基于ARM的中英文翻译器设计
为了改进某焊接设备只能输出打印英文单据的情况,设计了由高性能ARM7控制器——LPC2214为核心的英文转中文翻译器,详细论述了具体的硬件电路和优化的软件算法的设计原理,实验结果表明,翻译器对输入的英文数据量的大小无任何限制,能够显著降低系统硬件资源需求且能大大提升打印速度。大体概念外观如下图所示。
基于某焊接设备存储大量数据需要通过打印机输出,但由于该设备及其配套的微型热敏打印机只能英文打印,不能中文打印的问题,从而影响用户阅读。另外,原有的配套英文打印机具有打印速度缓慢、每一组数据间隔过大,浪费纸张等缺点。因此,为了解决上述问题,根据实际工程项目应用需要,提出一种基于ARM的英文转中文的翻译器设计方案,该设计是在原有设备和支持中文打印的热敏打印机之间增加一块以ARM为核心的电路板作为英文转中文的翻译器,接收设备传输的英文数据,然后通过优化算法转换成中文,能够边接收边打印输出。该系统设计从实验结果来看,打印输出效果良好,整个打印过程快速迅捷,每一组数据间隔可调,能够节省大量纸张。
1 系统硬件电路设计
翻译器的系统结构框图如图l所示,它主要包括供电电源、核心控制器LPC2214和双串口接口以及启动和ISP控制接口等电路。该系统设计采用优化的系统软件算法,能够节省大量硬件资源需求。由于数据量非常大且要求快速打印,通常情况会增加一块容量很大的SRAM来接收英文数据,然后再进行比较翻译打印输出。而本系统由于采用了环形接收/发送缓冲区以及前后台程序方式,这样就无需增加SRAM,能够实现边接收边打印,而且系统硬件电路设计简单明了。

1.1 供电电源电路
图2给出了系统的供电电源电路,从图中可看出电源输入端只需一种12 V左右的电压输入,经过7805首先降至5 V,以满足通常5 V供电,而且还满足低压差的稳压器SPXlll7的输入要求。由于LPC2214需要2组电源电压输入:3.3V和1.8V,因此,5 V电压再经过SPXlll7-3.3和SPXlll7-1.8分别输出3.3 V和1.8 V给LPC2214供电。另外,图2中的VDl二极管是为防止反接电源烧毁电路而设计的。

1.2 LPC2214及其启动控制电路
LPC2214是PHILIPS公司生产的一款基于ARM7核的32位高性能处理器,应用广泛。其内部包括256 KB的Flash和16KB的SRAM,片内的128位宽的存储器接口和独特的加速结构使得该处理器可以在高达60 MHz的工作频率下运行。此外,通过外部存储器接口可将存储器配置成4组,每组容量高达16 MB,此外,片内还集成了多种外设,包括双串口、8路A/D采集通道、I2C接口和SPI接口、支持32个中断请求的中断控制,以及多达112个通用I/O口。由于集成度非常高,所以不必像5l单片机那样需扩展很多的外部器件,大大简化了系统硬件电路设计。图3给出英文转中文翻译器的核心控制器LPC2214的启动控制电路。在图3中,LPC2214的P2.26和P2.27引脚均需外接一只上拉电阻,在系统复位后将从片内Flash的地址0x00000000处开始运行程序。另外P0.14引脚接有一只上拉电阻,用于禁止ISP(在系统编程),如果想要使能ISP,将跳线JP3短接即可。

1.3 双串口接口电路
LPC2214包含2个串行接口,分别为UART0和UARTl,恰好符合该系统设计应用要求,这2个串行接口分别与设备和打印机相连。由于设备和打印机都要求标准的RS232串行传输,而LPC2214是3.3V电平,所以使用了2片SP3232E进行RS232电平转换,如图4所示。LPC2214通过端子J2的CTSl信号检测打印机存在并通过端子Jl的DTR信号通知设备;而通过端子J2的RXDl(BUSY)信号检测打印机内部缓冲区是否溢出;当LPC2-214内部接收缓冲区存满时,通过端子J1的CTS信号通知设备暂停传输数据。

