






 技术咨询
技术咨询 代买器件
代买器件 商务客服
商务客服 研发客服
研发客服1 引言
在如今的快速嵌入式系统设计中,目前比较流行的方案是在FPGA内集成应用软件或是软IP平台,以简化工序、加速产品面市日程。为此,很多公司推出了自己的开发平台以及相关CPU的IP核,常见的为两种:一种是通用型CPU,如xilinx和altera公司的32位以及64位通用CPU核;还有就是专用型的,常见的为51系列单片机的CPU核,但是目前关于单片机的软核基本上都是8051的,其他的品种很少。而且8051的速度不是很快,在有些快速的控制场合(如利用单片机来作为usb2.0的控制部件)显得速度不足,比较著名的actel公司推出的Core8051,运行频率也只在40 MHz左右。本文介绍了一个非常高速DS80C320单片机软核的设计。
DS80C320单片机是DALLAS公司推出的一款基于51框架的高性能单片机。
它有如下一些优点:
ⅰ,具有与51系列完全一致的指令系统,能充分兼容所有基于51系列开发的程序;
ⅱ,具有比8051更加齐全的外设。相比8051单片机,DS80C320增加了定时器2以及一个增强型串口等;
ⅲ,具有比8051更好的效率;DS80C320的一个指令周期是4个CLK,8051则是12个,这个区别尤其是在处理简单指令的时候优势明显,例如单周期指令的处理,DS80C320只需要4个CLK,而8051需要12个,据DALLAS公司的统计表明,在相同时钟频率下,DS80C320每条指令的执行速度是8051的1.5~3倍,对于典型的应用程序来说,执行速度也是8051的2.5倍左右。
ⅳ,其读取指令的方式比8051更加适合IP核的特点;将单片机内部ROM去掉,完全从外部读取指令,这种特点作为软核是很适合的,首先是结构简单,有利于指令读取的流水设计,其次可以突破内部ROM大小的限制,最后,作为FPGA设计的特点,即使8051的设计,内部ROM块也是放在FPGA芯片的ROM资源里面,与其这样,还不如直接放到外面更加简化时序与结构;
2 总体结构划分
如图所示为DS80C320软核的总体功能图:
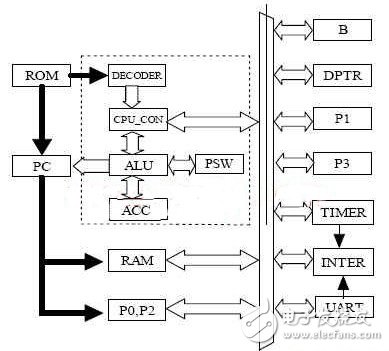
图1 DS80C320功能框图
本IP核的设计主要按照指令执行的流程来安排功能块,并通过数据总线来传递数据;虚线里面的为CPU核心;首先是ROM模块,DS80C320并没有内部ROM,所以该模块功能主要是分析从P端口读取过来的指令,并通过查找指令的长度以及周期数目,从而计算出相关控制信号发送给CPU控制模块以便控制指令的读取;同时,如果指令为LCALL或者ACALL,则可以分析出子程序入口地址并报送PC模块,引导PC正确跳转;在ROM模块分析指令的同时,译码器DECODER也在进行译码的动作,它将根据指令的8位数据分析出三个重要的参数:ALU的动作类型,该指令的操作数据来源以及读取方式,该指令结果的存放位置以及存放方式;第一个参数送给ALU模块,其余两个送到CPU控制模块;CPU控制模块CPU_CON是整个CPU的核心部分,主要完成两个作用:ALU执行前的读取数据控制,以及ALU执行完成之后回写数据控制;该模块同时也控制着整个CPU的时序,监视其他模块的执行情况;ALU则主要是完成计算工作;INteR模块则是中断系统的控制模块,其功能主要完成对各个中断源所提交的中断请求的有效判断以及排序,产生中断标志并且将判断结果以及中断入口地址