






 技术咨询
技术咨询 代买器件
代买器件 商务客服
商务客服 研发客服
研发客服从人机交互、语音交互的角度来划分智能座舱等级,可分为:L1车机智能、L2全车智能、L3情感智能、L4数字生命、L5灵魂伴侣五个等级。
2023年12月13日,在2023第五届智能座舱与用户体验大会上,思必驰智能汽车事业部研发总监甘津瑞谈到,从最初的车能“听到”,到后来的车能“理解人”,再到未来的车能“理解你”,以及最终的车“为你服务”,每一个等级的提升都与自动驾驶等级的提升相一致。
目前,智能座舱的语音交互与自动驾驶程度一致,正处于L2阶段。甘津瑞表示:“要达到L3,我们仍需面对几个挑战。首先,需要解决情感化输入的口语理解问题。其次,需要解决情感化输出的NLG生成问题,以及当前的人为设计的可穷举的情感交互问题。这些问题在大模型面前似乎轻而易举,因此大模型有望为智能座舱的交互体验带来颠覆性提升。”

甘津瑞 | 思必驰智能汽车事业部研发总监
以下为演讲内容整理:
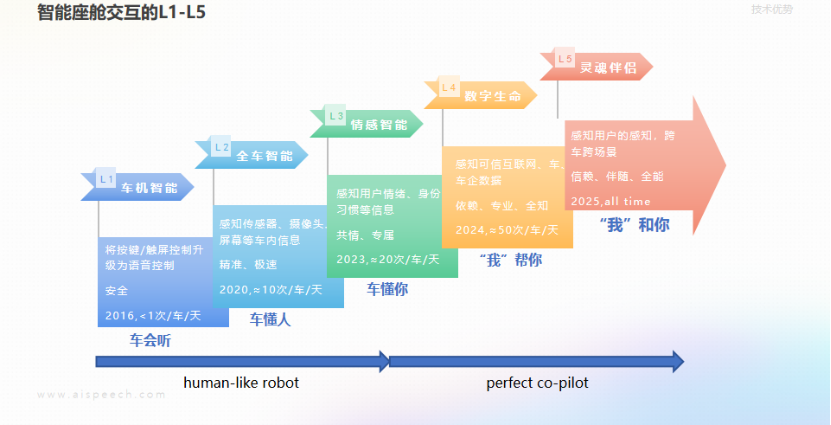
智能座舱交互的L1-L5
从人机交互、语音交互的角度来划分智能座舱等级,可分为:L1车机智能、L2全车智能、L3情感智能、L4数字生命、L5灵魂伴侣五个等级。从最初的车能听到,到后来的车能理解人,再到未来的车能理解“你”,以及最终的车为你服务,每一个等级的提升都与自动驾驶等级的提升相一致。在交互过程中,需要融合的信息和参与决策的参数都在大幅增加,相应的底层核心能力、基础算法、工程架构以及算力需求也是指数级提升,对交互体验来说,也是颠覆性的提升。
图源:演讲嘉宾素材
在未来的L4和L5阶段,智能座舱需要处理海量数据的强大能力,需要依靠大模型的超强推理能力和插件化能力来完成体验的提升。大模型擅长于沟通万物、打理万事。在这个阶段,所有的信息和能力都将被原子化,并以插件的形式提供。例如,当前使用的小模型以及各种生态,如互联网、物联网和车联网,都将以原子化的能力参与大模型的决策和信息抽取。
智能座舱当前处于哪个阶段?与智能驾驶一样,目前智能座舱处于L2+的状态。大家都在努力往L3的情感智能阶段进行突破。
要达到L3,目前仍需面对几个挑战。首先,需要解决情感化输入的口语理解问题。其次,需要解决情感化输出的NLG生成问题,以及当前的人为设计的可穷举的情感交互问题。这些问题在大模型面前似乎轻而易举,因此大模型有望为智能座舱的交互体验带来颠覆性提升。这已经成为大模型在智能座舱中的行业共识,同时,也必须面对一些实际落地过程中的挑战和难点。首先,通用大模型在俯身进场下会出现水土不服的情况。例如,当大模型接到车上,可能会出现设计出来的场景不够“刚”或大模型速度较慢的问题,或者用户体验可能与网页上的体验存在差异,以及在L2阶段遇到的痛点似乎还未得到解决。
另一个挑战是在落地过程中遇到的困境,比如说用户注意力受限下的场景围栏。基于我们的统计数据,不管大家在L2阶段怎么推陈出新,高频使用场景始终是车控、导航、音乐和天气等几个方面。随着智能驾驶L3的到来,用户驾驶过程中的注意力将得到释放。新的高频场景,如娱乐诉求、工作诉求以及一个人开车时的交谈诉求将涌现出来。