2 系统软件算法
由于数据量非常大,所以在软件设计方面进行了优化,主要包括中英文数据存储方式、环形接收和发送缓冲区算法、查找和翻译算法等3部分。
2.1 中英文数据存储方式
首先,英文转中文翻译器涉及到的问题是汉字在计算机内的存储问题,汉字在计算机内的存储是以机内码形式存储的,1个汉字占用2个字节,因此在LPC2214中可以直接定义与接收到的英文字符串相对应的汉字常量字符串作为翻译后的数据。其次,为了查找方便,对接收到的英文字符串分了3类,相应地汉字字符串也对应分为3类,如图5所示。其中,库l为包含“:”的英文行,对应的中文翻译只是翻译“:”前的英文,而“:”后的英文字符和数字不必翻译直接输出;库2为不包含“:”的英文行,直接将对应的中文库2输出即可;库3为含有多义语义的英文行库,在中文库3中再细分后输出。在具体编程时利用了二维数组结构存储中英文字库。

2.2 环形接收和发送缓冲区算法
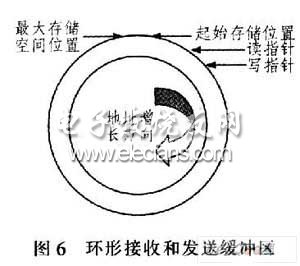
设备传输的数据量很大,共有几百组数据,而每组数据又包含几十行英文字符和数字,如果采用全部接收完设备传输的数据后再查找对应的中文,找到后再依次控制打印机打印输出,则不但需要相当大的缓冲区用于存储,而且从接收数据开始到打印机输出打印要延误很长时间。因此,这里采用前后台程序方式即边接收、边查找、边打印,该方式既节省时间又节省存储空间。在系统中开一段存储空间作为接收缓冲区,如图6所示。设置2个指针:写指针和读指针,初始化时令这2个指针分别指向存储区的起始位置。接收设备数据采用UART0串口接收中断处理方式,以便不丢失设备发送的任何一个字符。在UART0每接收一行英文数据后,写指针加1,当写指针达到最大存储空间位置时,令写指针复位为起始存储位置,这样就形成一个环形缓冲区。当接收缓冲区非空,即有需要翻译的英文行数据时,读指针指向当前需要翻译的英文行数据,和写指针类似,每翻译一行数据后通过UARTl控制打印机输出打印且读指针加1,当读指针到达最大存储空间位置时,令读指针复位为起始存储位置。实验表明,设置成很少的几行接收和发送缓冲区都可以正常接收数据和打印数据。
2.3 查找和翻译算法
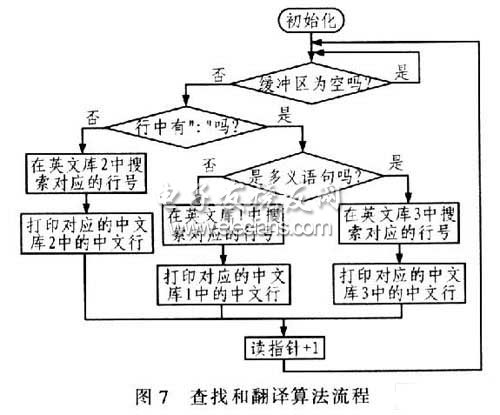
查找和翻译算法是在主程序中进行的,就是将接收和发送缓冲区中接收的每一行英文数据和三个英文库中的存储的英文行数据进行比较,如果一致,就返回所在当前英文库中的行号,然后根据行号再找到对应的中文库巾的数据行号即可,最后就可以控制打印机按一定格式输出打印。整个算法的流程如图7所示。
3 实验结果
图8给出了英文和中文打印效果的对比,由于数据量非常大,此处只是截取了很少的一段。可以看出中文打印输出翻译准确、格式整齐,字体大小合适。另外,由于选取了更快速的热敏打印机,从调试过程中可以明显看出中文打印的速度远远快于原来配套的英文打印速度。

4 结论
本系统实现的英文转中文翻译器在软硬件方面都采取较好的方案,硬件集成度高,电路板尺寸小,软件算法简洁,编程时除了启动代码采用汇编语言外其他大部分功能代码均采用了模块化的C语言编程,所以针对其他相关的应用领域,在硬件和软件上只需作相应改动即可方便实现。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。