随着 HD 5000 和 6000 系列的发展, 的 Terascale(万亿级)架构变得非常具有竞争力。然而在 2010 年代初,面向通用计算的 趋势兴起, 并不希望错失这个机会。Terascale 的 SIMD 引擎是 ATI 的 DirectX 9 时代 中执行单元的远亲。他们可以进行计算,但利用其能力却不一定总能成功。英伟达的 Fermi 架构具有强大的计算能力, 不想毫无抵抗就放弃一块有潜力的市场。
本文引用地址:Graphics Core Next(GCN)彻底摒弃了以通用计算的可预测性能为核心的 Terascale 策略。虽然 Terascale 的 64 宽波前仍然存在,但 GCN 的其他特点却截然不同,以至于它甚至不能算作一个远亲。GCN 的指令集类似于典型的 CPU 或英伟达的 Fermi。为了将这些责任转移到硬件上,显式调度信息已被移除。线程内的执行严格遵循标量,摒弃了 Terascale 从单个线程每周期发出多个操作的能力。
GCN 首次亮相市场是在 Tahiti 芯片上,这是一款采用台积电 28 纳米工艺制造的 352 平方毫米芯片。Tahiti 配备 384 位 GDDR5 接口与显存连接,并升级为与主机的 PCIe 3.0 链接,使其比 AMD 之前的 Cayman 具有更高的片外带宽。自 2011 年发布以来,GCN 衍生架构为 AMD 的产品提供服务长达十年。从 Tahiti 到 2021 年的 Cezanne,GCN 经历了大量演变,但保留了其可识别的计算单元结构。因此,GCN 是历史最悠久的图形架构之一。即使在今天,GCN 的 DNA 仍然延续在 AMD 面向计算的 CDNA 中。CDNA 线路取消了部分 GCN 的图形功能,将重心转向 FP64,但仍然是一个可识别的 GCN 衍生产品。

Radeon HD 7950 使用稍微缩减的 Tahiti 芯片
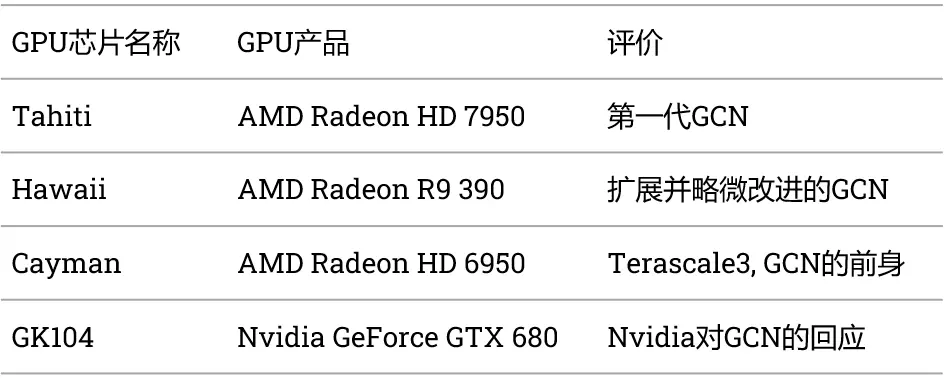
这篇文章将重点关注 GCN 早期 Tahiti 和 Hawaii 的发展情况。这里有来自 AMD Radeon HD 7950 的数据,它使用了稍微精简的 Tahiti 芯片。Hawaii 是 GCN 的放大版。它于一年后推出,对最初的 GCN 架构进行了轻微增强,旨在与英伟达当时最大的 GPU 竞争。

MSI 的 Radeon R9 390 采用开放式空气冷却器
Hawaii 首先推出了 R9 290 系列,但是会优先考虑 R9 390。这是一个稍微精简的 Hawaii 芯片,配有 8 GB 的 VRAM。
系统架构
GCN 的基本构建模块是计算单元(CU)。Tahiti 的着色器阵列由 32 个 CU 组成,HD 7950 启用了 28 个。每个 CU 都有一个专用的 16 KB 向量缓存和 64 KB 本地数据共享,但与多达四个相邻 CU 共享一个指令缓存和标量缓存。
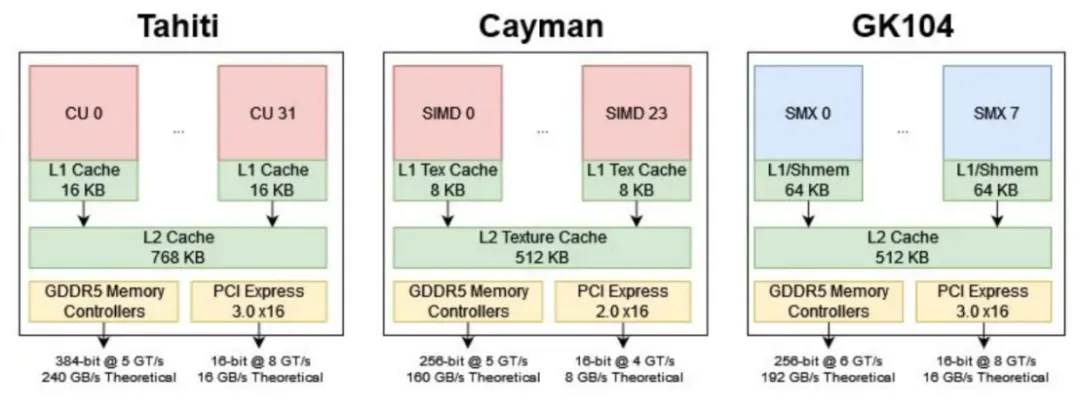
计算单元阵列可以由图形命令处理器或异步计算引擎(ACEs)提供,具体取决于工作是在图形队列上提交还是在计算队列上提交。对于计算工作负载,每个 ACE 可以在每个周期启动一个波前。Tahiti 有两个 ACE,让它在 GPU 上每个周期发射两个波前。
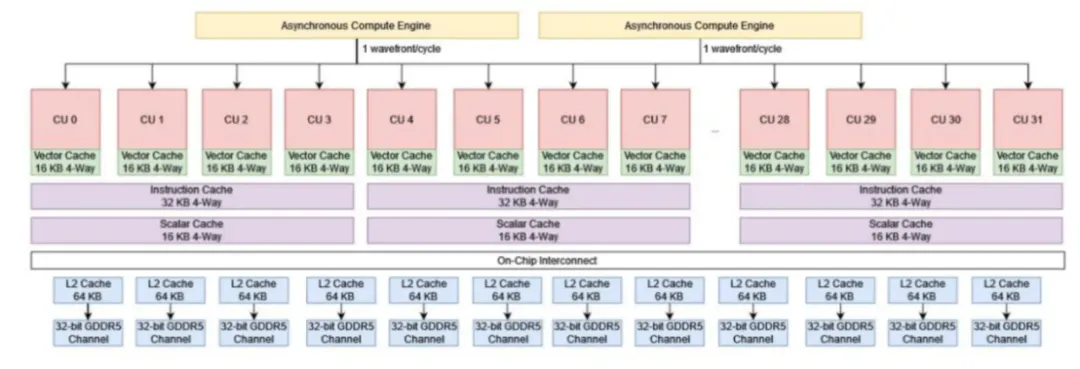
