






 技术咨询
技术咨询 代买器件
代买器件 商务客服
商务客服 研发客服
研发客服1、概念上的误解
我们知道DMA传输是在DMA请求下,将数据从源端传输到目的端。
常有人将DMA请求跟DMA的源端或目的端混为一谈。这里,我们可以将DMA传输类比成收发快递,发件方即DMA源端,收件方即DMA目的端,而DMA请求端就是呼叫快递的人。这个呼叫快递的人可能是发件方、也可能是收件方,还可能是另外第三方。比方你要发个快递,叫快递的人可能是公司的前台美眉。
具体到我们STM32应用,比方通过DMA将内存数据传输给UART DR寄存器发送出去,源端是存储相关待发送数据的内存区域,目的端是UART DR数据寄存器。至于DMA请求,可以是UART发送空事件【TXE】,也可以是定时器的某个周期性触发事件等。
在STM32各个系列的参考手册的DMA章节部分,都有类似如下的DMA请求映射表。表格里填写的都只是针对各个DMA传输流的DMA请求事件,并非一定是源端或目的端。当然,不排除作为源端或目的端同时又担当DMA请求角色的可能。

2、配置上容易忽视的问题
我们在做DMA配置时,比较容易忽视两个小问题。第一个就是源端和目的端的数据宽度的定义问题,除了考虑配置满足实际需要的数据宽度外,还要注意将源端、目的端二者数据访问宽度配置一致。不然的话,往往会导致些奇怪的问题。
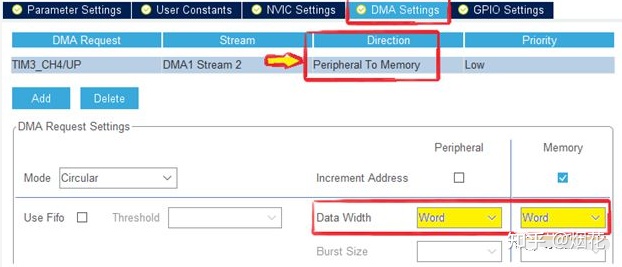
还有,就是要注意DMA的传输方向别弄错了,到底是PERIPHERIAL到MEMORY还是MEMORY到PERIPHERIAL或者说是Memory到Memory要配置正确。尤其是在用CubeMx配置时,这里有个默认配置是PERIPHERIAL到MEMORY。如果说你的真实意图根本不是从PERIPHERIAL到MEMORY,而你无意中使用了这个默认配置,结果可想而知,DMA传输根本没法正常运行。我前两天就被这个地方折腾过,用定时器触发DMA输出任意周期性的PWM波,白白多耗了近2个小时。此时,在调试环境里想强制使能相关DMA Stream的传输都不行,整个就不工作。

类似配置方面的小细节要多加注意,忽略了那些往往会累死人。
3、DMA传输作用范围问题
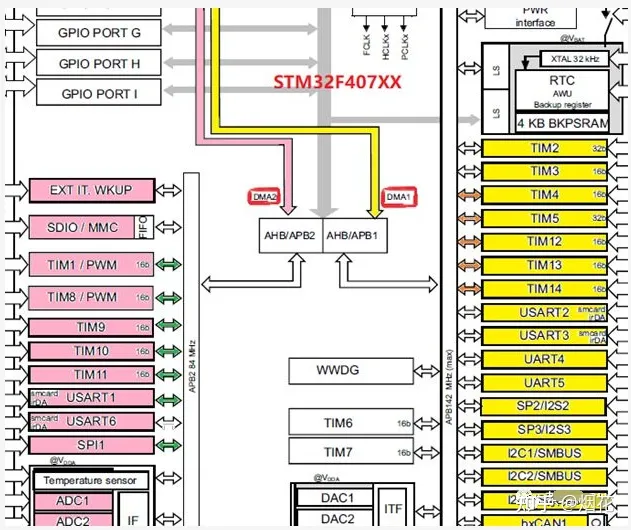
前面将DMA传输类比成发快递,发快递时,快递公司一般也没法无处不到,那DMA传输也有同样的问题,各个DMA模块往往有各自的服务范围。比方以下图STM32F4的一个框图为例。DMA1可以轻松访问右边黄色标注出来的外设,DMA2可以访问左边分数标注出来的各个外设。如果我们在程序里的DMA配置部分,将DMA1的源端或目的端安排为左边的粉色标注出来的外设、或者将DMA2的源端/目的端安排为右边的黄色标注出来的外设,结果一定会让你失望。因为你期望它访问它到达不了的地方。
这个地方比较隐蔽,因为我们在代码里只是根据DMA请求自行指定源端和目的端,有时会忽视所用DMA的服务范围。前面提过,各个STM32系列参考手册里DMA章节部分都有明确的基于各路DMA传输流的DMA请求事件源的描述和展示,但并未指定基于各个DMA请求的源端或目的端。所以我们在基于某个DMA请求来自指定源端或目的端时,一定注意你安排的源/目的端是不是该DMA可以到达的地方,具体要结合手册中功能框图和总线访问架构图。
比方说,下图是STM32F7系列一个总线访问框架图。不难看出,DMA1是访问不了AHB1外设和AHB2外设的。当然,DMA2访问AHB1外设和AHB2外设又没有问题。

