STM32串口收发数据为什么要使用DMA?有哪些常见问题?
直接存储器访问(Direct Memory Access),简称DMA。DMA是CPU一个用于数据从一个地址空间到另一地址空间“搬运”(拷贝)的组件,数据拷贝过程不需CPU干预,数据拷贝结束则通知CPU处理。因此,大量数据拷贝时,使用DMA可以释放CPU资源。
在STM32控制器中,芯片采用Cortex-M3架构,总线结构有了很大的优化,DMA占用另外的总线,并不会与CPU的系统总线发生冲突。也就是说,DMA的使用不会影响CPU的运行速度。

DMA数据拷贝过程,典型的有:(1)内存—>内存,内存间拷贝;(2)外设—>内存,如uart、spi、i2c等总线接收数据过程;(3)内存—>外设,如uart、spi、i2c等总线发送数据过程。
串口有必要使用DMA吗?
串口(UART)是一种低速的串行异步通信,适用于低速通信场景,通常使用的波特率小于或等于115200bps。对于小于或者等于115200bps波特率的,而且数据量不大的通信场景,一般没必要使用DMA,或者说使用DMA并未能充分发挥出DMA的作用。对于数量大,或者波特率提高时,必须使用DMA以释放CPU资源,因为高波特率可能带来CPU资源过度浪费的问题。
举个例子:对于发送,使用循环发送,可能阻塞线程,需要消耗大量CPU资源“搬运”数据,浪费CPU。对于发送,使用中断发送,不会阻塞线程,但需浪费大量中断资源,CPU频繁响应中断。以115200bps波特率,1s大约传输11520字节,大约69us需响应一次中断,如波特率再提高,将消耗更多CPU资源。对于接收,如仍采用传统的中断模式接收,同样会因为频繁中断导致消耗大量CPU资源。因此,在高波特率传输场景下,串口非常有必要使用DMA。
DMA应用中的几个常见问题
1、概念上的误解
DMA传输是在DMA请求下,将数据从源端传输到目的端。常有人将DMA请求跟DMA的源端或目的端混为一谈。这里,我们可以将DMA传输类比成收发快递,发件方即DMA源端,收件方即DMA目的端,而DMA请求端就是呼叫快递的人。这个呼叫快递的人可能是发件方、也可能是收件方,还可能是另外第三方。比方你要发个快递,叫快递的人可能是公司的前台美眉。
具体到我们STM32应用,比方通过DMA将内存数据传输给UART DR寄存器发送出去,源端是存储相关待发送数据的内存区域,目的端是UART DR数据寄存器。至于DMA请求,可以是UART发送空事件【TXE】,也可以是定时器的某个周期性触发事件等。
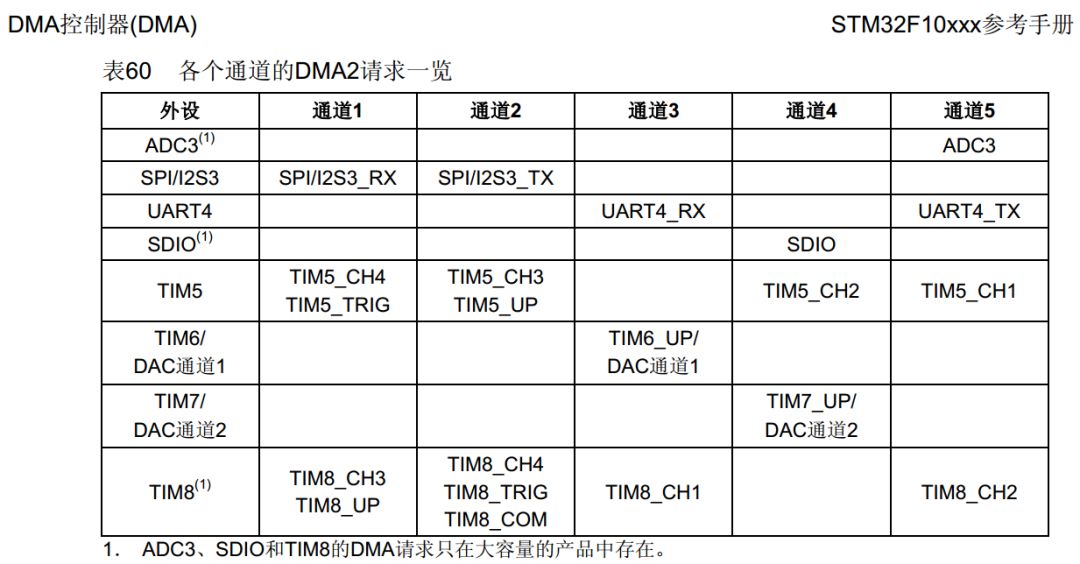
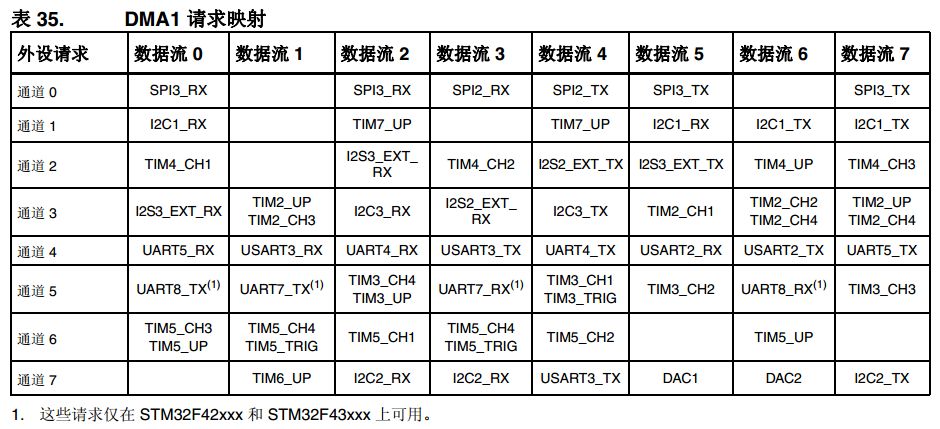
在STM32各个系列的参考手册的DMA章节部分,都有类似如下的DMA请求映射表。表格里填写的都只是针对各个DMA传输流的DMA请求事件,并非一定是源端或目的端。当然,不排除作为源端或目的端同时又担当DMA请求角色的可能。