对于图形工作负载,GCN 的光栅化器消耗由顶点着色器导出的屏幕空间坐标。它们每个时钟可以处理一个基元,每个周期可以写出多达 16 个像素,因此每个光栅化器每四个周期可以发射一个 64 宽度的波前。Tahiti 有两个光栅化器,让它每两个周期发射一个像素波前。屏幕空间在两个光栅器之间划分,反映了 Cayman 的两个图形引擎的方法。Hawaii 使用了四个光栅化器,使其更快地填充着色器阵列。
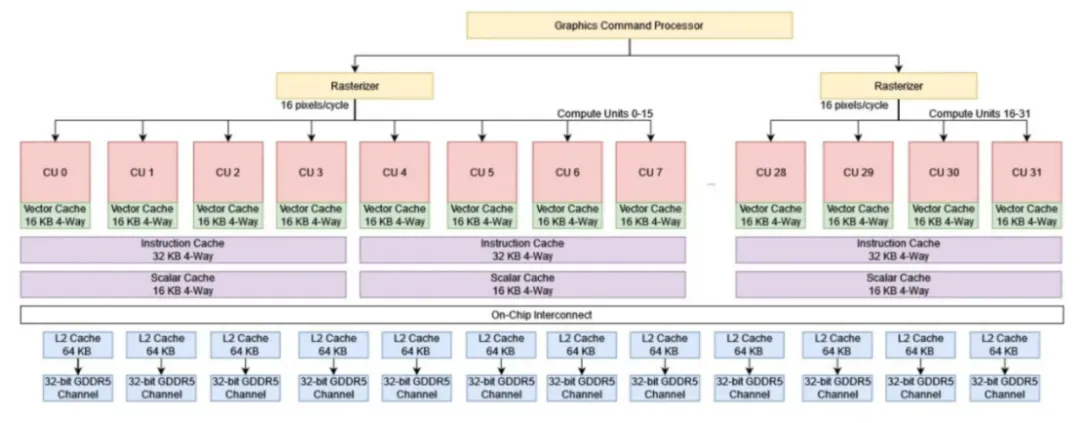
计算工作负载将其结果写入 VRAM,供未来的内核使用或复制回主机。对于图形,像素着色器导出被发送到渲染后端。Tahiti 上的每个渲染后端都有一个 16 KB 颜色缓存和一个 4 KB 深度缓存。最终像素颜色被写入内存控制器并绕过二级缓存。与 Terascale 不同的是,渲染后端与内存控制器分离,并且可以独立于内存总线宽度进行缩放。
GCN 的计算单元
GCN 的计算单元与 Terascale 的 SIMD 大致相当。两者每周期都可以完成 64 次 FP32 运算,如果将熔合乘加运算计为两次,则是原来的两倍。然而,AMD 已完全重组了这个基本构建模块,将 VLIW 捆绑打包从图片中提出。计算单元由四个较小的 SIMD 组成,而不是一个能够发出四次指令的大型 SIMD。每个 SIMD 都有自己的 64 KB 向量寄存器文件和 10 项调度程序分区。线程内的执行现在是完全标量的,这意味着 CU 不能从同一线程的每个周期发出多条指令。然而,如果 SIMD 的调度程序分区中有多个线程已就绪,并且每个线程的就绪指令都发送到单独的功能单元,那么 CU 可以每周期发射多达五个指令。
计算单元前端
计算单元(CU)的流水线从 32 KB、4 路组相联的 L1 指令缓存中提取指令开始。指令缓存使用 64 字节行,与 CPU 上常见的缓存行大小保持一致。一个指令缓存实例可由最多四个相邻的计算单元共享,并可在每个周期向每个计算单元提供 32 字节。这可能是通过四分组的设置实现的,因此存储器分组冲突可能减少指令带宽。

Terascale 3 在多达四个 SIMD 之间共享一个 48 KB 的 ALU 指令缓存,这与 GCN 有一定的相似性。由于 GCN 的可变长度指令平均需要较少的存储空间,AMD 得以将指令缓存大小削减到 32 KB。Terascale 3 使用了固定长度的 64 位指令。一束指令的长度可以根据编译器打包的指令数量和立即值的多少而变化,范围从 64 位到 384 位。GCN 的指令长度为 32 位或 64 位,后面可以选择逐添 1 个 32 位立即值。
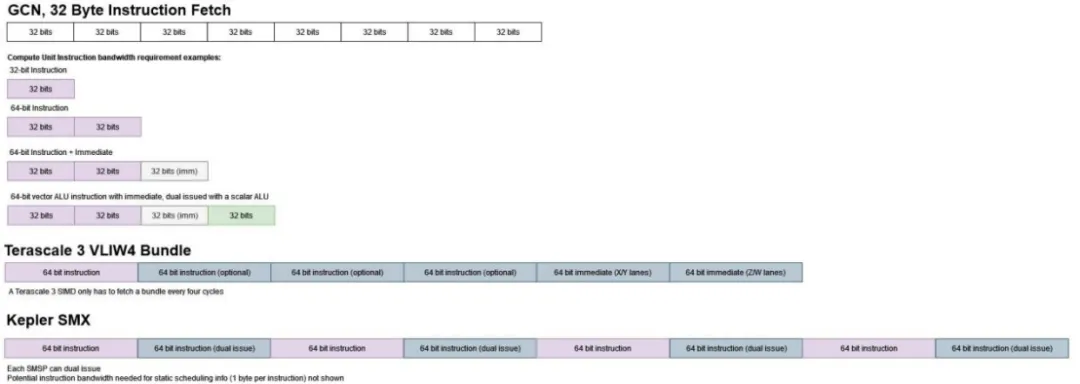
指令带宽需求可视化
英伟达的 Kepler 使用 8 KB 的指令缓存,专用于每个 SMX。私有缓存更适合处理 Kepler 的高指令带宽需求。一个 SMX 需要每周期至少传输 6 条指令以满足其 192 个 FP32 单元的需求,因为英伟达的每条指令在 32 个 32 位元素的长向量上进行操作。使用固定长度的 64 位指令,根据每条指令的静态调度信息字节计算,Kepler 的指令缓存每周期需要提供 48 或 54 字节的指令。GCN 的计算单元每个周期只需要执行一条指令就可以使其向量执行单元饱和,这既是因为它的向量执行单元较少,也是因为每条 GCN 指令都在一个 64 长的向量上操作。
调度和指令发布
一旦指令被获取,它们将保存在一组指令缓冲区中。计算单元的四个 SIMD 中的每一个都有一个 10 项的缓冲区,使其能够跟踪来自最多 10 个独立线程的指令。因此,整个计算单元可以跟踪 40 个线程(或波前)。对于 64 宽波前,计算单元可以在运行中执行 2560 个 32 位操作。