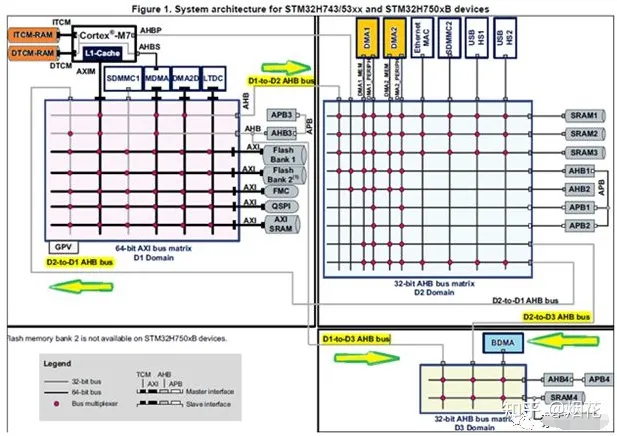
再比方,下图是STM23H7系列一个总线访问框架图,其中BDMA是没法访问D1域或D2域的外设及内存的。D2域的DMA1/DMA2没法访问D1域中的DTCM/ITCM。D1域中的MDMA没法访问D2域中的AHB2外设。
关于这些总线框架性的东西,在我们的STM32应用中也要多加关注。比方有时在做通信数据传输时发现,使用中断没问题,用DMA就失败。这时不妨查看下DMA访问的外设或内存区域到底是不是它所能访问得到地方,如果不是就需要适当调整下。
4、跟DCache有关的问题
该问题往往跟我们使用带cache的M7内核的STM32F7或STMH7系列芯片有关,使用DMA传输时有时会遇到DMA访问到的数据不是实时的正确数据。这往往可能是因为DMA要访问的内存区域,跟CPU是共享的,同时又开启了相关区域的D-Cache属性,即CPU访问该内存区域数据时使用D-Cache,将内存数据拷贝到D-Cache。之后,CPU访问相关数据时往往只在Cache里进行。
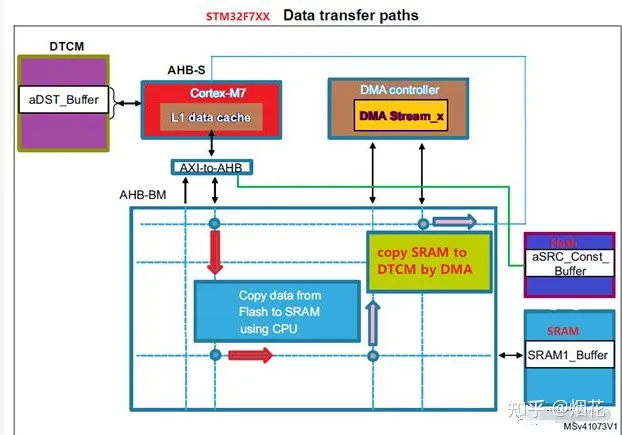
比如下面的一个基于STM32F7芯片的经典示例。首先CPU从flash里拷贝128字节常量数据到片内SRAM,然后通过DMA将SRAM里的这128字节数据拷贝进DTCM内存区。最后通过CPU将DTCM里的数据跟FLASH里的原始数据进行比较,这时会发现比较结果是二者内容根本不一致。
这是因为开启了SRAM的回写的Cache属性,第一次将数据从flash拷贝进SRAM过程中,数据还没有真正写进SRAM,还只是放在了Cache。当我们通过DMA将SRAM相关区域的数据拷贝进DTCM内存区时,并没有将真正的来自FLASH区的数据拷贝过去,导致最后的数据比较失败。
像这种情况下,我们可以有几种方案来解决这个问题:
1、在做将数据从SRAM拷贝到DTCM区之前,先做个D-Cache的清除操作【SCB_CleanDCache()】,将D-Cache里的数据写回到实际存储区SRAM里。
2、我们可以通过MPU设置SRAM区域的MPU属性,将其回写的Cache属性【writeback】调整为透写的Cache属性【writethrough】。
3、配置SRAM的MPU属性为shareable共享属性,令CPU访问它时不使用D-Cache.
4、将所有涉及到具有Cacheable可缓存属性的存储区域,都使用透写策略。这点可以通过配置M7内核相关控制寄存器位实现。
再举个实例,使用STM32F7芯片做UART的通信数据接收,UART接收到数据后触发DMA,DMA将数据从UART_DR寄存器拷贝到片内SRAM,CPU再从相应的SRAM区取走数据送到某LCD显示设备显示输出。这时,你很可能会发现一个奇怪的现象,显示设备输出的数据永远都时第一次接收到的数据,不管UART的发送方任何改变发送数据,显示出来的数据就是不变,只是跟第一次发送出来的数据相比是正确的。这是怎么回事呢?

原因是因为开启了SRAM的D-Cache属性,CPU第一次从SRAM读取数据后,同时又将数据放到D-Cache里,后面再来读取SRAM相应地址数据时并没有前往SRAM,而是直接区D-Cache里提取数据,从而导致每次显示出来的数据总是第一次接收到的数据,尽管UART那边后续接收的数据在不停变化,但并没有对D-Cache里的数据做同步更新。
这时我们可以在CPU读取SRAM数据前做个D-cache的清除操作,让实际存储器数据与D-Cache里数据同步更新,或者做D-Cache的失效操作,让CPU无视D-cache直接从SRAM区读取数据,或者说通过MPU配置禁用该SRAM区的Cache属性。当然,最终你选用哪种策略,得结合你的实际应用来定。