此外,大模型的到来将对智能座舱的质量体系提出挑战,即怎么能够客观地认定这个版本的语音交互是能够达到量产水平的。随着新场景的涌现,不能再像以前那样对每个功能进行全量测试。随着娱乐场景、工作场景带来新的诉求,例如对于车载会议的需求,我们需要重新设计一个测试体系来判定车载会议的体验是否良好。
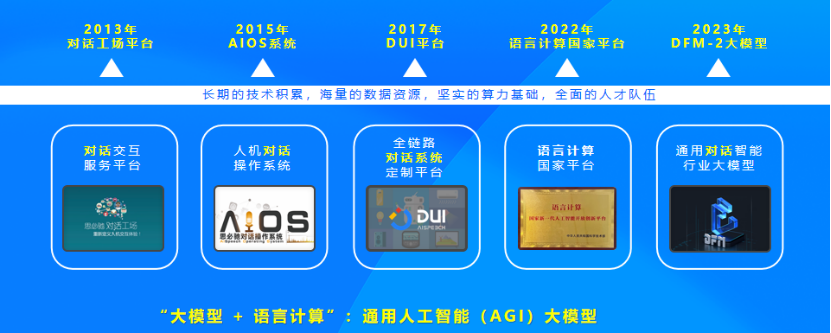
思必驰及DFM大模型
在此背景下,我向大家介绍思必驰,以及我们今年推出的DFM大模型。近十年,思必驰一直专注于对话式AI平台的建设。基于我们自主研发的全链路语音交互技术,思必驰已成为行业里坚持对话式AI交互的供应商之一。自2017年发布DUI平台以来,近六年的时间里,我们不断地在整个全链路各个环节开放定制化、差异化的能力,为多家车企提供覆盖感知层面、认知层面以及知识图谱层面等的支持。
图源:演讲嘉宾素材
今年,我们发布了DFM-2大模型,这是一个具有通用智能且针对垂直领域的行业语言大模型。在各种客观评测中,该模型在百亿级大模型性能方面处于领先地位。
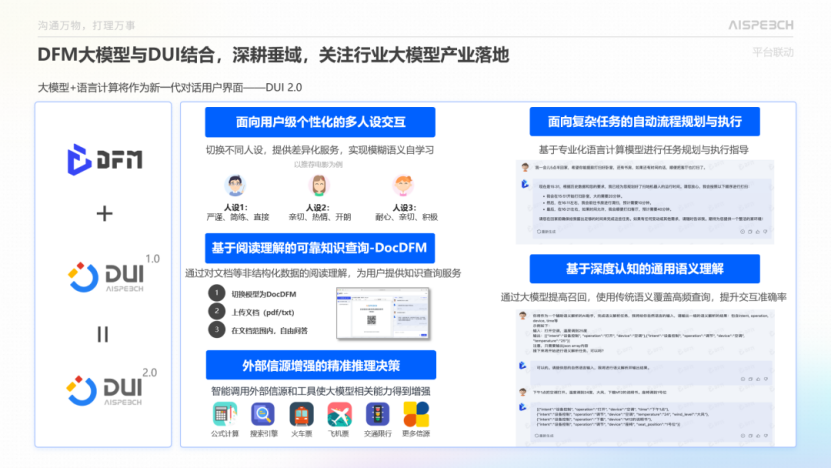
基于DUI平台和DFM-2大模型,我们正在进行一系列创新优化。目前,我们正在使用DFM-2大模型全面升级DUI的每一个算法链路,实现从面向车企的差异化定制到面向车主用户级的差异化定制的升级。
新一版的DUI2.0平台,我们将开放以下五个关于大模型的定制化能力:包括外部信源增强的精准推理决策、基于深度认知的通用语义理解、基于文档理解的可信主动知识问答、面向用户个性化的多人设交互、面对复杂任务的自动规划与执行。
图源:演讲嘉宾素材
为了确保大模型以及人机交互方案,从设计阶段到最终量产阶段、以及后续OTA阶段的顺利推进,我们将开放全链路的定制、快速训练、效果评估以及持续优化的平台给车企,帮助他们实现快速且质量保证的平台建设。
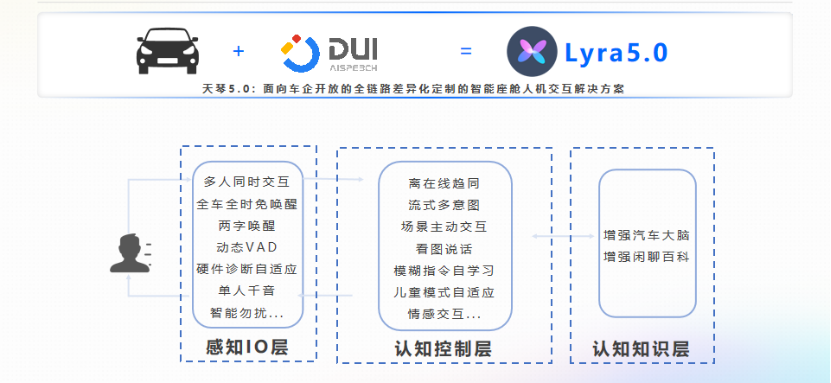
大模型上车,智能座舱体验升级
今年是天琴5.0批量量产的一年。在天琴5.0中,我们为车企提供了覆盖感知层、认知层和知识体系层的新功能。例如,多人同时交互、全车全时免唤醒、动态VAD、两字唤醒以及语义层面的离在线趋同、流式多意图、主动交互等。
图源:演讲嘉宾素材
即将首发量产的天琴6.0是基于5.0版本,结合大模型技术使大模型快速上车的一个版本。天琴6.0将融合大模型的六大能力,实现快速赋能车载人机交互的解决方案,具体包括以下方面。
出行场景。在导航需求的基础上,利用大模型的赋能实现更复杂的出行规划功能,形成个性化的出行方案。在出行规划过程中,我们将打通导航、天气、网络资源等多源信息,为用户提供综合性的解决方案。
关怀场景。通过在输入维度增加用户信息和车内外多维度信息,利用大模型的预测能力实现情感化的交互关怀体验。我们将根据用户需求和情境,提供更加贴心和个性化的关怀体验。
