






 技术咨询
技术咨询 代买器件
代买器件 商务客服
商务客服 研发客服
研发客服最近,特斯拉的FSD再次迎来重大版本更新,其beta测试版的版本号从持续了一年多的v11.x直接进阶到了v12。从大版本号的变化可以看出,其FSD软件发生了重大的变化。

为了展示这个版本的效果并说明它相较于上一个版本的重大改变,马斯克专门用手机拍了一个画面略显模糊、一镜到底的评测直播,在这场时间长达45分钟的直播里,马斯克在两段交通场景复杂度远远低于中国一线城市上下班场景的路线上,展示了FSD可以媲美中国“郊区NOA”(因其场景复杂度介于高速和城区之间)的出色表现。

视频出来后,一些立场先行的特斯拉鼓吹者开始鼓着腮帮子发言了,核心观点是,包括华为在内,国内这些追踪模仿特斯拉自动驾驶技术路线的车企的作业是白抄了,因为被模仿者的技术路线再次迎来了重大的更换。说实话,这话只说对了一小半,特斯拉FSD技术确实有了重大的跃迁,但是,国内车企抄特斯拉作业的说法并不符合实情,而且,本土车企之前走过的每一步依然都算数。
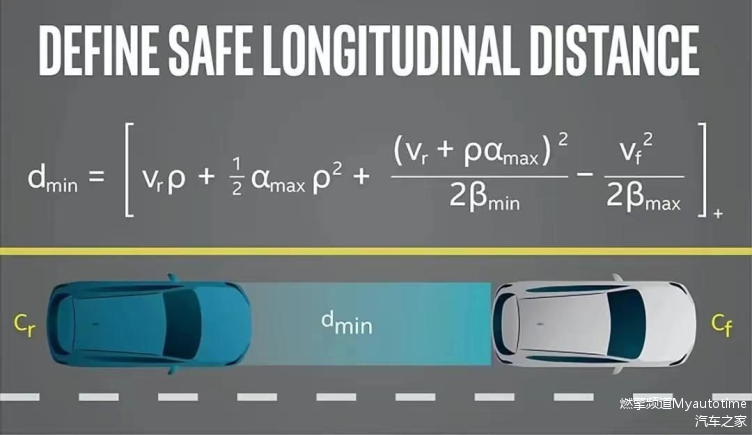
要搞清楚这一版FSD软件的重大更新在哪里,我们需要补充一些知识点,认识并理解车端自动驾驶软件算法的三大部件/模块-感知和定位、规划和决策、执行和控制,也就是我们平常所说的感知层、决策层和执行层。

在具体实现层面,这三层之间有着明显的界限,逻辑链条也很清晰:车辆通过传感器感知周遭环境,确定车辆位置、速度、加速度,根据识别出来的语义进行行驶路线的规划和横纵向的决策,最后通过转向和制动机构控制车辆行驶。

不过,学术界一直在研究直接端到端的实现方式,即传感器输入到执行机构的输出之间不再有明显的界限。按照老马的解说,特斯拉FSD Beta V12便采取了端到端的形式,其直接的表现便是将规划和控制的实现方法由代码形式改成了神经网络形式,与感知层的神经网络合并成了一个大网络,一顿操作猛如虎,之前v11.x中的30多万行C++代码已经所剩无几。
“抄作业”的说法其实本不值一提,但三人成虎,国人被欺骗得好惨。要反驳这个论点,只需要提出灵魂一问:BEV、占用网络是特斯拉的首创吗?
BEV-鸟瞰视图、上帝视角,这条技术路线其实早就提出来了,普通人都能想得到的嘛,问题是之前为什么没有实现呢?是因为原来的感知神经网络主要基于卷积神经网络-CNN,CNN的优势在于做二维图像识别,比如幼儿园门口的闸机可以识别出幼儿园小朋友和接送的家长,就是靠CNN完成背景识别、图像分割、特征提取、目标检测的。CNN善于做静态、二维图像识别,对于动态变化的四维交通环境(三维立体空间+时间)就东风无力百花残,可谓勉为其难了。

直到原创出自谷歌的Transformer大模型的横空出世,依靠注意力机制洞察各种交通参与者之间的关联,判断自车和周围动静态交通参与者的时空关系,才建立了三维的矢量空间。

至于为何是特斯拉率先实现的,是因为Tranformer大模型极其吃算力,在英伟达的Orin X面世之前,特斯拉HW3.0芯片算力高达72TOPS,而同时期的Xavier只有30TOPS算力,没有金刚钻,当然干不了瓷器活嘛,道理很简单,特斯拉不过是依靠算力优势,率先落地了BEV这条技术路线而已,而且,按照国内车企的说法,他们早在2021年就已经在Orin的样片上实现BEV了,从工程实现上,仅仅落后特斯拉一点点。

我们再看占用网络。三维体素空间的占用网络思想提出于2019年,特斯拉再次在落地上抢了先,它在2022年的CVPR会议上公布了Occupancy Networks,并在2022年的AI DAY上公开展示了占用网络的应用,国内与此对标且已经公开的是华为在2023年4月份上海车展上公布自己的一揽子智能汽车解决方案时对外发布的GOD网络。

如上所述,BEV和占用网络的原创均非出自特斯拉,特斯拉只不过凭借在这个赛道的先发优势,依靠大规模交付车辆的数据优势和可自研芯片的算力优势,将它们率先落地了而已。至于为何流传“抄作业”的说法,应该是从知识分子云集的知乎上传播开来的。至于为啥传播这种说法,背后的原因很复杂,之前一边倒地预言华为不可能在2030年之前实现7纳米芯片的生产,是不是出于同样的原因呢?
相关文章








