Meta将在旗下社交平台标记AI生成图像,方便用户识别
2月7日消息,美国时间周二,Facebook母公司的全球事务总裁尼克·克莱格(Nick Clegg)宣布,未来几个月将推出一项新技术,利用文件内的隐形标记来检测和标记其他公司人工智能()服务生成的图像。
本文引用地址:克莱格在一篇博客文章中详细介绍了这项计划。他表示,将在其旗下的Facebook、Instagram和Threads等服务平台上,对所有带有标记的内容应用这些新标签。这将帮助用户识别那些看似真实照片,实则是由人工智能创作的图像。
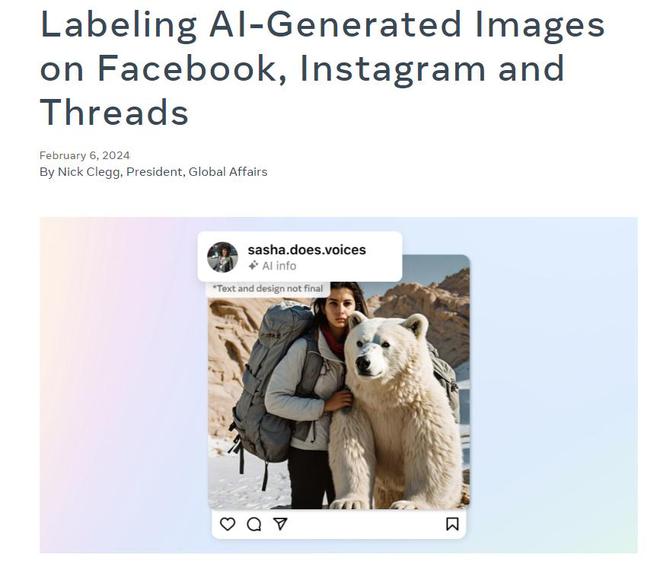
值得一提的是,已率先对其自家人工智能工具生成的所有内容进行了标签处理。克莱格透露,一旦新系统启动并运行顺利,Meta将对Open、微软、Adobe、Midjourney、Shutterstock和谷歌等公司所运行服务上创建的图像采取同样的处理方式。
这一举措标志着科技公司正在积极开发一个新兴的标准体系,旨在减轻与生成式人工智能技术相关的潜在风险。生成式人工智能技术可以根据简单提示生成看似真实但实际上虚假的内容。
克莱格在接受采访时表达了对目前技术能力的信心,他认为这些公司现在可以可靠地标记人工智能生成的图像。不过,他也坦言,标记音频和视频内容的工具更为复杂,目前仍在紧张开发中。
这一新计划显然借鉴了过去十年间一些公司建立的协调跨平台删除被禁内容的模板。
克莱格强调:“尽管这项技术,特别是在音频和视频领域,还有待完善,但我们希望能够借此创造一种动力和激励,促使其他行业效仿。”
在谈到内容管理时,克莱格透露,Meta将开始要求用户对自己修改过的音频和视频内容贴上标签。如果用户未能遵守这一规定,将会面临处罚。但克莱格没有详细说明处罚措施。
然而,克莱格也承认,目前在标记由ChatGPT等人工智能工具生成的书面文本方面,尚缺乏有效的机制。
当被问及Meta是否会对其加密消息服务WhatsApp上分享的生成式人工智能内容贴上标签时,Meta发言人并未给出明确答复。
周一,Meta的独立监督委员会对该公司处理误导性篡改视频的政策提出了批评,认为该政策过于狭隘,应该采取标记内容的方式而非直接删除。克莱格表示大体上同意这些批评,并承认现有政策在应对合成内容和混合内容日益增多的环境下显得捉襟见肘。
克莱格以Meta正在推动的新标签合作关系为例,证明公司已经在朝着监督委员会提议的方向努力迈进。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。