多人设。天琴6.0将突破传统的“固定模式化人设”设定方式。基于用户输入的各种维度和任务需求,通过大模型进行综合决策并生成不同的NLG结果,甚至调用不同的TTS音色来达到更加多元化和自由化的人设效果。这将使用户能够根据自己的喜好和需求进行个性化设置,提升语音交互的个性化和用户体验。

图源:演讲嘉宾素材
大模型下的多意图。在天琴5.0我们推出流式多意图的亮点功能,在天琴6.0中会升级为大模型多意图,基于实测场景进行更加复杂任务的定制。例如,之前的自定义指令需要用户在车机或手机上设定条件和执行动作。在大模型加持下的多意图将实现更加智能的任务设定,用户只需要简单说出自己的需求和条件,系统就能够自动进行设定和任务管理。这将大大简化用户操作流程并提高语音交互的智能化水平。
在“汽车大师”这一部分,我们的升级版综合了汽车售前、售中、售后的知识体系,构建了汽车领域的百科专家。确保车主在任何情况下都可以通过语音交互获取车辆使用相关的各种信息。
DFM大模型赋能的未来天琴
天琴6.0方案是为了迎接智能座舱L3等级的到来而设计的,同时我们也为L4和L5做了量产规划。在天琴7.0阶段,大模型将在整个链路上全面深度参与人机交互。
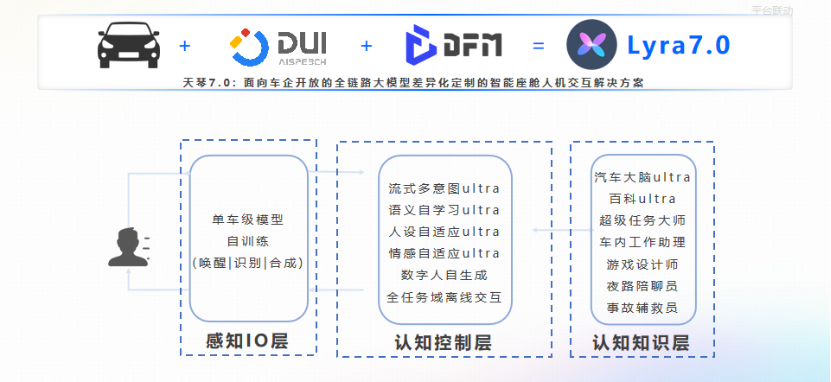
图源:演讲嘉宾素材
在感知IO层,我们之前使用的是在本地运行的模型,如唤醒、本地识别、本地合成。每个车型都需要进行深度的差异化定制以保证良好的用户体验。然而,在7.0阶段,我们将利用DFM大模型作为小模型的训练师,使每台车、每个用户的模型都是独一无二的。在过去,为每个用户定制一个模型的想法代价是巨大的,因为标注和实现成本相当高。但有了大模型之后,用户级、单车级的模型自训练逐渐成为现实。
在认知控制层,大模型也将全面改造流式多意图、语义自学习、人设自适应和情感自适应。在6.0方案中,大模型在一定程度上参与了自适应能力,实现了用户的差异化体验。而在7.0中,整个语义层面都实现了用户级的差异化自适应,这意味着人机交互中再也不会出现“对不起,我听不懂,请再说一遍”这样的情况。“数字人自生成”也突破了以往的规则限制,更自由地生成NLG动作和语调等。
“全任务域离线交互”核心在于大模型的领域或场景需要用到云端的能力,那么我们把常规L2常用的导航、天气、车控等都放在SOC上离线运行,这样就把这部分算力空余给了大模型,使其能够支持更大的并发,并降低车企在大模型落地过程中的成本。同时,基于用户对隐私安全的强烈诉求,全领域离线交互的支持意味着即使车主非常介意隐私数据上云的程度,他们也可以在拒绝隐私协议的情况下进行全任务域的交互而不受影响。
在认知知识层面,大模型的作用更加显著。例如,以后大模型可以化身为“超级任务大师”和“车内工作助理”,甚至是“游戏设计师”“夜路陪聊员”和“事故辅救员”。这些只是基于自动驾驶L3出现的新场景所做的针对性设计。当然,我们也会通过DUI平台的全链路开放定制能力,为各个车企和客户提供不断设计新场景的机会,探索与自己的用户群体更贴近、更能激发他们使用频次的场景设计。
相关文章









