






 技术咨询
技术咨询 代买器件
代买器件 商务客服
商务客服 研发客服
研发客服近日,16周年庆活动现场,爱数正式开源了认知智能开发框架KWeaver。KWeaver脱胎于爱数认知智能框架AnyDATA Framework 2,具有快速的开发能力、全面的开放性、高性能等特性,以成熟的数据知识化方法论和系列认知智能应用组件赋能数据科学家和应用开发者,以此降低领域认知智能应用开发的复杂度与人才门槛。开源后,KWeaver将作为普惠技术进一步赋能产业,人人都可以在 GitHub 上获取。
GitHub 项目地址:https://github.com/AISHU-Technology/kweaver

长按识别二维码跳转
爱数在数据产业的布局与创新
2021年,爱数推出新愿景——以数据重塑生产力,共创智能世界。“数据”和“智能”作为爱数成长的两个关键词,很好地呼应了爱数的业务定位 Data+AI,即AI驱动,数据赋能。这个愿景背后,也蕴涵着爱数更高层次的追求:不仅要成长为一个典范企业,还应肩负起社会责任,让技术驱动社会进步,用数据赋能人类生产力的提升。

在“Data”层面,爱数很早就开始了数据产业的布局,实现数据产业从0到1的创新。2019年爱数发布大数据基础设施战略,加速布局数据产业;2021年~2022年爱数基于领域认知智能技术成立北方大数据交易中心,搭建全国数据交易网络体系;2022年爱数宣布以开源赋能产业,减低总体社会成本,实现客户、伙伴等多方的可信协作。
在“AI”层面,爱数认知智能技术在近两年也取得了较快的进展。2021年,爱数发布以领域知识网络为核心技术的AnyDATA ONE,并与复旦大学成立联合实验室开展认知智能的研究。之后,又和天津大学成立联合实验室开展数据智能技术的研究。目前,爱数正在全球范围招募人工智能博士,在长沙筹建人工智能研究院,以此推动领域认知智能技术的发展。
在此背景下,爱数一方面希望通过KWeaver的开源,整合全球智慧,将各行各业、各个领域不同的解题思路和方法模型融入爱数的认知智能框架,激发更多的创新与应用;另一方面也希望通过开源,让爱数积累的技术成果走出爱数,面向更多的数据科学家、应用开发者和领域专家,为行业拥抱AI提供更多的可能。
领域认知驱动需要开源
经过几十年的发展,人工智能从计算智能发展到感知智能,又从感知智能发展到认知智能。作为第三代人工智能,认知智能非常重要的特点之一,就是需要通过领域认知进行驱动。
“第三代人工智能的目标是要真正模拟人类的智能行为,我们必须充分地利用知识、数据、算法和算力,把四个因素充分利用起来,这样才能够解决不完全信息、不确定性环境和动态变化环境下面的问题,才能达到真正的人工智能。—— 张钹院士”
在此背景下,领域认知智能成为新的解题思路,这也是爱数自2021年推出认知智能战略后,联合复旦大学、天津大学等高等院校专家不断实践摸索出的技术成果。领域认知智能,面向某一领域内具体的业务问题,通过获取领域内的数据实现数据知识化形成领域知识网络,再基于领域智商评估领域知识的质量,在此基础上利用知识进行理解、推理和决策,从而开发出满足用户场景需求的领域认知智能应用,辅助人们解决特定的问题,提升生产力。
“认知智能的核心能力是“理解”和“解释”,体现在机器能够理解数据、理解语言进而理解现实世界的能力,体现在机器能够解释数据、解释过程进而解释现象的能力,体现在推理、规划等等一系列人类所独有的认知能力上。
——《知识图谱与认知智能》,肖仰华,复旦大学教授,复旦爱数联合研究研究中心主任”