每个周期,计算单元选择一个 SIMD 并扫描它的 10 个线程,以查看是否有准备好执行的线程。GCN 可以通过选择多个线程并发布不同类别的指令来实现有限的多发射能力。例如,一个线程的标量算术逻辑单元 ALU(Arithmetic Logic Unit)指令可以与另一个线程的向量 ALU 指令同时发射。理论上,一个计算单元每个周期可以发出 5 条指令。但是如此高的发布率应该是罕见的,因为工作负载不太可能有来自不同类别的指令的均匀混合。高占用率对充分利用这种多发射策略至关重要。如果 SIMD 有更多线程可以选择,它将更有可能找到具有正确指令混合的多个线程以实现多发射。
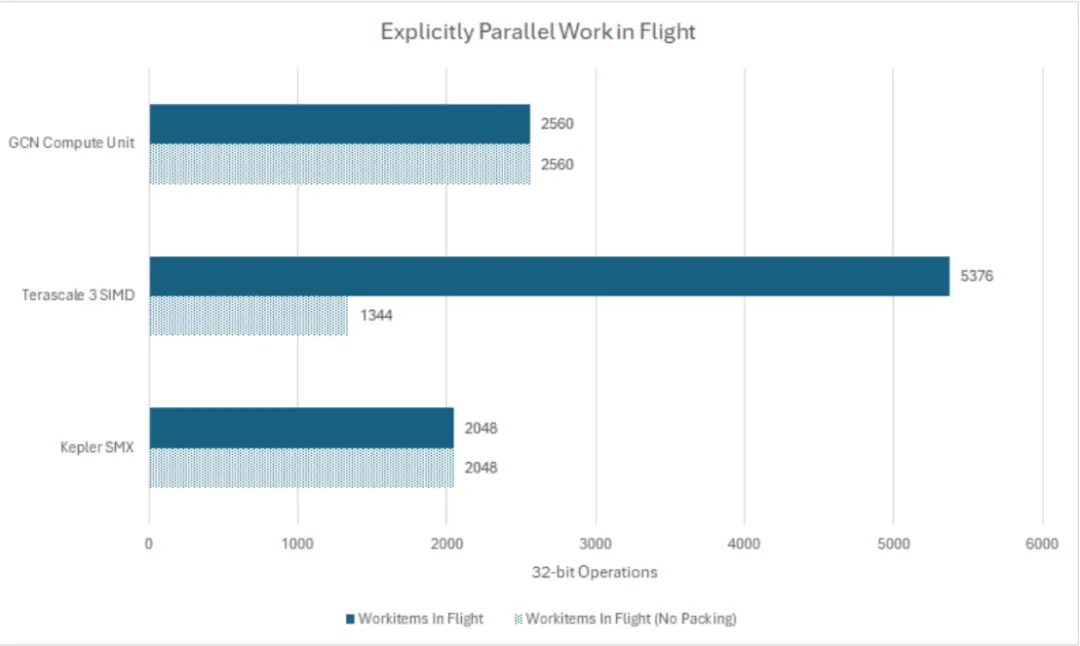
假设达到理论占用率
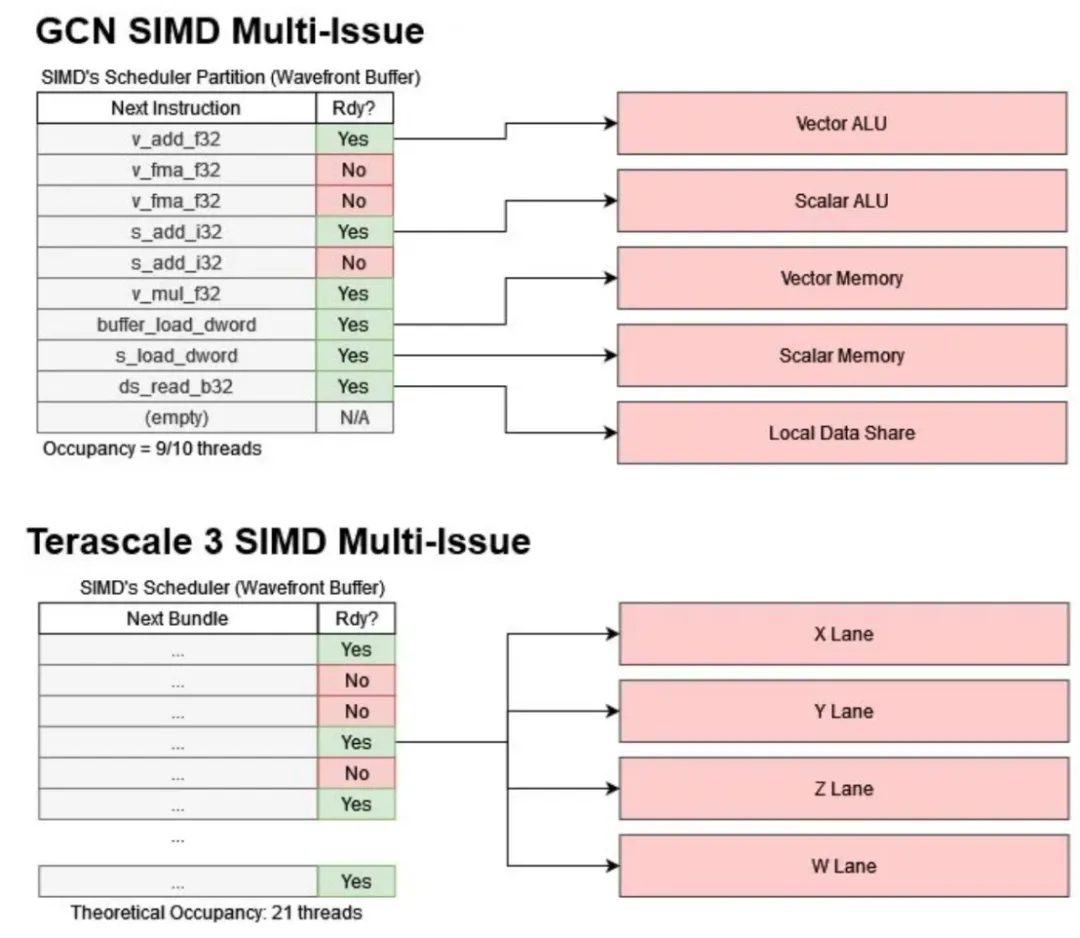
GCN 的策略与 Terascale 形成鲜明对比,Terascale 强调从单个线程的多发射,这给编译器带来了巨大的负担。编译器必须找到在打包成捆时既独立又不过度占用寄存器文件端口的指令。GCN 转向使用线程级并行性意味着编译器可以忽略这些硬件细节。英伟达的 Kepler 采用了一种折中的方法。寄存器组冲突由硬件操作数收集器处理。编译器负责在指令流中为双发射标记成对的指令,但双发射真正起到锦上添花的作用。与 Terascale 相比,即使不进行多发射,Kepler 也能保持更好的吞吐量。
尽管 GCN 失去了从单个线程进行多发射的能力,但它从一个线程发出请求的次数比 Terascale 要多。一个 Terascale SIMD 有 16 个线程宽,每四个周期可以发射一个捆绑包,但不能连续执行来自同一线程的两个捆绑包。因此,Terascale 需要在一个 SIMD 中至少有两个线程才能实现最大吞吐量。GCN 则消除了这一限制,因此 SIMD 上的线程可以每四个周期执行一次指令。Terascale 可以实现更高的单线程吞吐量,但前提是编译器在将指令打包成捆绑包时做得足够好。

在没有寄存器组冲突和依赖延迟的情况下线程的发射速度的粗略设想。每个框代表一个周期。
与此同时,Kepler 可以迅速处理单个线程。它使用 32 宽的波和 32 宽的执行单元,所以一个线程可以在每个周期发射一条指令。双发射是锦上添花。因此,面对低占用率和有限的线程级并行性,Kepler 可以保持相当不错的吞吐量。
寄存器文件
选定的指令从寄存器文件中读取其输入。在 GCN 中,Terascale SIMD 的巨大 256 KB 寄存器文件被拆分为四个 64 KB 寄存器文件,每个 GCN SIMD 一个。GCN 的寄存器文件几乎可以肯定是分组结构,但与 Terascale 相比,应该更少地受到寄存器组冲突的影响。假设仍然是四分组的寄存器文件,GCN 可以提供四个输入,以供给可能需要多达三个输入的指令(用于熔合乘加)。如果指令从标量寄存器或指令流中的立即值获取输入,对向量寄存器文件的带宽需求可能会较低。最重要的是,GCN 可能有一个操作数收集器,可以在偶尔出现存储器分组冲突的情况下,消除对寄存器文件带宽的需求。
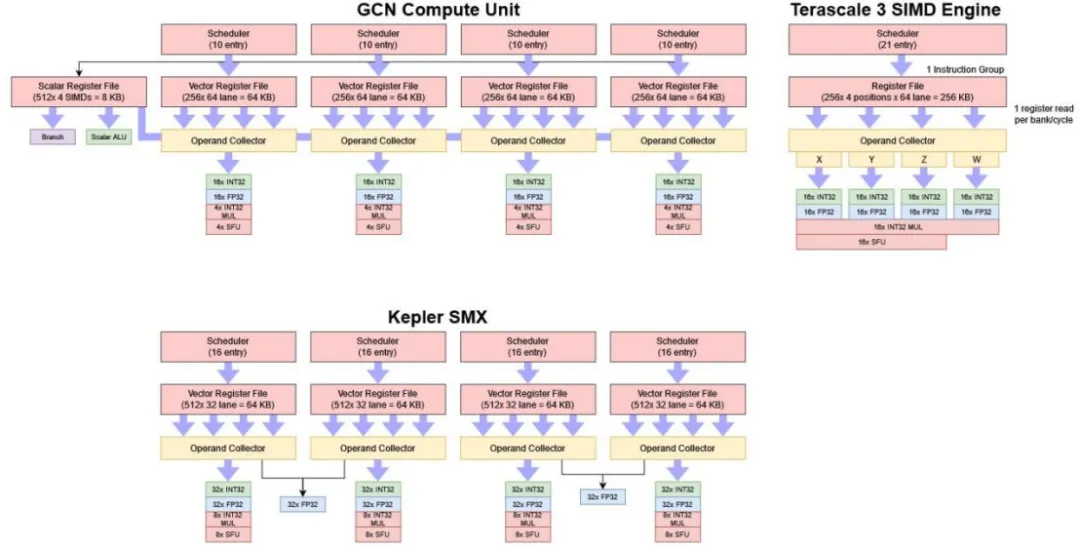
Terascale 需要复杂的调度和寄存器分配来实现良好的利用率。每个 VLIW 通道只能将返回值写回到其对应的寄存器文件分组中,而在读取端的任何寄存器组冲突都可能降低 VLIW 打包效果。由于 SMX 的 FP32 单元没有足够的寄存器文件带宽来为 FMA 操作提供数据,因此 Kepler 需要付出更多的努力以实现完全优化。
