揭秘第五代至强:为什么它是最好的AI处理器?
要说现在领域最热闹,那一定是AI。全球各种不同的调研结果都显示,58%的企业在非常近的未来都会导入如生成式AI到他们的生意模式当中。预计2026年有超过3000亿美金将投入到生成式AI当中,而其中有50%以上的边缘应用也会采用AI技术,此外,到2028年有80%以上的PC都会转换成AIPC。
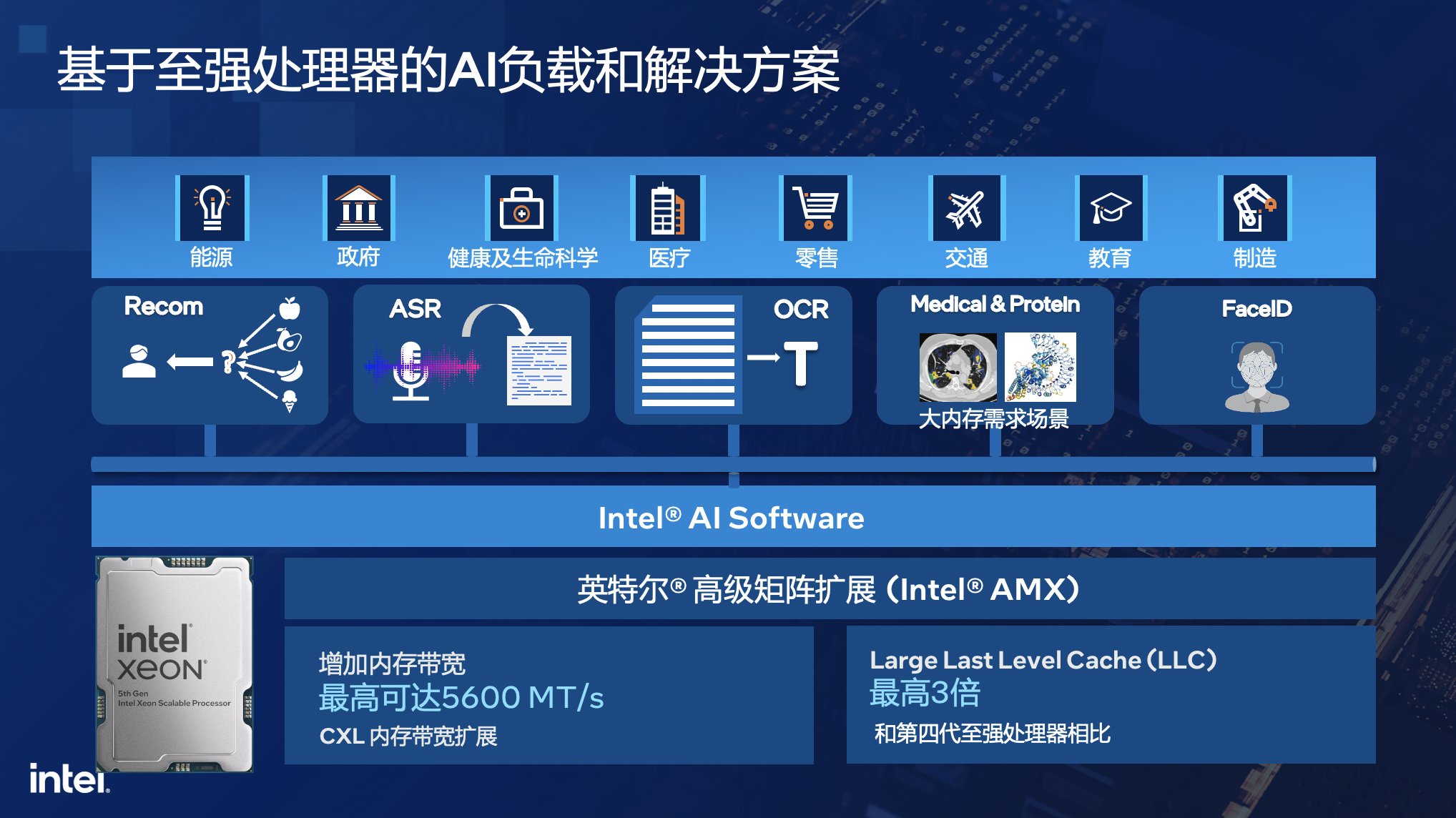
这样的背景之下,英特尔发布了第五代英特尔至强可扩展处理器,这款产品不仅在性能指标上有很大提升,在AI性能上也非常强劲。
根据英特尔市场营销集团副总裁、中国区数据中心销售总经理兼中国区运营商销售总经理庄秉翰的介绍,第五代至强在AI训练、实时推理、批量推理上,基于不同的算法,都可以看到不同性能的提升,最高可提升40%。
此外,第五代至强从性能上都可以满足生成式AI大模型的要求, second token可在100毫秒内生成,甚至是60~70毫秒或是20毫秒。
更重要的是,超强的AI性能已经得到了诸多客户的验证,比如说百度云实践证明使用第五代至强,在Llama2 70B参数的模型下,通过一个四节点的服务器,可以达到87.5毫秒的推理结果。再比如,京东基于第五代至强和前一代的处理器相比,在Llama2 13B的模型上,看到有50%的性能提升。又比如,很多OEM伙伴已推出基于第五代至强的一体机,在7B、13B到34B的大模型推理上,完全可以满足大参数大模型的条件。
合作伙伴认为,在全盘考虑部署和运维成本等因素后,一般企业导入基于至强的生成式AI服务,如聊天机器人,或是知识库问答这种基础的大模型比基于服务器的云服务初期导入成本低一半左右。

那么,第五代至强是如何实现这样的AI 性能提升的?日前,英特尔资深技术专家揭秘了其内部的技术细节。
五点架构改进
许多人好奇,从第四代至强到第五代至强,产品之间存在哪些差异。根据英特尔资深技术专家的解析,主要分为五个方面——制程技术改进、芯片布局、性能与能效、末级缓存、内存IO。
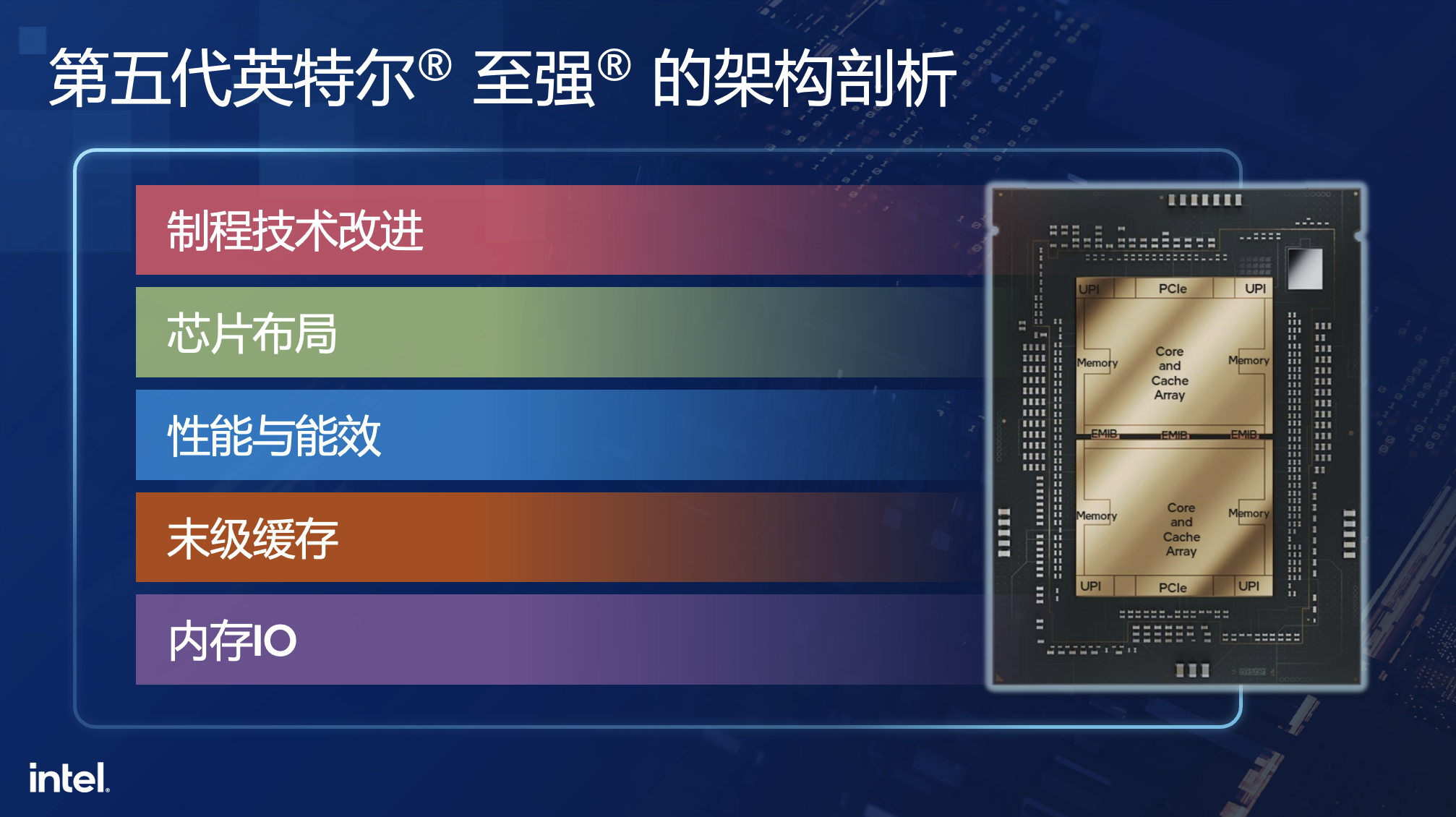
第一,制程技术改进。制程是半导体领域离不开的话题,第四代和第五代至强都是基于Intel 7的制程,该工艺采用了Dual-poly-pitch SuperFin晶体管技术。
