硬件与编译器协同设计,通过更好的优化和部署计算任务来更高效地填满硬件,从而提升硬件的利用率,同时还要考虑如何更加方便快捷调用每一单位的算力。因此这就需要提升NPU的可编程性,包括从硬件体系架构上打造充分可编程的硬件和软件上构造抽象层次更高的编程界面。
从高纬度来看,自动驾驶应用场景不断演进,对AI计算架构的需求也在不断演进。早期ADAS的应用场景简单,算法模型较单一,所以与算法绑定高度定制的AI核被市场接受,能够快速解决应用场景有与无的问题;第二个阶段(也就是现阶段)是NOA应用启动时代,模型种类及数量的增多,加之泛化要求变高,使得通用型较强的GPGPU在率先布局NOA应用的高端车上成为主要的解决方案。但随着时间推移,NOA应用普及及车厂对降本增效的诉求愈发强烈,因此,第三阶段在满足第二阶段和成本效益的情况下,能够兼顾通用性和能效的GP-DSA架构将会成为产业主流。刘珲认为,“从中长期来看,一个在领域内通用性更强,又能比GPGPU效率更高、能进化的DSA的AI计算架构会越来越有希望。”
从全球视野来看,目前有很多大厂已经开始布局定制开发自己的AI计算架构与硬件内核。值得关注的是几家头部大厂如Google、Meta、Tesla以及头部的独角兽公司如Tenstorrent等都不约而同的采用RISC-V指令集来构建整个AI计算体系。与这些公司类似,奕行智能在国内率先把RISC-V用在百Tops以上的大算力AI并行计算领域,通过在内核上构建强大的指令和数据并行,使奕行智能的整个计算架构的性能达到行业领先的水平。刘珲表示,使用RISC-V并非要替代作为自动驾驶芯片主处理器的ARM内核,而是结合RISC-V的架构开放性和可扩展性将其用在AI计算领域,通过结合RISC-V通用性与DSA核架构的效率,使其能在两者上有较好的兼顾。同时结合微架构上的创新,使得整个内核能在相比GPU更小的算力能获得数倍于GPU的智驾网络推理性能。
(图片来源知乎)
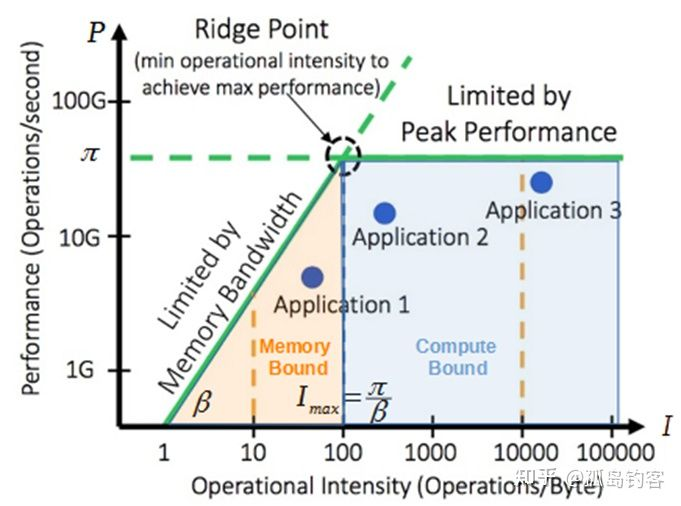
在大模型芯片部署中,编译器是AI模型能够以最高性能和最低功耗高效运行的关键,AI领域应用的大量出现也促进着领域编译的发展。“解决Memory Bound需要硬件微架构与软件编译器联合优化。“像许多其他的科技指标一样,AI芯片的计算性能也有理论上的极限,从Roofline Model可以看出平均带宽需求和峰值计算能力像天花板一样是整个系统计算的能力上限,以计算强度上限Imax为界,划分出AI芯片的两个瓶颈区域,即图中橘色的内存受限区(Memory Bound)和图中蓝色的计算受限区(Compute Bound)。刘珲提到要想让增加的算力真正能提高系统性能必须让算法所处的区域落在计算受限区域,这需要通过软硬协同设计的方式来达成,这就像畅通的交通除了需要基于交通流量合理设计的硬件基础设施,也需要有基于硬件基础设施合理设计的交通调度系统。
最后,刘珲也提到GPU架构把大的计算任务切分给多个小核并且软件基于Kernel执行数据来回在DDR与片内交互,这样导致的问题是更多的数据交互的开销和功耗。奕行智能的AI芯片与之不同的是针对智驾模型的微架构设计优化以更少的数据交互开销来完成计算任务并使大部分的计算驻留片上完成,从而获得更加好的PPA。
“大模型”时代的到来,让AI产业与包括汽车在内的传统行业或新兴产业产生了更多交集,AI进一步的发展和成熟更是为自动驾驶技术带来了巨大的推动力。未来奕行将持续在AI计算架构这块领域上进行更多的创新与探索,帮助更多合作伙伴解决当前自动驾驶在AI模型的推理性能、能效、模型泛化的支持、AI编程的易用性、硬件操作的自由度以及成本上等多个维度的核心痛点,加快AI技术在自动驾驶领域的落地应用与创新发展。