2、配置上容易忽视的问题
我们在做DMA配置时,比较容易忽视两个小问题。第一个就是源端和目的端的数据宽度的定义问题,除了考虑配置满足实际需要的数据宽度外,还要注意将源端、目的端二者数据访问宽度配置一致。不然的话,往往会导致些奇怪的问题。

还有,就是 要注意DMA的传输方向别弄错了,到底是PERIPHERIAL到MEMORY还是MEMORY到PERIPHERIAL或者说是Memory到Memory要配置正确。 尤其是在用CubeMx配置时,这里有个默认配置是PERIPHERIAL到MEMORY。如果说你的真实意图根本不是从PERIPHERIAL到MEMORY,而你无意中使用了这个默认配置,结果可想而知,DMA传输根本没法正常运行。类似配置方面的小细节要多加注意,忽略了往往会累死人。
3、DMA传输作用范围问题
前面将DMA传输类比成发快递,发快递时,快递公司一般也没法无处不到,那DMA传输也有同样的问题,各个DMA模块往往有各自的服务范围。比方以下图STM32F4的一个框图为例。DMA1可以轻松访问右边黄色标注出来的外设,DMA2可以访问左边分数标注出来的各个外设。如果我们在程序里的DMA配置部分,将DMA1的源端或目的端安排为左边的粉色标注出来的外设、或者将DMA2的源端/目的端安排为右边的黄色标注出来的外设,结果一定会让你失望。因为你期望它访问它到达不了的地方。
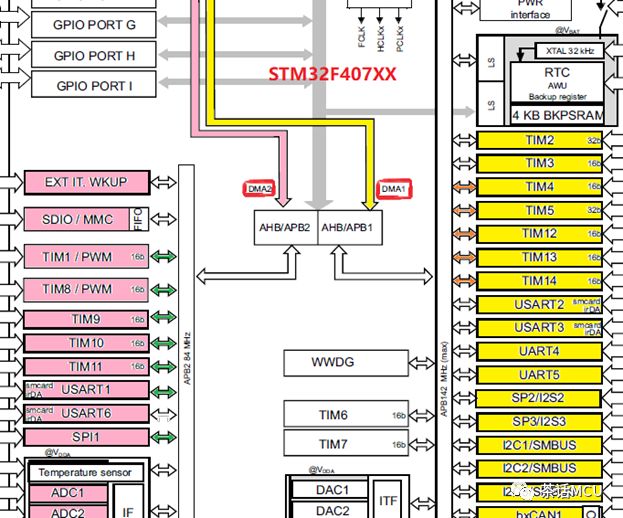
这个地方比较隐蔽,因为我们在代码里只是根据DMA请求自行指定源端和目的端,有时会忽视所用DMA的服务范围。前面提过,各个STM32系列参考手册里DMA章节部分都有明确的基于各路DMA传输流的DMA请求事件源的描述和展示,但并未指定基于各个DMA请求的源端或目的端。所以我们在基于某个DMA请求来自指定源端或目的端时,一定注意你安排的源/目的端是不是该DMA可以到达的地方,具体要结合手册中功能框图和总线访问架构图。比方说,下图是STM32F7系列一个总线访问框架图。不难看出,DMA1是访问不了AHB1外设和AHB2外设的。当然,DMA2访问AHB1外设和AHB2外设没有问题。