从第四代至强到第五代至强,英特尔在关键的技术指标做了改进,特别是在系统的漏电流控制和动态电容方面,这两方面的指标都对整个晶体管的性能表现有比较大的影响。通过这些调整,整体上第五代至强在同等功耗下的频率可以提升3%,其中有2.5%由漏电流控制贡献,动态电容下降贡献了0.5%。
第二,芯片布局。现阶段,大家对服务器算力要求越来越高,因此需要在里面放更多核心,以及更多内存带宽,但更多的内存带宽意味着有更多的IO。这些都在推动芯片面积不断增加,并使得芯片良率会受到挑战,此外单片面积过大,可能会超过光刻机尺寸限制,因此目前主流设计都是将CPU芯片切分成多个子芯片,并用多芯片方式封装在一个芯片内。
第四代至强把芯片分为四个部分,这四个部分是相对对称的。第五代至强切分方式则做了调整,把切四份做法变成了切两份。这样可以解放额外占用的芯片面积,更好地控制芯片面积,增加额外的功耗,同时可以支持在相对更大面积下取得更好良率。
在第五代志强两个切分的芯片间的内部互连英特尔称之为MDF,上下两个芯片有7个利用英特尔2.5D封装技术EMIB(嵌入式多芯片互连桥接)互连的全带宽的SCF(可扩展一致性带宽互连)通路,每个通路有500G带宽。虽然物理上,两块芯片是分离的,但高速互连可以实现无缝连接。
第三,性能与能效。第五代志强的关键性能指标包括:
1.升级到Raptor Cove核心;
2.核心数增加,从最多的60核升级到64核;
3.LLC大小从1.875MB增加到5MB。这个提升是非常大的,因为过去英特尔的LLC基本上在1M-2M。我们第一次在第五代英特尔至强可扩展处理器,把LLC提升到5MB的水平;
4.DDR速度从4800MT/s提升到了5600MT/s;
5.UPI速度从16GT/s提升到20GT/s;
6.SoC芯片拓扑结构更改,4芯片封装改为2芯片封装;
7.通过全集成供电模块(FIVR),待机功耗降低。
能效方面,与第四代至强相比,和整数相关的一系列性能评价指标方面有21%的提升,针对AI负载,性能提升更多达到42%。
第四,三级缓存(LLC)。第五代志强每个模块的LLC容量达到了5MB,所以这款芯片有高达320MB缓存,如果数据集不是很大,大部分数据都可以放在LLC缓存当中,大量减少对内存的访问。而在数据停留在缓存里面和到内存去访问,带来的性能收益比较大。