除了向量寄存器文件外,GCN 计算单元还有一个 8 KB 的标量寄存器文件。如果程序可以将一些变量存储在标量寄存器中,就可以减少向量寄存器的使用并实现更高的占用率。
执行单元
GCN 中的每个 SIMD 都有一个 16 路宽的执行单元。常见的 FP32 操作和整数加法以全速执行,而 32 位整数乘法和特殊功能以四分之一速率执行。理论吞吐量与 Terascale 3 相似。但是,GCN 不再需要将四条指令打包到每个捆绑包中以饱和计算单元,而是需要至少四个活跃线程来填充其四个 SIMD。

去除猫毛后,准备重新粘贴 R9 390 进行测试。以前的所有者有一只柴色的猫
Terascale 的分支单元被转换为标量 ALU。尽管 GPU 主要是向量处理器,但它们仍然需要处理控制流和地址生成。这些操作通常在一个向量上是常数,所以标量 ALU 可以卸载这些计算。将这些标量操作移至专用单元有助于减轻向量 ALU 的负载并提高功率效率。
与 Kepler 的 SMX 相比,GCN 的计算单元更小,吞吐量更低。为了弥补这一缺陷,Tahiti 拥有的计算单元数量是 GK104 拥有 SMX 数量的四倍。

HD 7950 的侧边
Hawaii 扩展了着色器阵列,使其可以实现超过 5 TFLOPS 的 FP32 吞吐量。然而,作为未来趋势的一个标志,Hawaii 的 FP64 性能落后于 Tahiti。GCN 的 FP64 吞吐量可从半速配置到 1/16 速。Tahiti 采用与 GCN 最初计算设想相一致的 1/4 速 FP64 执行进行配置。随着 GPU 计算在客户端应用中的重要角色逐渐明确,AMD 对 FP64 执行的投资减少。因此,Hawaii 采用了更普通的 1/8 速 FP64。但即使以 1/8 速,AMD 的客户端显卡在 FP64 性能上仍大幅领先于英伟达同类产品。
计算单元数据缓存
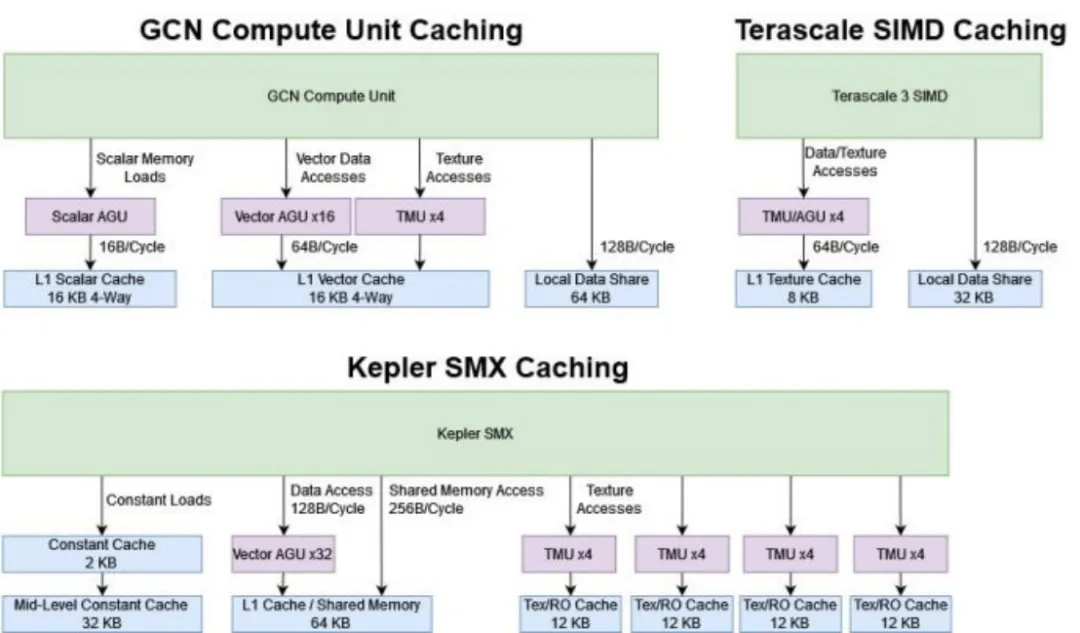
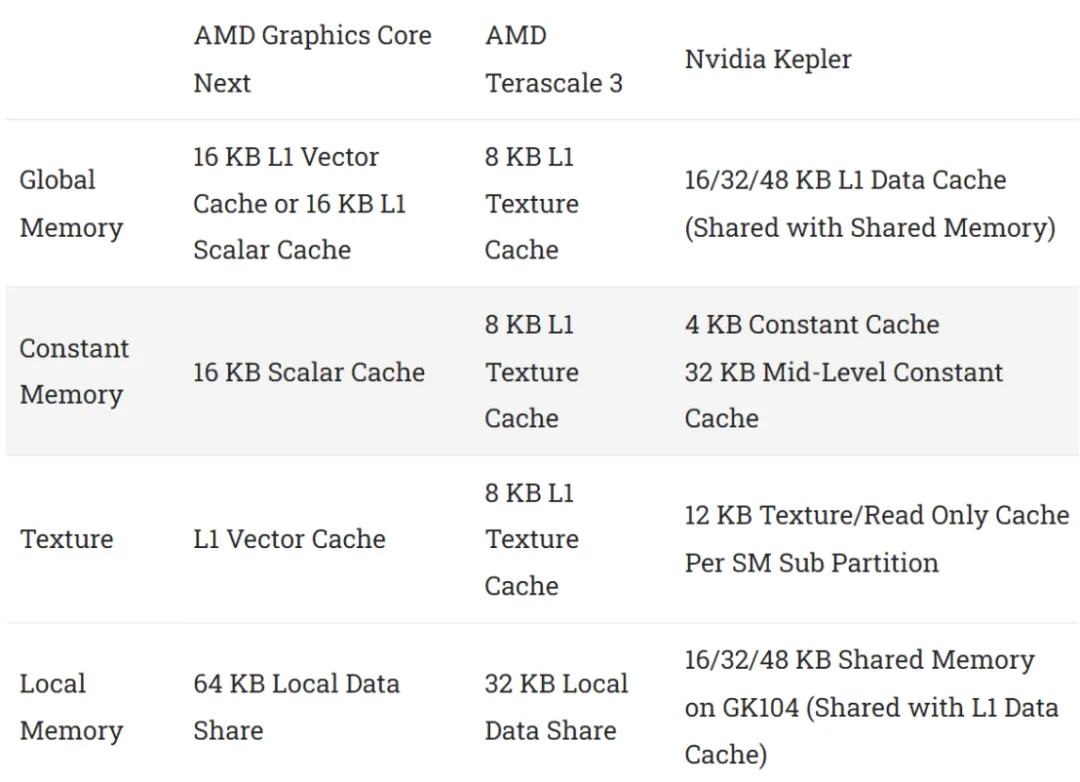
AMD 重塑了缓存层次结构,以适应通用工作负载,而非仅专注于图形。一个 16 KB 的 4 路组相联向量缓存作为计算单元的主数据缓存。它使用 LRU 替换策略,64B 行,并且每周期可以为计算单元提供 64 字节。Terascale 的 8 KB 只读纹理缓存可以提供相同的每周期带宽,但 GCN 享有两倍的缓存容量和更低延迟访问。
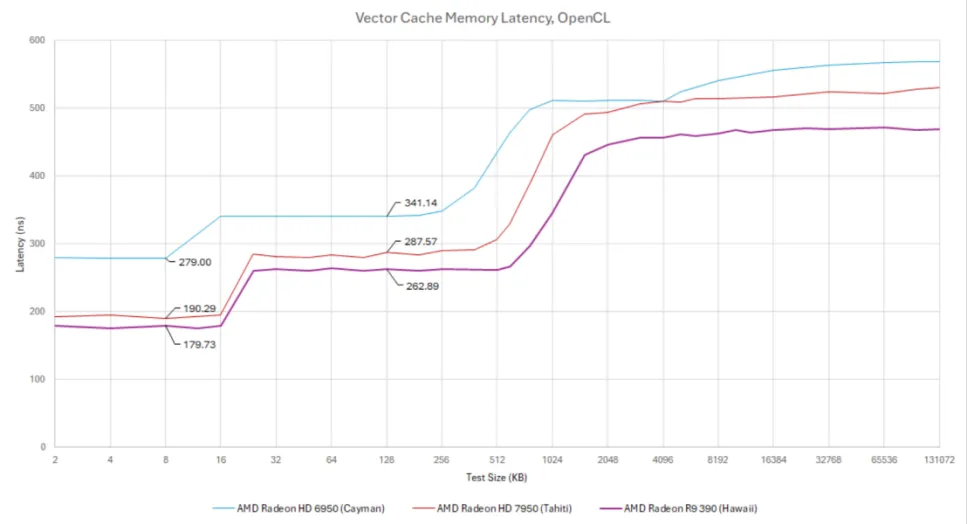
GCN 的矢量缓存也支持写入。L1 缓存是直写、写分配设计。它不如大多数 CPU 中的回写缓存好,但 L1 仍然可以在写入被传递到 L2 之前帮助合并写入。
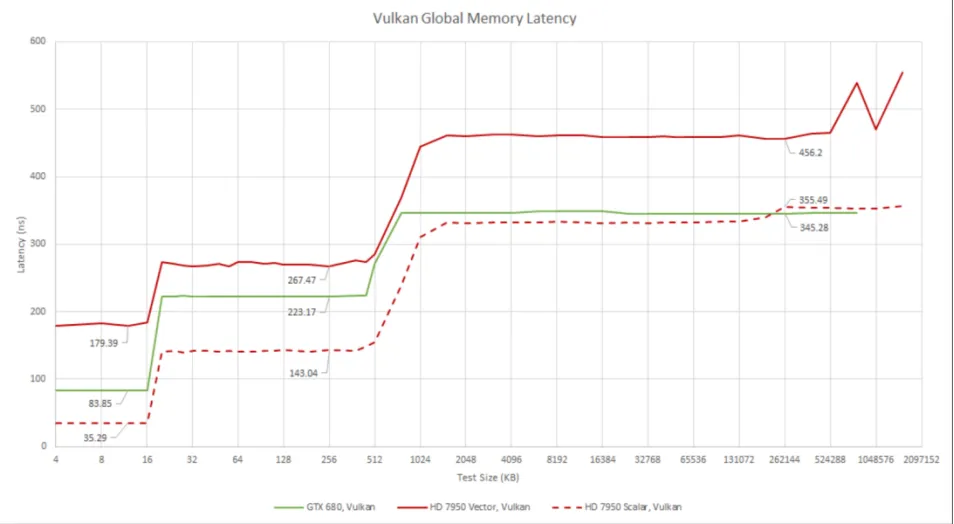
尽管 GCN 相较于 Terascale 有了巨大的改进,但 Kepler 在向量访问方面的延迟仍然较低。AMD 希望通过优化部分内存访问以使用标量路径,来缓解这一问题。
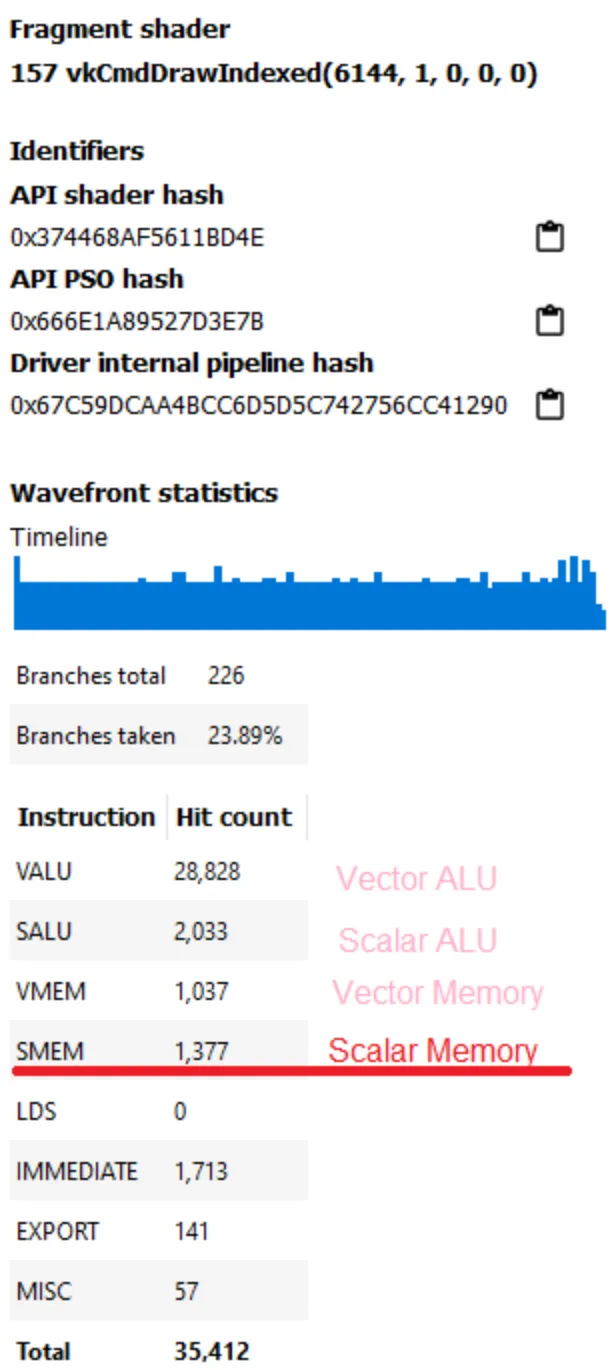
分析 RX 460 上运行的 Valheim。RX 460 使用北极星,GCN 架构的衍生物
标量存储器访问由多达四个相邻计算单元共享的 16 KB 4 路标量高速缓存提供服务。标量缓存每周期可向每个计算单元传送 16 个字节,并针对低延迟进行了优化。标量缓存命中的延迟不到 50 纳秒,这对于此时的 GPU 世界来说是非常快的。它与 Terascale 的纹理缓存 200+ ns 的延迟相去甚远,比开普勒的任何缓存都快,除了它的 2 KB 常量缓存。