比方,下图是STM23H7系列一个总线访问框架图,其中BDMA是没法访问D1域或D2域的外设及内存的。D2域的DMA1/DMA2没法访问D1域中的DTCM/ITCM。D1域中的MDMA没法访问D2域中的AHB2外设。

关于这些总线框架性的东西,在我们的STM32应用中也要多加关注。比方有时在做通信数据传输时发现,使用中断没问题,用DMA就失败。这时不妨查看下DMA访问的外设或内存区域到底是不是它所能访问得到地方,如果不是就需要适当调整下。
4、跟DCache有关的问题
该问题往往跟我们使用带cache的M7内核的STM32F7或STMH7系列芯片有关,使用DMA传输时有时会遇到DMA访问到的数据不是实时的正确数据。这往往可能是因为DMA要访问的内存区域,跟CPU是共享的,同时又开启了相关区域的D-Cache属性,即CPU访问该内存区域数据时使用D-Cache,将内存数据拷贝到D-Cache。之后,CPU访问相关数据时往往只在Cache里进行。
比如下面的一个基于STM32F7芯片的经典示例。首先CPU从flash里拷贝128字节常量数据到片内SRAM,然后通过DMA将SRAM里的这128字节数据拷贝进DTCM内存区。最后通过CPU将DTCM里的数据跟FLASH里的原始数据进行比较,这时会发现比较结果是二者内容根本不一致。这是因为开启了SRAM的回写的Cache属性,第一次将数据从flash拷贝进SRAM过程中,数据还没有真正写进SRAM,还只是放在了Cache。当我们通过DMA将SRAM相关区域的数据拷贝进DTCM内存区时,并没有将真正的来自FLASH区的数据拷贝过去,导致最后的数据比较失败。

像这种情况下,我们可以有几种方案来解决这个问题:
1、在做将数据从SRAM拷贝到DTCM区之前,先做个D-Cache的清除操作【SCB_CleanDCache()】,将D-Cache里的数据写回到实际存储区SRAM里。
2、我们可以通过MPU设置SRAM区域的MPU属性,将其回写的Cache属性【writeback】调整为透写的Cache属性【writethrough】。
3、配置SRAM的MPU属性为shareable共享属性,令CPU访问它时不使用D-Cache。
4、将所有涉及到具有Cacheable可缓存属性的存储区域,都使用透写策略。这点可以通过配置M7内核相关控制寄存器位实现。
再举个实例,使用STM32F7芯片做UART的通信数据接收,UART接收到数据后触发DMA,DMA将数据从UART_DR寄存器拷贝到片内SRAM,CPU再从相应的SRAM区取走数据送到某LCD显示设备显示输出。这时,你很可能会发现一个奇怪的现象,显示设备输出的数据永远都是第一次接收到的数据,不管UART的发送方任何改变发送数据,显示出来的数据就是不变,只是跟第一次发送出来的数据相比是正确的。这是怎么回事呢?

原因是因为开启了SRAM的D-Cache属性,CPU第一次从SRAM读取数据后,同时又将数据放到D-Cache里,后面再来读取SRAM相应地址数据时并没有前往SRAM,而是直接去D-Cache里提取数据,从而导致每次显示出来的数据总是第一次接收到的数据,尽管UART那边后续接收的数据在不停变化,但并没有对D-Cache里的数据做同步更新。这时我们可以在CPU读取SRAM数据前做个D-cache的清除操作,让实际存储器数据与D-Cache里数据同步更新,或者做D-Cache的失效操作,让CPU无视D-cache直接从SRAM区读取数据,或者说通过MPU配置禁用该SRAM区的Cache属性。当然,最终你选用哪种策略,得结合你的实际应用来定。
串口DMA接收不定长数据
1、在STM32的DMA资源
STM32F1系列的MCU有两个DMA控制器(DMA2只存在于大容量产品中),DMA1有7个通道,DMA2有5个通道,每个通道专门用来管理来自于一个或者多个外设对存储器的访问请求。还有一个仲裁器来协调各个DMA请求的优先权。

