简述STM32G4芯片内不同空间运行代码的速率比较
来源: 电子工程世界
新闻行业新闻
最近有人问起程序在STM32G4片内不同存储空间运行的速度差异。说实在的,这个很难说死或说出个绝对的数据,毕竟结果除了跟执行代码的存放空间有关外,还跟代码本身的内容、程序逻辑、编译工具及优化等级等都息息相关。我这里设计了一个小测试程序做了下简单比较,以供参考。
我们不妨先看看STM32G4系列内部系统框架图。下图是STM32G4芯片的系统框架图,我将测试程序放在图中三个黄色高亮位置来运行。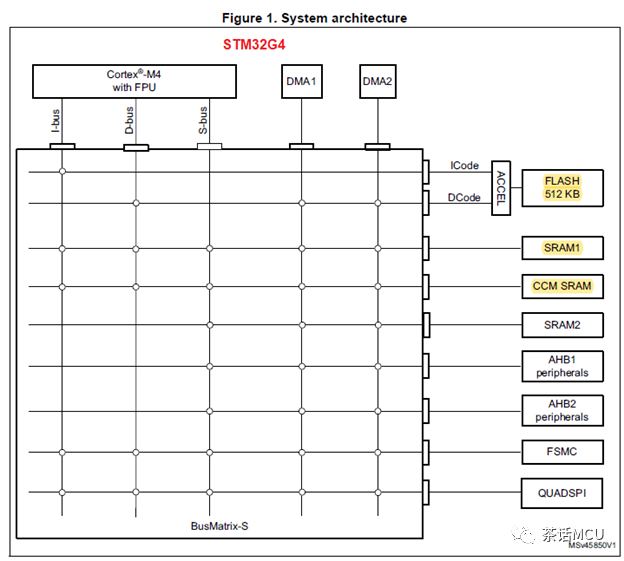
我将程序分别放在CCM、通用SRAM1、Flash区来运行,基于不同的配置,即是否开启指令预取、指令/数据Cache等,得到下面一个表格。代码所在区域栏里的数据代表各种情形下的执行时间。
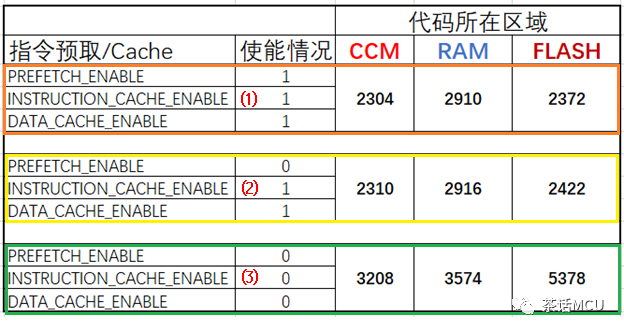
从上面表格可以看出,相同配置下在CCM里执行速率总是最高。
至于代码放在SRAM和Flash里的执行速率,不同配置下结果并不太一样。比如在开启prefetch和使能指令/数据Cache时,即第(1)种配置条件下,在SRAM里运行的速率是最慢的,只有在上图中的第(3)种情形下,代码在SRAM里运行速率相比在FLASH里运行才凸显出明显优势。
对于STM32G4系列芯片,芯片复位后其Prefetch功能是关闭的,而指令/数据Cache是开启的,即复位后默认为上面的第(2)种情形。结合上图,我们不难看出情形(1)与情形(2)的差别不大,至少不显著。
上面数据虽只是基于特定代码测试而得,但作为基本的方向性判断还是可以的。
文章来源于: 电子工程世界原文链接
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。