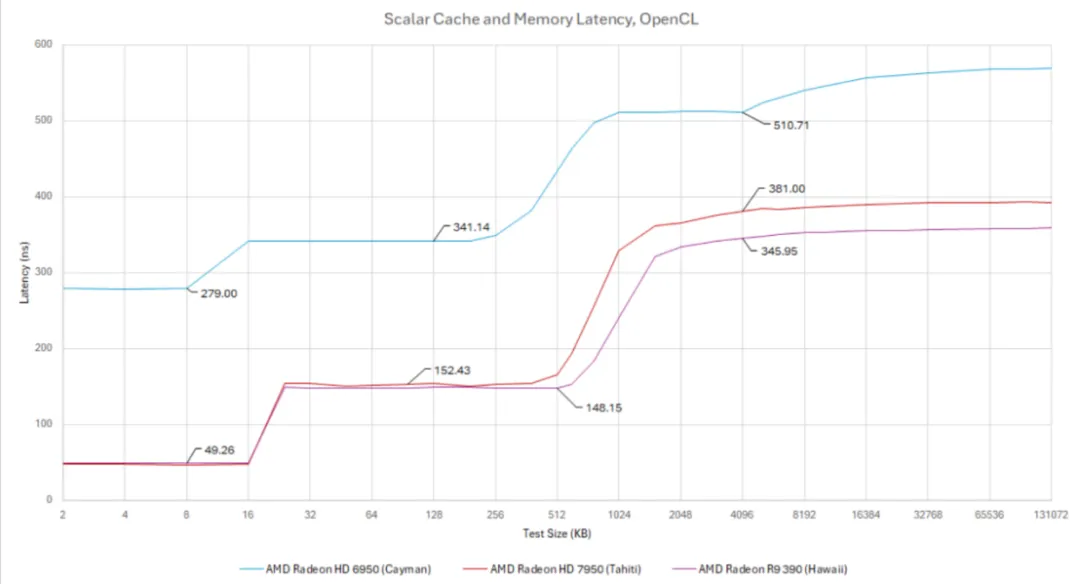
与 Terascale 相比,GCN 在计算单元内的缓存策略既现代又灵活。除了对计算工作负载的巨大改进外,GCN 的改变还应有助于图形处理。将纹理缓存容量从 8 KB 增加到 16 KB 应该会减轻对芯片级互连的负载,并且较低的延迟意味着 GPU 在维持良好性能时需要较少运行中的工作。
描绘 GK104 Kepler。GK210 拥有 128 KB 的 L1 缓存/共享内存
英伟达的 Kepler 架构在缓存策略上既融合了过去的特点,也具备新颖之处,类似于 Fermi 架构。只读纹理缓存仍然存在。但是 Kepler 还有一个单独的 L1 数据缓存,它与本地内存共享存储空间。如果这还不够,Kepler 的 SMX 还具有私有的两级常量缓存设置。常量缓存与 GCN 的标量缓存在功能上有一定重叠。但与 Fermi 不同,英伟达的编译器不再尝试为跨波形上的常量内存访问使用常量缓存。您必须使用__constant 限定符显式标记内存,以便使用常量缓存层次结构。
结果是,Kepler 具有三个独立的数据缓存路径,每个路径都具有足够的容量来独立运行。这种缓存策略让英伟达可以针对特定的工作负载类型专门优化每个缓存。纹理缓存具有极高的 96 路关联性,并且常量缓存提供了非常低的延迟。但是,为所有内容设置独立的缓存会占用面积。一个 SMX 拥有 146 KB 的缓存和本地内存。
用于服务不同内存类型的缓存
相比之下,一个 GCN 计算单元有 80 KB 的专用数据缓存和便笺式存储器。如果将 16 KB 的 L1 标量缓存分配给 4 个 CPU,这个数字会上升到 84 KB。
本地内存
除了全局内存层次结构之外,每个 GCN 计算单元都有一个名为 Local Data Share(LDS)的 64 KB 软件管理的本地内存。OpenCL 将此内存类型称为「本地内存」。LDS 的结构与 Terascale 中的类似,但容量翻倍。它包括 32 个存储器分组,每个分组每周期可以读取一个 32 位元素,总共每周期实现 128 字节的带宽。
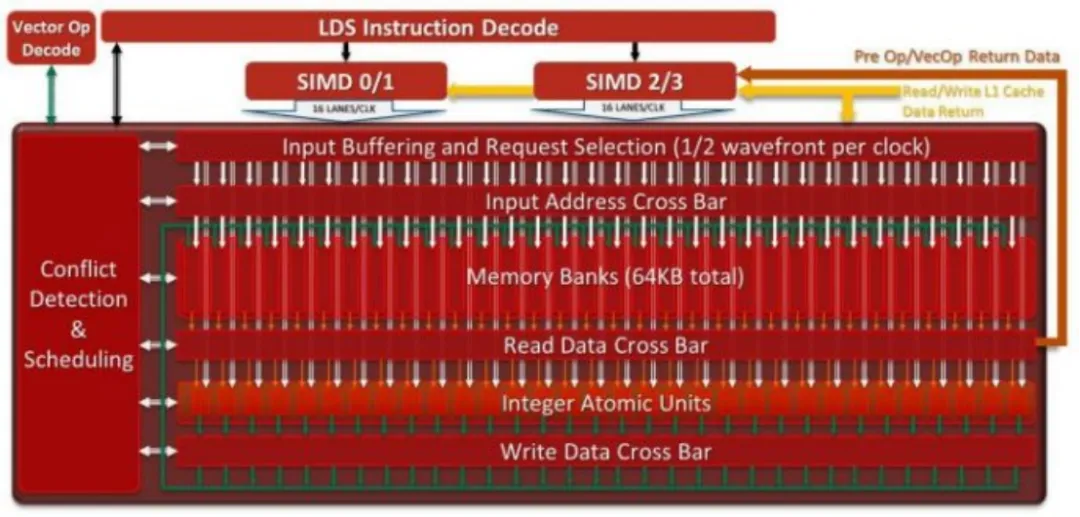
来自 AMD GCN 的技术文档
英伟达的 Kepler 会根据 GK104 或 GK210 变体的不同,从一个 64 KB 或 128 KB 的 SRAM 块中动态分配本地内存和 L1 缓存存储空间。Nvidia 将本地内存称为「共享内存」。与 AMD 的实现类似,Nvidia 的共享内存由 32 个存储器分组组成,但每个分组宽度为 64 位。这为 Kepler 提供了每周期 256 字节的本地内存带宽,使其更适合处理 64 位数据类型。
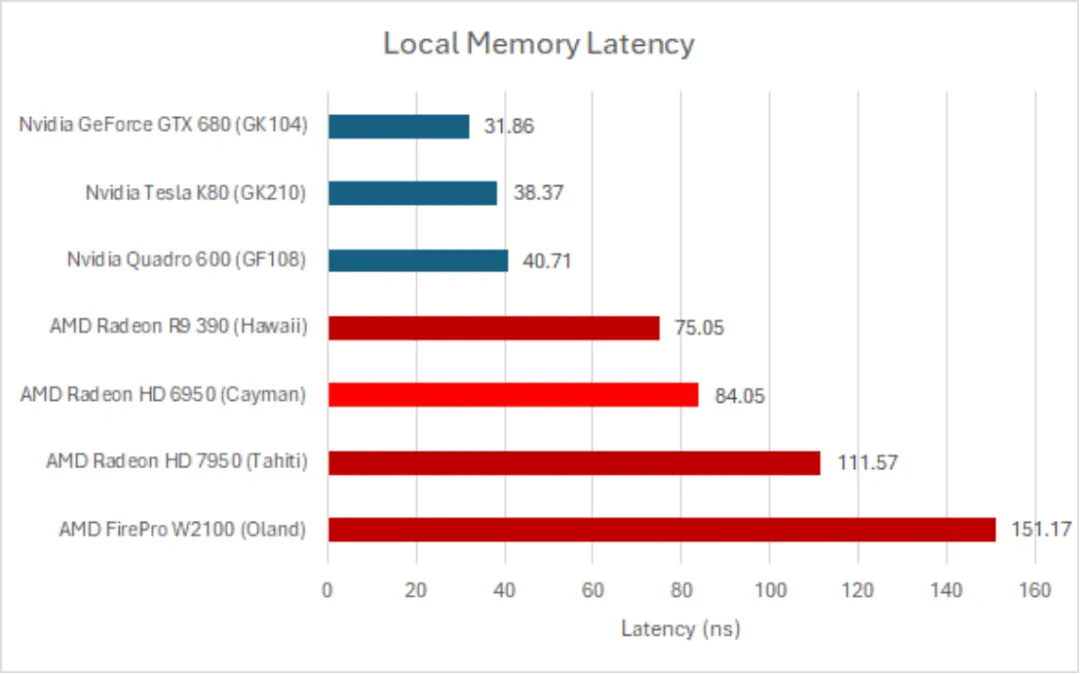
正如之前提到的,当在 LDS 内进行指针追踪时,GCN 的表现出奇地差。Tahiti 的表现比 Cayman(Terascale 3)差。Hawaii 的表现更好,但仍远不及英伟达同时代的架构。

AMD 的优势在于通过 LDS 同步线程。内置在 LDS 中的整数原子单元有助于加速这些操作。而英伟达的 Fermi 和 Kepler 架构没有相应的功能。它们的共享内存非常快,但是在原子操作的性能方面仍有很大的改进空间。
二级缓存
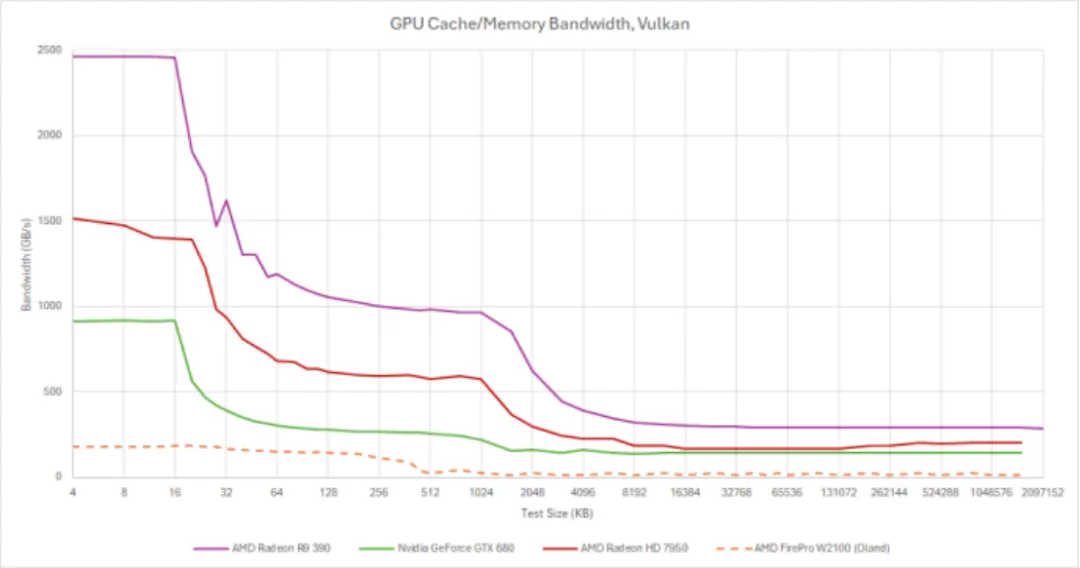