而STM32F4/F7/H7系列的MCU有两个DMA控制器总共有16个数据流(每个DMA控制器8个),每一个DMA控制器都用于管理一个或多个外设的存储器访问请求。每个数据流总共可以有多达8个通道(或称请求)。每个通道都有一个仲裁器,用于处理 DMA 请求间的优先级。

2、DMA接收数据
DMA在接收数据的时候,串口接收DMA在初始化的时候就处于开启状态,一直等待数据的到来,在软件上无需做任何事情,只要在初始化配置的时候设置好配置就可以了。等到接收到数据的时候,告诉CPU去处理即可。
那么问题来了,怎么知道数据是否接收完成呢?其实,有很多方法:(1) 对于定长的数据 ,只需要判断一下数据的接收个数,就知道是否接收完成,这个很简单。(2) 对于不定长的数据 ,也有好几种方法,麻烦的不会介绍,有兴趣做复杂工作的同学可以在网上看看别人怎么做,下面这种方法是最简单的,充分利用了STM32的串口资源,效率也是非常之高:DMA+串口空闲中断。这两个资源配合,简直就是天衣无缝啊,无论接收什么不定长的数据,管你数据有多少,来一个我就收一个,就像广东人吃“山竹”,来一个吃一个。
STM32串口的状态寄存器:

idle

idle说明
当我们检测到触发了串口总线空闲中断的时候,就知道这一波数据传输完成了,然后我们就能得到这些数据,去进行处理即可。 这种方法是最简单的,根本不需要我们做多的处理,只需要配置好,串口就等着数据的到来,DMA也是处于工作状态的,来一个数据就自动搬运一个数据。
串口接收完数据是要处理的,那么处理的步骤是怎么样呢?
暂时关闭串口接收DMA通道,有两个原因:1.防止后面又有数据接收到,产生干扰,因为此时的数据还未处理。2.DMA需要重新配置。
清DMA标志位。
从DMA寄存器中获取接收到的数据字节数(可有可无)。
重新设置DMA下次要接收的数据字节数。**注意,数据传输数量范围为0至65535。**这个寄存器只能在通道不工作(DMA_CCRx的EN=0)时写入。通道开启后该寄存器变为只读,指示剩余的待传输字节数目。寄存器内容在每次DMA传输后递减。数据传输结束后,寄存器的内容或者变为0;或者当该通道配置为自动重加载模式时,寄存器的内容将被自动重新加载为之前配置时的数值。当寄存器的内容为0时,无论通道是否开启,都不会发生任何数据传输。
给出信号量,发送接收到新数据标志,供前台程序查询。
开启DMA通道,等待下一次的数据接收,注意,对DMA的相关寄存器配置写入,如重置DMA接收数据长度,必须要在关闭DMA的条件进行,否则操作无效。
3、注意事项
STM32的IDLE的中断在串口无数据接收的情况下,是不会一直产生的,产生的条件是这样的,当清除IDLE标志位后,必须有接收到第一个数据后,才开始触发,一断接收的数据断流,没有接收到数据,即产生IDLE中断。如果中断发送数据帧的速率很快,MCU来不及处理此次接收到的数据,中断又发来数据的话,这里不能开启,否则数据会被覆盖。有两种方式解决:(1)在重新开启接收DMA通道之前,将Rx_Buf缓冲区里面的数据复制到另外一个数组中,然后再开启DMA,然后马上处理复制出来的数据。(2) 建立双缓冲 ,重新配置DMA_MemoryBaseAddr的缓冲区地址,那么下次接收到的数据就会保存到新的缓冲区中,不至于被覆盖。
4、程序实现
实验效果:当外部给单片机发送数 据的时候,假设这帧数据长度是1000个字节,那么在单片机接收到一个字节的时候并不会产生串口中断,只是DMA在背后默默地把数据搬运到你指定的缓冲区里面。当整帧数据发送完毕之后串口才会产生一次中断,此时可以利用DMA_GetCurrDataCounter()函数计算出本次的数据接受长度,从而进行数据处理。
4.1串口的配置
很简单,基本与使用串口的时候一致,只不过一般我们是打开接收缓冲区非空中断,而现在是打开空闲中断——USART_ITConfig(DEBUG_USARTx, USART_IT_IDLE, ENABLE);。
/** *@briefUSARTGPIO配置,工作参数配置 *@param无 *@retval无 */ voidUSART_Config(void) { GPIO_InitTypeDefGPIO_InitStructure; USART_InitTypeDefUSART_InitStructure; //打开串口GPIO的时钟 DEBUG_USART_GPIO_APBxClkCmd(DEBUG_USART_GPIO_CLK,ENABLE); //打开串口外设的时钟 DEBUG_USART_APBxClkCmd(DEBUG_USART_CLK,ENABLE); //将USARTTx的GPIO配置为推挽复用模式 GPIO_InitStructure.GPIO_Pin=DEBUG_USART_TX_GPIO_PIN; GPIO_InitStructure.GPIO_Mode=GPIO_Mode_AF_PP; GPIO_InitStructure.GPIO_Speed=GPIO_Speed_50MHz; GPIO_Init(DEBUG_USART_TX_GPIO_PORT,&GPIO_InitStructure); //将USARTRx的GPIO配置为浮空输入模式 GPIO_InitStructure.GPIO_Pin=DEBUG_USART_RX_GPIO_PIN; GPIO_InitStructure.GPIO_Mode=GPIO_Mode_IN_FLOATING; GPIO_Init(DEBUG_USART_RX_GPIO_PORT,&GPIO_InitStructure); //配置串口的工作参数 //配置波特率 USART_InitStructure.USART_BaudRate=DEBUG_USART_BAUDRATE; //配置针数据字长 USART_InitStructure.USART_WordLength=USART_WordLength_8b; //配置停止位 USART_InitStructure.USART_StopBits=USART_StopBits_1; //配置校验位 USART_InitStructure.USART_Parity=USART_Parity_No; //配置硬件流控制 USART_InitStructure.USART_HardwareFlowControl= USART_HardwareFlowControl_None; //配置工作模式,收发一起 USART_InitStructure.USART_Mode=USART_Mode_Rx|USART_Mode_Tx; //完成串口的初始化配置 USART_Init(DEBUG_USARTx,&USART_InitStructure); //串口中断优先级配置 NVIC_Configuration(); #ifUSE_USART_DMA_RX //开启串口空闲IDEL中断 USART_ITConfig(DEBUG_USARTx,USART_IT_IDLE,ENABLE); //开启串口DMA接收 USART_DMACmd(DEBUG_USARTx,USART_DMAReq_Rx,ENABLE); /*使能串口DMA*/ USARTx_DMA_Rx_Config(); #else //使能串口接收中断 USART_ITConfig(DEBUG_USARTx,USART_IT_RXNE,ENABLE); #endif #ifUSE_USART_DMA_TX //开启串口DMA发送 //USART_DMACmd(DEBUG_USARTx,USART_DMAReq_Tx,ENABLE); USARTx_DMA_Tx_Config(); #endif //使能串口 USART_Cmd(DEBUG_USARTx,ENABLE); }
4.2串口DMA配置
把DMA配置完成,就可以直接打开DMA了,让它处于工作状态,当有数据的时候就能直接搬运了。