编码提交给ROM模块,以指示程序跳转,同时还需要负责在中断完成之后清除中断标志以及恢复中断之前的中断等级; DS80C320有三个定时器和2个串行口,其中定时器2和串行口如果不需要的话可以裁减;至于其他的模块或者寄存器则在CPU控制模块的控制下通过数据总线交换数据;可见,本设计的思路是以CPU_CON控制整个CPU的执行以及时序,以INTER控制整个中断系统,其他寄存器则以数据总线来完成数据的交换,均匀的分布在数据总线的两侧,结构清晰简单,规则化的设计也有利于提高速度,以及方便裁减。
3 一些设计特点
3.1时序设计
在DS80C320单片机的资料里面只有外部接口的时序介绍,对于内部的信号执行则没有说明,因此需要重新规划,本软核对DS80C320的时序进行了详细的分析,按照黑盒子的思想,加入了流水线的技巧,对其时序的设计如下:
对于普通指令的执行过程,内部时序划分如下:
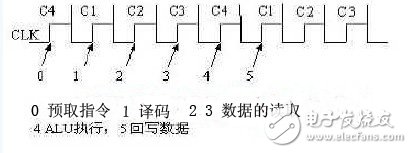
图2 DS80C320内部时序图
这是一条单字节单周期指令的执行过程,在C1的上升沿开始译码以及查找本指令的长度周期表,同时,数据总线上面是正在回写的上一条指令的结果;到了C2的上升沿,数据总线和地址总线的控制权就回到了本条指令的手里,这个时候地址总线用来发送需要读取的数据的地址,数据总线则做好从发送数据到接收数据的准备,这个动作由CPU控制模块完成;然后在C3的上升沿,被选中模块根据地址总线和控制总线读出相关数据并送入数据总线,在这以后的一个时钟长度的时间里面,ALU接到了数据,然后在C4的上升沿,开始执行数据处理,同时,CPU控制模块再次改变地址总线和控制总线的内容,并发布写信号,提示开始被选中读数的模块放弃对数据总线的控制权,以及被选中的存储结果的模块分析写入类型,作好接收数据的准备,ALU在计算完成之后就将结果放到数据总线,等待下一个周期的C1开始将结果写入相关位置;总之,本设计充分利用了数据总线的资源和流水设计的技巧,将本来需要6个时序的操作简化为4个就完成了,时序紧凑,速度快;同时采用了分布式处理的思想,大大简化了CPU控制模块的功能,只发布控制信号,具体哪个模块需要执行什么功能由该模块自行根据控制信号来判断,有利于避免由于局部功能太过集中而造成的芯片局部过热的问题;
3.2指令长度周期表的设计
指令长度表主要是用来控制取指令,以及辨别指令代码和指令参数;而指令周期表则主要是用来控制指令执行的时间,这两个表可以简化对指令执行的控制。一般这个过程由ROM模块根据已经读取的指令来查表,然后根据查表的结果和时序情况来处理分析,产生一系列控制信号,并发送给CPU控制模块,这样做的好处主要是避免CPU控制模块与指令以及数据打交道,减少其输入输出端口数目;指令长度周期表的设计是和读取方式息息相关的,本设计使用自己单独构建的表,并且一分为二,处理方式是为:index={lsb_3, ir[7:4]},其中lsb_3的含义为:对于指令的低三位(ir(2 downto 0)) 规则为:8-F=》7,6-7=》6,0-5不变化。两个表使用相同的读取方式,这样既可以简化结构,将查找空间降低为7位,又可以提高查找速度;
3.3 PC异动编码的作用
在单片机内部,PC是需要不停变化的,不仅所有的跳转类指令都需要改变PC的内容,而且中断类指令还需要完成PC的出栈以及入栈操作;因此,有些模型里面对PC的处理异常复杂,基本上是对每条指令详细规定PC的变化;本设计在这方面的处理采用了编码的技巧来提高速度;首先分析编码的可能性,虽然很多指令可以改变PC的内容,但是对于PC来说,除了正常的加1操作,其它的变化方式只有如下几种:
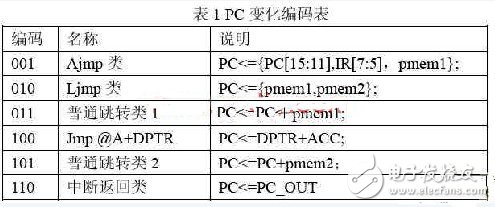
其中pmem1和pmem2为指令参数,来自于ROM模块;PC_OUT为堆栈中的PC内容。
剩下的难题就是由谁来发出这个编码,对于所有的跳转类指令以及中断类指令,每条指令的跳转条件是不相同的,需要一一判断,本设计就巧妙的利用了ALU模块来处理这个编码,ALU模块计算的时候也是需要对操作进行判断的,因此,只要添加一小段代码就可以让其完成发送编码的功能;PC编码的方式大大简化了PC模块的操作,使得程序更加规整;
3.4 双向P端口的模拟
这里主要是P0和P2双向端口的模拟;对于典型的单片机,其P端口一般都是双向的,但是对于FPGA设计来说,以现在的芯片结构,在FPGA芯片里面实现真正的双向是不可能的,因此,作为软核来说,双向的模拟就一定要处理好;常用的解决办法有这么几种:一种是直接将双向端口改成两个单向的端口,这样对于软核来说使用更加方便,本设计也提供了这种方式供选择,但是这样就与标准的单片机不相同了,因此,本设计也提供了一种模拟的双向口,根据FPGA设计的特点,改变信号线的方向必须有个切换的过程,这样就只好仔细的来分析指令时序,看看能不能在P端口使用的间隙来处理这个切换过程;首先是分析指令是否需要使用P端口,比较重要的控制信号有译码器发送的RD_LATCH信号,用来区分指令是否需要使用P端口,还有来自于CPU_CON的控制总线信息,用来告知P端口需要完成的具体功能;如果需要使用P端口的复用功能,则由相关的需要使用P端口的模块(如串行口模块)发送请求指令;然后P端口分析所有的使用请求,根据不同的使用方式来安排不同的使用情况;如果需要双向切换,则根据时序以及指令特点来处理,从而顺利完成双向的切换过程。
4 综合与验证
使用Altera公司的Quartus II 4.2软件来综合,使用Nios Development Board,Cyclone Edit开发板来进行板上验证;综合结果如下:
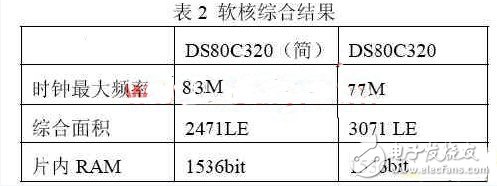
其中,前一个版本是没有内部串行口的版本;时序仿真验证的结果表明,在上述频率下该系统可以稳定的工作;理论上换算成8051的主频为:83*2.5=207.5M,这基本上可以适应绝大部分需要单片机控制的场合了;仿真测试主要使用了modelsim SE5.8以及quartus4.2的VWF文件测试;板上波形观测主要使用Agilent公司的 1673G 逻辑分析仪;同时充分利用了开发板的资源进行了大量的系统级测试;将程序下载到芯片里面,使用逻辑分析观测到部分指令的执行波形为:
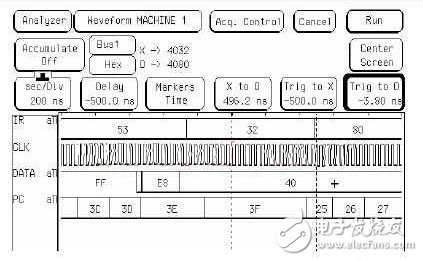
图3 中断指令波形图
这是一条中断返回指令的波形图,指令代码为32H,主要观测PC的变化,PC在这条指令之后从3FH又变化为中断发生前的地址25H。
5 结束语
本设计具有速度快,可裁减,具有良好的可重用性和可移植性,完全兼容DS80C320单片机接口,以及方便使用等优点。尤其是专门构造的内部框架以及时序分配,使得其高速性能在目前的51系列软核里面基本上是最前列的。因此,可以很方便的应用于需要单片机软核的FPGA设计以及嵌入式系统设计之中。
相关文章