与大多数 GPU 一样,GCN 具有跨 GPU 共享的 L2 缓存。L2 缓存有助于处理 L1 未命中,并分为独立的分片以提供高带宽。每个分片具有 64 KB 或 128 KB 的缓存容量,并连接到一个内存控制器通道。Tahiti 和 Hawaii 似乎都使用 64 KB 分片。每周期一个分片可以读取 64 字节,因此 Tahiti 的 L2 应具有每周期 768 字节的带宽。因此,在 925 MHz 的 Boost 频率下,HD 7950 理论上具有 710 GB/s 的 L2 带宽。在 1 GHz 时,R9 390 具有 1 TB/s 的 L2 带宽。
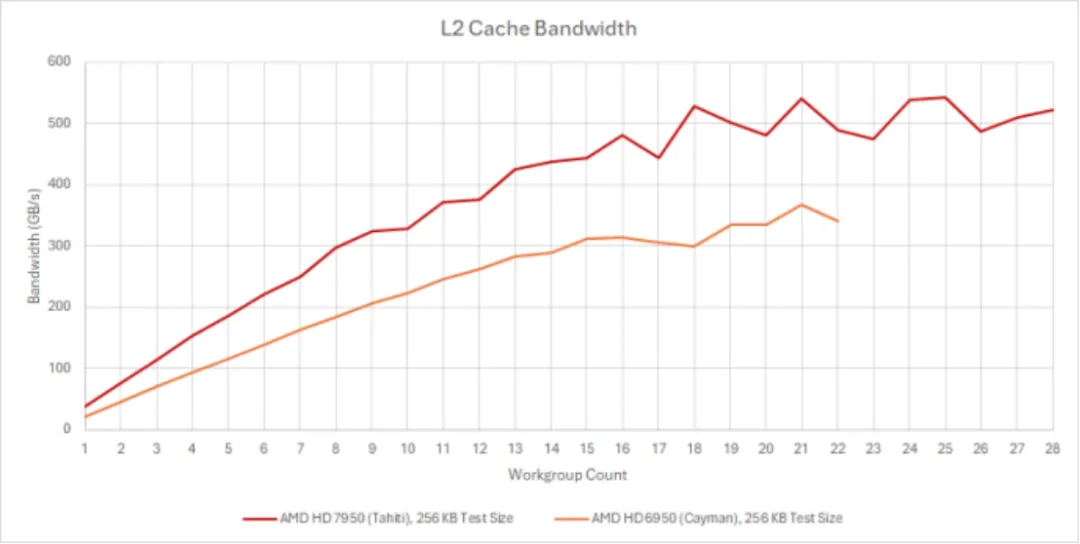
Terascale 具有类似的 L2 分片配置,每个分片为 64 KB,每周期提供 64 字节。然而,Terascale 的 L2 只是一个只读纹理缓存。GCN 的 L2 采用了现代化的写回设计。写回缓存只在行被逐出时将写操作向下一级传播,从而吸收写带宽。此外,GCN 的 L2 分片可以处理原子操作。Terascale 上的原子操作将在单独的、较小的读写缓存中处理,并且性能较差。
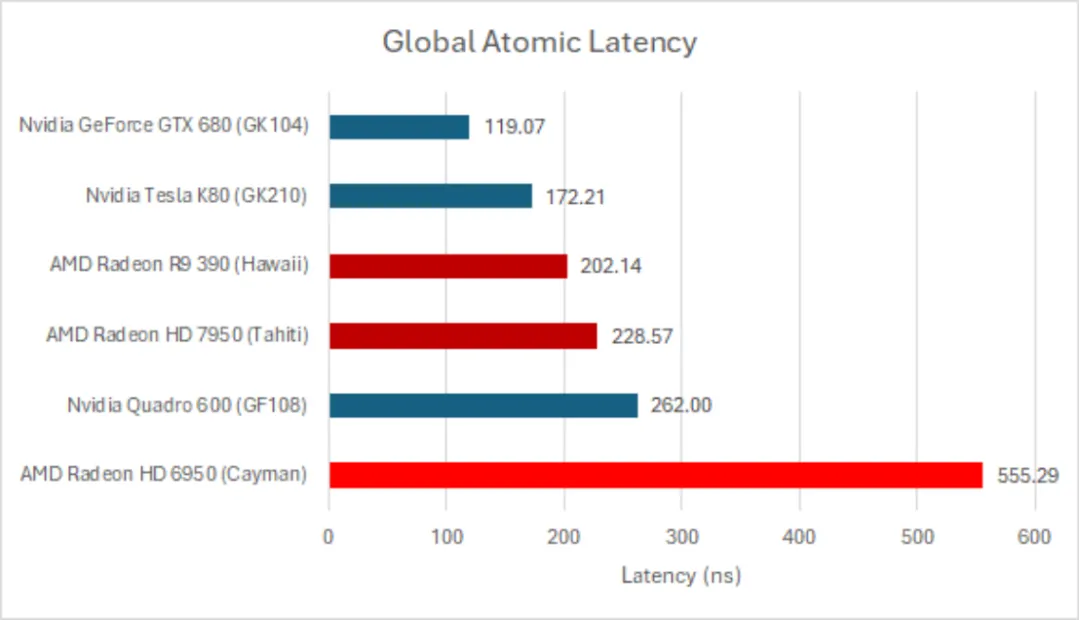
关于 GCN 记忆子系统的评论
Terascale 的缓存是基于图形处理构建的。着色器程序不需要向内存中写入太多数据,它们的输出被发送到专用的片上缓冲区。顶点着色器会输出到参数缓存和位置缓冲区,而像素着色器会将其输出发送到 ROPs(渲染输出单元)。
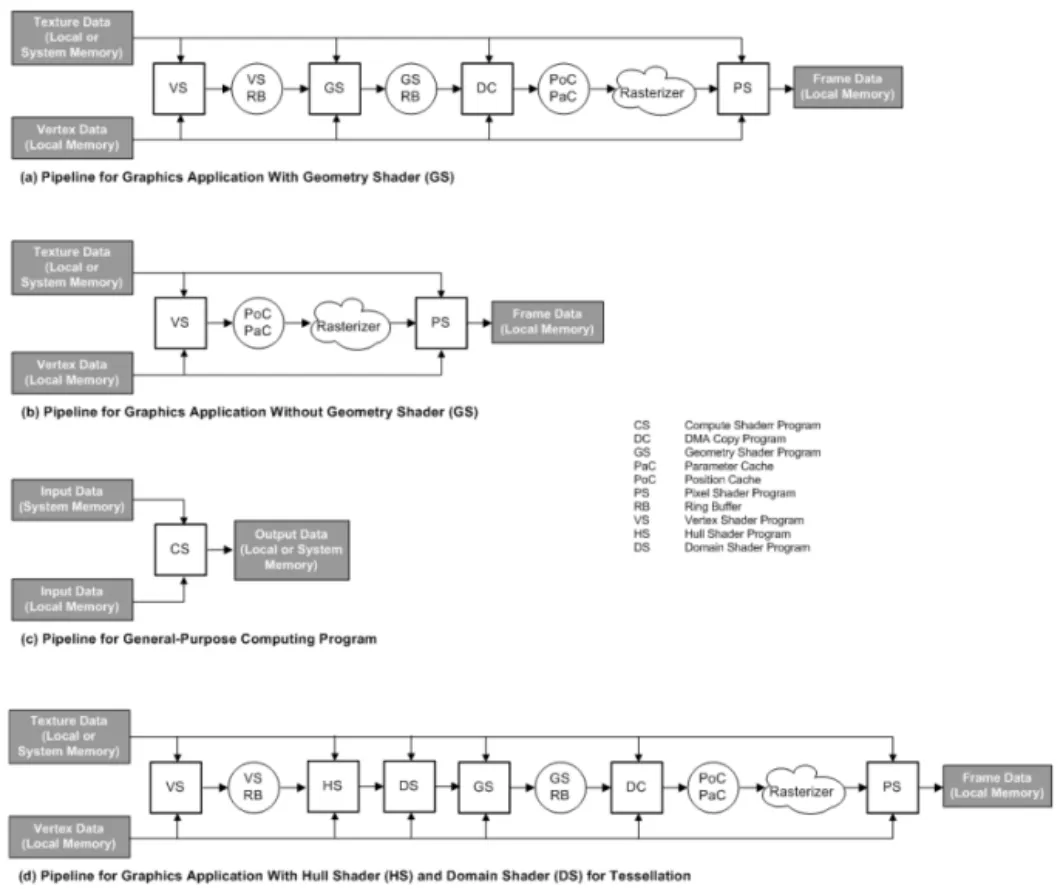
根据 Terascale ISA(指令集架构)手册,每个着色器程序的输出都通过专用的片上缓冲区进行传递,以尽量减少 VRAM(显存)写入。显然,计算程序无法从这些特殊缓冲区中受益。
计算程序被硬挤进这种现有结构。如果让 Terascale 在 OpenCL 内核中从内存获取数据,编译器会发出顶点获取或纹理采样子句。主要的 L1/L2 缓存是只读纹理缓存,因此写带宽表现不佳。
GCN 使缓存层次结构现代化,缓存设置类似于 GPU 上现在有的布局。主要的 L1/L2 缓存得到写入支持。所有缓存中的标准 64 字节缓存行,可以轻松实现与 CPU 的数据共享。它们还是虚拟地址,只要缓存命中,TLB(转换后援缓冲)未命中就不可能发生。缓存延迟和带宽数字相较于 Terascale 都得到了显著改善。在 28nm 制程时代,GCN 使 AMD 在带宽方面取得了很大的领先优势。这与 40nm 制程时代相反,那时 Fermi 通常比 Terascale 显卡具有更高的带宽。
随着 AMD 继续迭代 GCN,缓存层次结构得到了进一步的现代化。在 GCN 第三代中,只读标量缓存获得了写入支持。Vega 在 GCN 第三代之后问世,并将命令处理器和渲染后端置于 L2 之前。这有助于减少 L2 刷新并提高写带宽。

来自 AMD 关于 RDNA 架构的演示
尽管经历了重大变革,但 Terascale 的部分遗留特性仍然存在。四个计算单元共享指令和标量缓存,有助于减少芯片上用于缓存的面积。这与 Kepler 的方法形成了鲜明对比,在 Kepler 中,设计师全力打造每个 SMX 的缓存。部分原因在于,像与同时代的英伟达竞争产品一样,GCN 保持了非常高的计算密度。
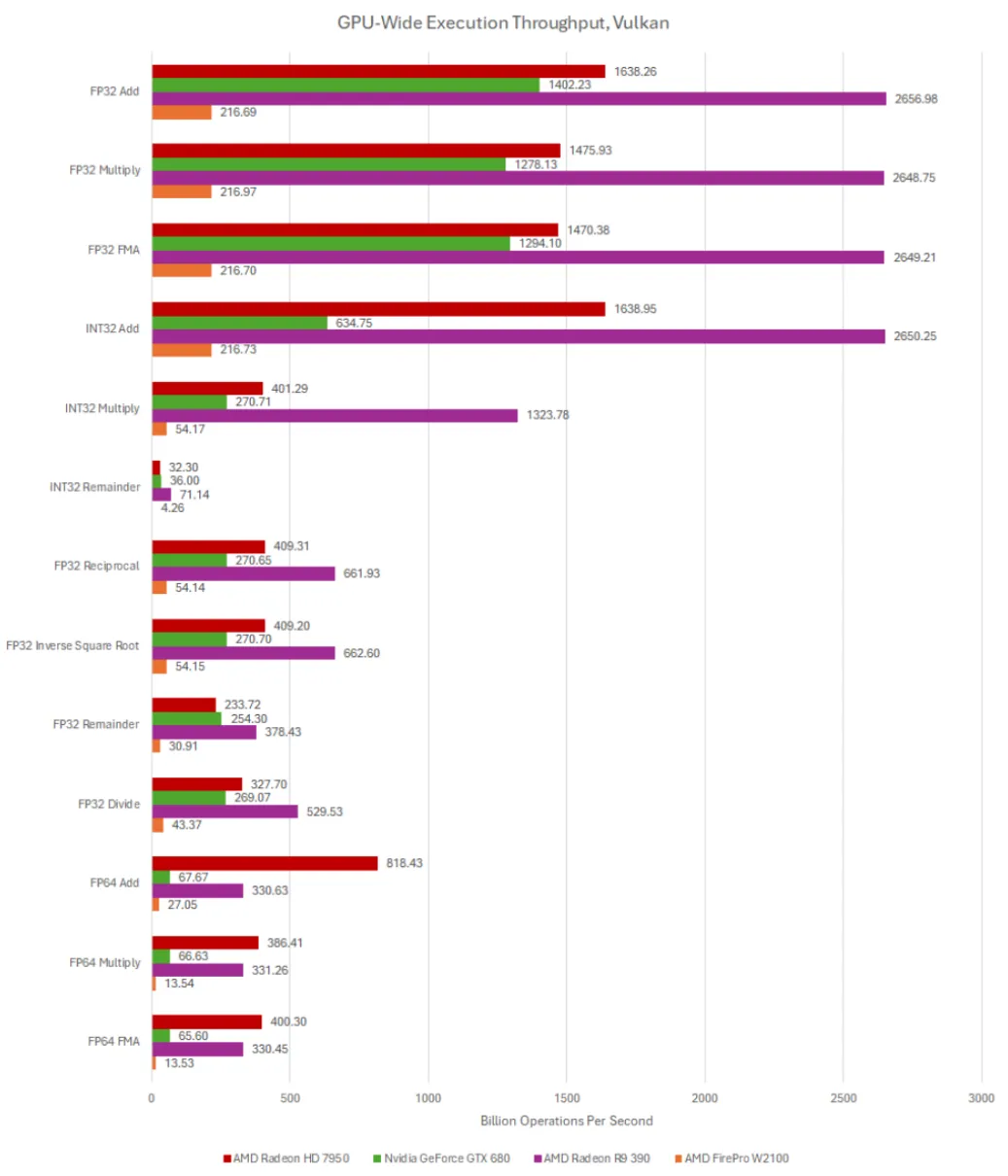
计算性能(VkFFT)
VkFFT 在多个不同的 GPU 计算 API 中实现了快速傅里叶变换(FFT)。它是一个现代且目前仍在维护的项目,2010 年代初期的 GPU 在完成完整基准测试时可能会遇到困难。但是每个平台都可以通过前几个子测试,有足够的数据展示 GCN 的计算潜力。VkFFT 可能受内存限制较大,而 GCN 的大容量内存总线使其表现出色。