这并非依靠简单的堆资源,无论是内存还是缓存,更大的面积意味着更多可靠性问题,即软故障或系统宕机。针对这个问题,英特尔在LLC当中采取了新的编码方式,称之为DEC和TED,简单解释就是当缓存行错两位时,可以纠正,出现三位错时,还可以检测,极大提升系统容错性。
第五,内存IO。第五代至强速度从4800MT/s提升到5600MT/s,这并非想象中那样容易,所有的内存速度的增加,都需要在现有的基板和PCB的基础上实现,要达到更高的速度,需要从芯片设计到基板设计及链路上一系列整体提升。
在芯片设计方面,英特尔做了很多优化,包括一些MIM内存、基板走线提升,以及片上的低噪声的供电措施等。4-tap的DFE功能可以把数据采集起来,用来做下一个bit接收的调整,可以尽可能的减少码间干扰(ISI)。那么,不打开DFE和打开DFE,在5600MT/s这么高的速度下,可以带来非常好的信号完整性的表现。
云计算时代,效率为重
事实上,在云计算时代,我们需要“压榨”资源,即效率为重。对云厂商而言,真正的核心竞争力之一在于实例的性价比,因此,效率的提升至关重要。
AI时代,数据中心耗电量极高,一台GPU服务器可达上万瓦的功率,如果未来中国建造越来越多的数据中心,那么可持续性便是一大挑战。其实眼下数据中心的成本当中,电费占据了很大一块。
那么这样的背景下,如何提升能效?有两种方式,一是在前端为客户提供智能,二是自身底层设施的智能化。
从底层端到端,英特尔一直进行优化,而英特尔挖掘CPU能力并非是单一方面。
首先,是在硬件性能上做出更好的效率,从而提升能效。第五代至强可扩展处理器,制程和第四代基本一致,相较于第三代可扩展处理器,在AI推理训练上最高提升了14倍,基础架构的存储能够达到2.8倍,网络边缘可以达到3.2倍,高性能计算能达到3倍,数据分析可以达到3.7倍。
其次,是用软件优化好硬件,从而让能效加倍。在硬件的基础上,英特尔提供很多函数库等,能够将硬件能力极大地发挥出来;在云计算时代在虚拟化技术上,英特尔投入了“重兵”,提升了虚拟化效率同时,也减少了对底层硬件的损耗;在TDP(热设计功耗)方面,英特尔在框架层、函数库层面上挖掘硬件能力,通过API接口调用把底层硬件能力完全应用起来;在系统层、服务器层面上,将CPU、内存,以及网络整合成一个有机的整体。

“未来,底层能源的利用率便是企业最大的优势,谁的能源利用率高,转化率高,谁就更有竞争力。”英特尔资深技术专家这样强调。