#ifUSE_USART_DMA_RX staticvoidUSARTx_DMA_Rx_Config(void) { DMA_InitTypeDefDMA_InitStructure; //开启DMA时钟 RCC_AHBPeriphClockCmd(RCC_AHBPeriph_DMA1,ENABLE); //设置DMA源地址:串口数据寄存器地址*/ DMA_InitStructure.DMA_PeripheralBaseAddr=(uint32_t)USART_DR_ADDRESS; //内存地址(要传输的变量的指针) DMA_InitStructure.DMA_MemoryBaseAddr=(uint32_t)Usart_Rx_Buf; //方向:从内存到外设 DMA_InitStructure.DMA_DIR=DMA_DIR_PeripheralSRC; //传输大小 DMA_InitStructure.DMA_BufferSize=USART_RX_BUFF_SIZE; //外设地址不增 DMA_InitStructure.DMA_PeripheralInc=DMA_PeripheralInc_Disable; //内存地址自增 DMA_InitStructure.DMA_MemoryInc=DMA_MemoryInc_Enable; //外设数据单位 DMA_InitStructure.DMA_PeripheralDataSize= DMA_PeripheralDataSize_Byte; //内存数据单位 DMA_InitStructure.DMA_MemoryDataSize=DMA_MemoryDataSize_Byte; //DMA模式,一次或者循环模式 //DMA_InitStructure.DMA_Mode=DMA_Mode_Normal; DMA_InitStructure.DMA_Mode=DMA_Mode_Circular; //优先级:中 DMA_InitStructure.DMA_Priority=DMA_Priority_VeryHigh; //禁止内存到内存的传输 DMA_InitStructure.DMA_M2M=DMA_M2M_Disable; //配置DMA通道 DMA_Init(USART_RX_DMA_CHANNEL,&DMA_InitStructure); //清除DMA所有标志 DMA_ClearFlag(DMA1_FLAG_TC5); DMA_ITConfig(USART_RX_DMA_CHANNEL,DMA_IT_TE,ENABLE); //使能DMA DMA_Cmd(USART_RX_DMA_CHANNEL,ENABLE); } #endif
4.3接收完数据处理
因为接收完数据之后,会产生一个idle中断,也就是空闲中断,那么我们就可以在中断服务函数中知道已经接收完了,就可以处理数据了,但是中断服务函数的上下文环境是中断,所以,尽量是快进快出,一般在中断中将一些标志置位,供前台查询。在中断中先判断我们的产生在中断的类型是不是idle中断,如果是则进行下一步,否则就无需理会。
/** ****************************************************************** *@brief串口中断服务函数 *@authorjiejie *@versionV1.0 *@date2018-xx-xx ****************************************************************** */ voidDEBUG_USART_IRQHandler(void) { #ifUSE_USART_DMA_RX /*使用串口DMA*/ if(USART_GetITStatus(DEBUG_USARTx,USART_IT_IDLE)!=RESET) { /*接收数据*/ Receive_DataPack(); //清除空闲中断标志位 USART_ReceiveData(DEBUG_USARTx); } #else /*接收中断*/ if(USART_GetITStatus(DEBUG_USARTx,USART_IT_RXNE)!=RESET) { Receive_DataPack(); } #endif }
4.4Receive_DataPack()
这个才是真正的接收数据处理函数,为什么我要将这个函数单独封装起来呢?因为这个函数其实是很重要的,因为我的代码兼容普通串口接收与空闲中断,不一样的接收类型其处理也不一样,所以直接封装起来更好,在源码中通过宏定义实现选择接收的方式!更考虑了兼容操作系统的,可能我会在系统中使用dma+空闲中断,所以,供前台查询的信号量就有可能不一样,可能需要修改,我就把它封装起来了。
/************************************************************ *@briefUart_DMA_Rx_Data *@paramNULL *@returnNULL *@authorjiejie *@githubhttps://github.com/jiejieTop *@date2018-xx-xx *@versionv1.0 *@note使用串口DMA接收时调用的函数 ***********************************************************/ #ifUSE_USART_DMA_RX voidReceive_DataPack(void) { /*接收的数据长度*/ uint32_tbuff_length; /*关闭DMA,防止干扰*/ DMA_Cmd(USART_RX_DMA_CHANNEL,DISABLE);/*暂时关闭dma,数据尚未处理*/ /*清DMA标志位*/ DMA_ClearFlag(DMA1_FLAG_TC5); /*获取接收到的数据长度单位为字节*/ buff_length=USART_RX_BUFF_SIZE-DMA_GetCurrDataCounter(USART_RX_DMA_CHANNEL); /*获取数据长度*/ Usart_Rx_Sta=buff_length; PRINT_DEBUG("buff_length=%d ",buff_length); /*重新赋值计数值,必须大于等于最大可能接收到的数据帧数目*/ USART_RX_DMA_CHANNEL->CNDTR=USART_RX_BUFF_SIZE; /*此处应该在处理完数据再打开,如在DataPack_Process()打开*/ DMA_Cmd(USART_RX_DMA_CHANNEL,ENABLE); /*(OS)给出信号,发送接收到新数据标志,供前台程序查询*/ /*标记接收完成,在DataPack_Handle处理*/ Usart_Rx_Sta|=0xC000; /* DMA 开启,等待数据。注意,如果中断发送数据帧的速率很快,MCU来不及处理此次接收到的数据, 中断又发来数据的话,这里不能开启,否则数据会被覆盖。有2种方式解决: 1.在重新开启接收DMA通道之前,将Rx_Buf缓冲区里面的数据复制到另外一个数组中, 然后再开启DMA,然后马上处理复制出来的数据。 2.建立双缓冲,重新配置DMA_MemoryBaseAddr的缓冲区地址,那么下次接收到的数据就会 保存到新的缓冲区中,不至于被覆盖。 */ }
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。