HD 7950 在与 GTX 680 的对比中表现出色。Hawaii 架构的 R9 390 扩大了该优势。VkFFT 还会输出预估的带宽数据,这些数据展示了庞大的 512 位 GDDR5 总线所能带来的性能。

等一下,Oland 使用 128 位 DDR3 总线在这里是怎么回事?
遗憾的是,Tesla K80 无法参加 Vulkan 基准测试,因为无法让 Vulkan 在该云实例上工作。幸运的是,OpenCL 几乎可以在所有设备上运行,而且 VkFFT 也可以使用它。
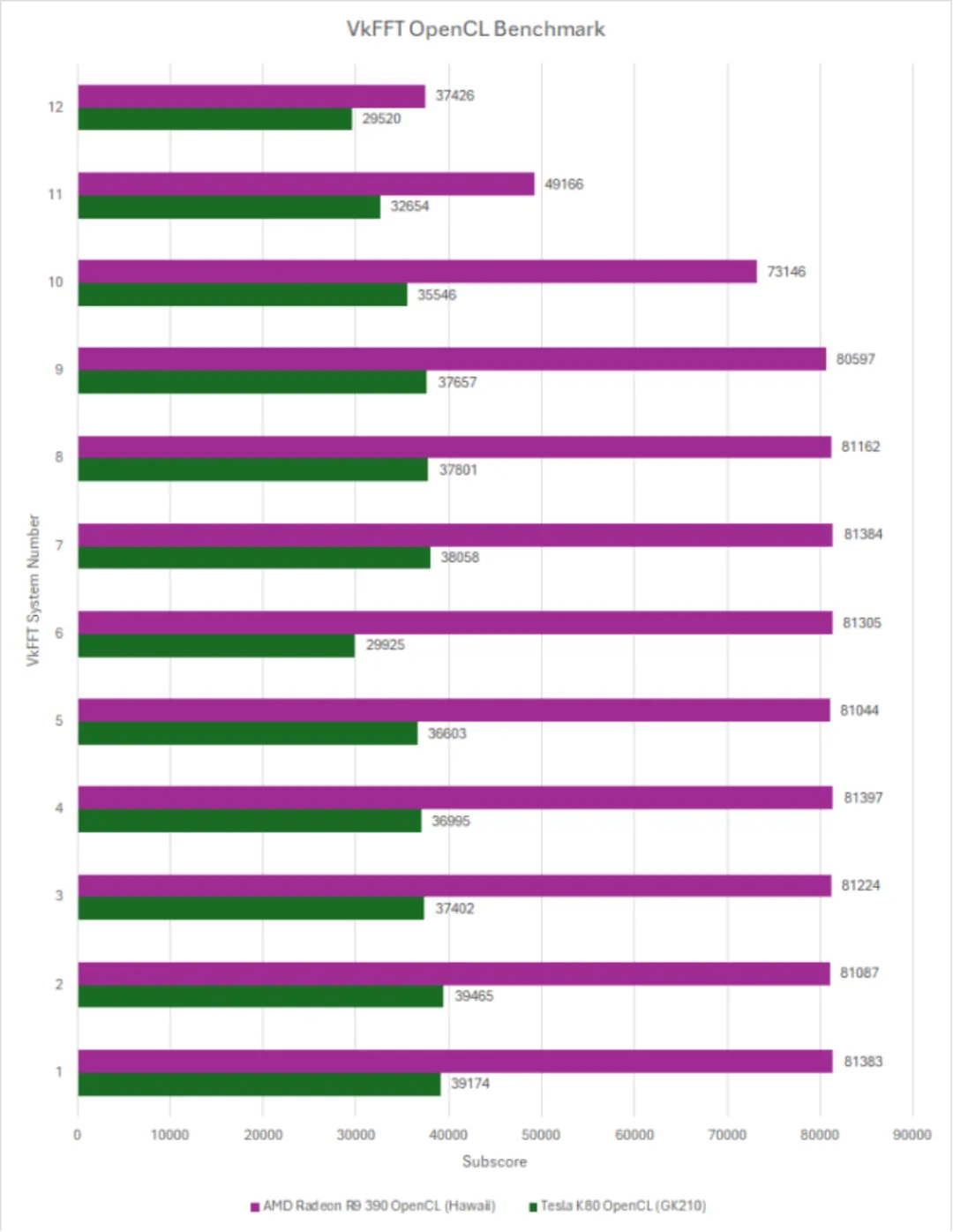
当大型 GCN 与大型 Kepler 对决时,GCN 极高的计算密度和高内存带宽使它在每个子测试中保持领先。GK210 的 384 位总线被 Hawaii 的 512 位总线超越。最重要的是,Hawaii 的频率也更高,略高于 1 GHz。Tesla K80 的运行频率约为 875 MHz,因为 GK210 芯片必须适应 150W 的功耗范围。

VkFFT 的预估带宽数字再次展示了 GCN 在带宽方面的优势。Tesla K80 的每个 GK210 芯片只有 240 GB/s 的理论带宽,而 R9 390 的理论带宽为 384 GB/s。VkFFT 在 RDNA 2 上进行分析时并不支持缓存,RX 6900 XT 的 4 MB L2 几乎没有任何命中。K80 和 R9 390 很可能处于类似的情况。
关于图形性能的一点说明
对于某些计算工作负载,GCN 的计算密度和高内存带宽可以让它在与英伟达 Kepler 架构的竞争中大幅领先。然而,在图形负载方面可能是另一番情况。GCN 的大规模着色器阵列在具有较长持续时间的大规模工作负载上表现出色。一些图形工作负载,比如全屏像素着色器,就属于这一类。然而,较小的工作负载可能会让 Kepler 占据优势。

处理简单几何图形的顶点着色器等小型工作负载对任何 GPU 来说都具有挑战性,但 GCN 比 Kepler 的表现更糟
相对于计算,Kepler 在固定功能图形硬件上花费更多的面积。GK104 拥有四个光栅化分区,每个分区有两个 SMX。如果 Kepler 保持与 Fermi 相同的光栅化吞吐量,每个光栅化器每时钟周期可以处理一个图元并输出 8 个像素。为了实现 Kepler 完整的计算吞吐量,每个 SMX 需要为其四个调度分区中的每一个分配至少一个波。在没有小三角形吞吐量损失的前提下,损失光栅化器可以在 32 个周期内创建访问 Kepler 所有计算潜力所需的最小像素工作量。Kepler 每个 SMX 调度分区的全部占用(每分区 16 个波)至少需要 512 个周期才能达到。
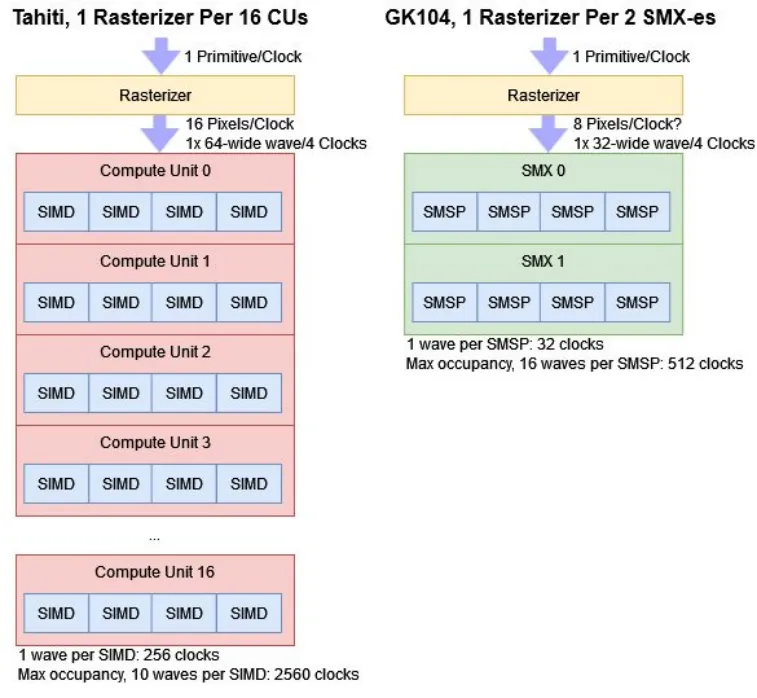
Tahiti 有两个光栅化器来为一组 32 个计算单元(CU)提供输入,即每 16 个计算单元有一个光栅化器。每个光栅化器每时钟周期可以处理一个图元,并在每四个周期内创建一个 64 宽的像素工作波。与 Kepler 的 SMX 类似,GCN 的计算单元需要为每个 SIMD 分配至少一个波,以实现完整的吞吐量。光栅化器需要 256 个时钟周期来实现这一点。达到最大占用率需要 2560 个时钟周期。
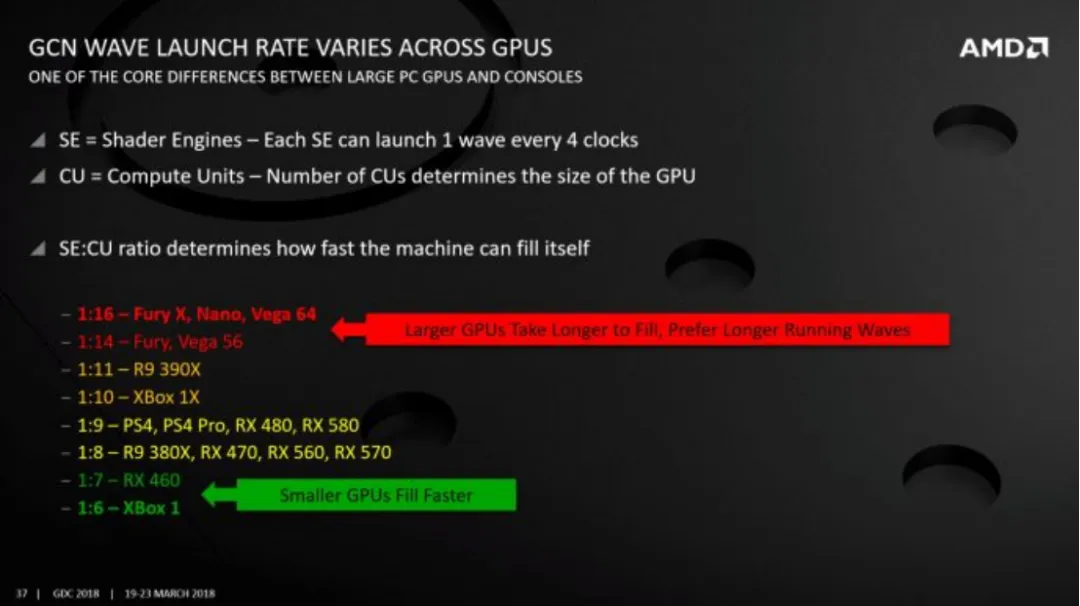
来自 AMD 的 GDC 2018 的演示. GK104 Kepler 的「SE:CU」比例式 1;2