然而,各行各业领域的众多、专业领域之间的高壁垒,唯有通过开源,才能更加容易地让不同行业、不同领域的开发者开发领域认知智能,从而也让 KWeaver 不断提升领域认知能力。对于爱数而言,一方面需要借助开源整合全球智慧;另一方面也可以通过开源开放自身的技术成果与积累,实现AI普惠全球。
爱数KWeaver 项目:开源的认知智能开发框架
KWeaver 是开源的认知智能开发框架,为数据科学家、应用开发者和领域专家提供具有快速的开发能力、全面的开放性和高性能的知识网络生成及认知智能应用开发的工具与平台。KWeaver名称中,K代表的是Knowledge知识,Weaver代表编织者,意为将所有领域知识编织在一起,从而实现领域认知智能。
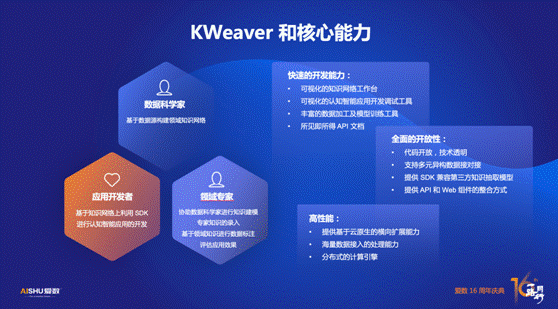
KWeaver面向数据科学家、应用开发者、领域专家三类用户提供三种能力。
快速的开发能力:KWeaver提供可视化的知识网络工作台,可视化的认知智能应用开发调试工具,丰富的数据加工及模型训练工具,以及所见即所得的API文档;
全面的开放性: KWeaver源代码是开源且技术透明的,这意味着参与项目的用户可以查看全部技术细节,同时还支持多元异构数据源对接,提供SDK兼容更多的第三方知识抽取模型,提供 API 和 Web 组件的整合方式;
高性能:得益于爱数多年在云原生领域的积累,KWeaver的开发基于云原生技术,提供横向扩展能力,采用分布式的计算引擎实现海量数据接入的处理能力。
通过KWeaver实现领域认知驱动涉及到两个关键步骤。
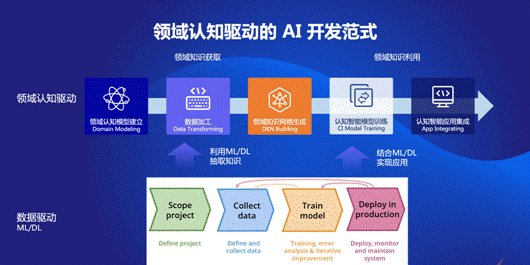
第一是领域知识获取。首先建立领域认知模型,基于模型进行数据加工抽取知识,对于不同来源的数据,加工的方式也会有很大不同,部分数据可以直接抽取,部分数据则需要通过深度学习模型,例如文本知识。加工完成后生成领域知识网络。
第二是领域知识利用。基于知识网络进行认知智能应用的开发,利用数据科学的方法开发模型,并将模型应用到推理、理解等具体场景。显然,在数据领域认知智能并非替代原有的深度学习或机器学习,而是将两者结合发挥更大的作用。KWeaver也会内置很多基于深度学习的知识抽取模型。
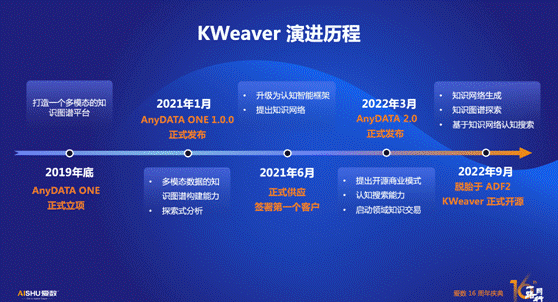
本次正式开源前,KWeaver已经伴随爱数AnyDATA经历了近3年的孵化和打磨,结合AnyShare、AnyRobot、AnyFabric等产品的能力实现诸多创新。如结合AnyShare在知识管理方面形成行业知识卡片、行业标签、知识搜索等应用;结合AnyRobot在智能运维方面实现可持续进化的运维知识库,以及运维中小概率事件的故障定位和根因分析;结合AnyFabric帮助用户更好地编织数据,以资产图谱的形式让用户更直观全面的观察和分析业务能力、数据质量等等。
16年专注,16年探索。从备份一体机到大数据基础设施,从人工智能到领域认知智能,从传统商业模式到KWeaver的正式开源,爱数始终在朝着“以数据重塑生产力,共创智能世界”的愿景不断成长。未来,爱数将以更开放、包容的心态,通过更多的开源计划实现技术共享,为数据产业的繁荣发展贡献自己应尽的力量。
相关文章