科学计算,很多时候就是“暴力”计算,最能验证CPU的处理能力。gatk借助第五代至强可扩展处理器加速科学发现应用,即助力基因测序。自从2018年开始,英特尔每一代处理器针对科学计算的性能均有提升,而这也将助力基因测序快速发展。
被改变的不止是gatk。AlphaFold2模型的特点是参数非常高,GPU放不下,且只能放在主存里。这会导致CPU和GPU频繁交互,所以采用CPU要比GPU快很多,甚至达到几倍的提升。GPU的缓存不够,而通过重度优化CPU之后,将业务切分,并把CPU的核都利用起来,效率相较于GPU反而会更高。

跑AI,CPU也有擅长领域
最近一段时间,GPU缺货涨价,许多客户都在不断压榨CPU性能。事实上,GPU并非是大模型的唯一选择,CPU也有能力做同样的事。
对于业务仍处于起步阶段的公司而言,综合考虑产品是否好购买,以及资源是否能够充分利用的前提下,使用至强做推理,也是一个很好的选择。
CPU一大优势是灵活,无论是业务扩容还是通过分布式快速地获取部分资源,都不受限制。这种情况下,能够为中小企业和中小模型降低整个AI的起建成本。
英特尔在性能测试过程中充分释放了AMX的能力,最终可达到50%成本的下降。这表示我们在提供和GPU相似的延迟,例如小于100ms的同时,可以实现更低的拥有成本更低。
对大模型来说,基本所有计算都是在GPU显存上进行,但实际,很多公司也开始用CPU做编码。GPU的特点是快,但其视频编解码质量略差于CPU。整个工作流程都在CPU侧运行,这样可以减少很多内存复制,并将架构简化。通过AMX-INT8加持,英特尔把吞吐从原来的1.5FPS增强到了33FPS,33FPS意味着可以做实时编码。
除大模型之外,其实CPU还有很强的能力去构建整个流程的应用,没有必要做异构,CPU即可完成所有的工作。
为什么第五代至强这么擅长推理AI?从技术角度来看,第五代至强的硬件特征主要包含两方面:第一,对AI而言就是AMX与AVX-512;第二,内存带宽更强大了,不仅LLC变大了,而且整个内存频率可以支持到5200MHz,吞吐量会变得更高。
最终,正如英特尔所展示的那样,第五代相比第四代英特尔至强可扩展处理器,推理能力可以提升42%。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。