Hawaii 通过增加到四个光栅化器来改善这种情况。对于每个光栅化器的 11 个计算单元,第二代 GCN 可以在 176 个周期内实现每个 SIMD 一个波,以及在 1760 个周期内实现完全占用。然后,像 Vega 64 和 Fury X 这样的更大型 GCN 实现再次扩展了着色器阵列,将 SE(Shader Engine)与计算单元的比例恢复到 1:16。
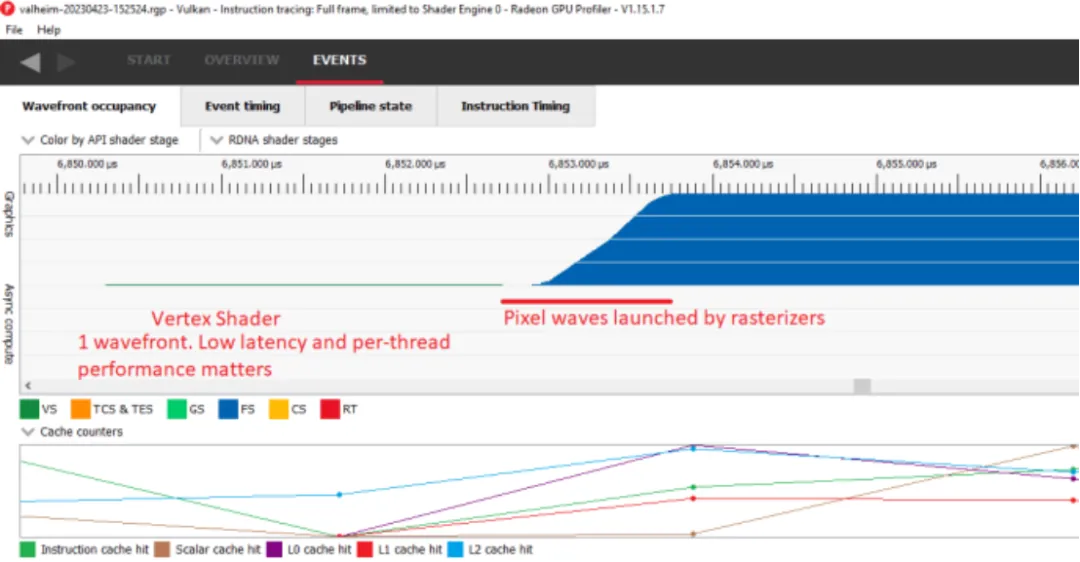
放大在 6900 XT 上运行的瓦尔海姆的 RGP 配置文件,显示了光栅化器填充着色器阵列时的延迟。同样的情况也适用于 GCN,但 GCN 应该更糟
每线程性能是另一个问题。图形渲染可能涉及具有有限并行性的序列。与 Terascale 相比,GCN 可能提供更为稳定的每线程性能。但是,Kepler 可以为单个线程提供更多的执行资源,这在具有大量小型绘制调用的序列中非常重要。
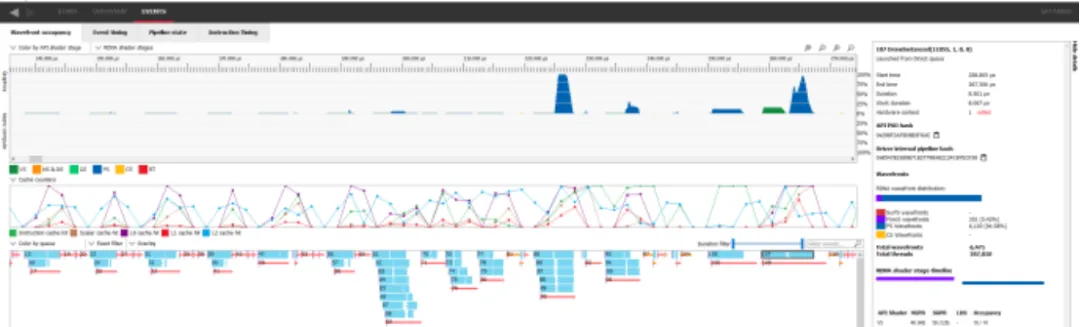
放大观察在 6900 XT 上运行的 Cyberpunk 2077 剖析,显示具有有限并行性和短周期的小型绘制调用。在这类序列中,Kepler 应该优于 GCN。
因此,高端 GCN GPU 通常在较高分辨率下表现良好。渲染更多像素意味着更多的并行性,这使得线程启动速率和每线程执行时间相较于 GPU 的整体吞吐量变得不那么重要。
写在最后
GCN 是一个完全现代化的架构。该设计的调度、执行单元布局和缓存设置与 RDNA 3 和英伟达的 Ada Lovelace 具有更多共同点,而不像其直接前身 Terascale 3。与最近的 GPU 一样,GCN 的设计在计算和图形方面都具有很好的定位。然而,AMD 侧重于计算的转变并未取得成功。与英伟达的生态系统优势相比,GCN 的通用设计并没有太大意义。CUDA 在 OpenCL 之前成熟,并附带一套预优化的库。更糟糕的是,GPU 计算在消费者领域并未蒸蒸日上。游戏性能仍然是最重要的。

MSI 的 R9 390 使用双槽冷却器和五个热管来冷却 Hawaii 芯片
在 2010 年代初至中期,光栅化图形继续主导游戏市场。AMD 在 Hawaii 中扩展了 GCN 的工作分配硬件,但英伟达在 Maxwell 和 Pascal 中取得了巨大的提升。GCN 在性能和能效方面仍然难以与之匹配。

AMD 希望您编写计算着色器
虽然这对 2012 年的 AMD 来说可能没什么慰藉,但现代趋势已经证实了 GCN 设计的合理性。固定功能图形硬件仍然重要,但游戏已逐渐趋向于使用更多的计算。光线追踪是一个广为人知的例子。光线追踪基本上是一种计算工作负载,它不使用光栅化器。然而,即使没有光线追踪,计算着色器也在现代游戏中悄然发挥着更大的作用。现代设计采用了 GCN 设计的一些元素。RDNA 保留了标量数据路径,并使用了类似的指令集。英伟达在其 Turing 架构中加入了标量路径(称为统一数据路径),并将其保留在后续设计中。
如今,得益于更高的显存容量,HD 7950 比 GTX 680 更具可用性。GCN 的设计也更倾向于大型、长时间运行的内核,因为这可以让 GCN 的大型着色器阵列更好地发挥作用,同时减轻了光栅化器快速启动波前来填充它的压力。这使得 Tahiti 更有能力应对新游戏带来的更高着色器工作负载。R9 390 也是如此。几个月前,我收到了一位朋友的朋友不再使用的这款显卡,但这并不是因为这款显卡性能不足。相反地,这款 R9 390 为他效力的时间太长,以至于散热膏都已经干掉,导致性能极度降低。