数据闭环研究:自动驾驶3.0阶段,做好端到端,赢取数据掌控权
目前,自动驾驶已进入3.0阶段。不同于2.0阶段基于人工规则的软件驱动,3.0阶段自动驾驶功能的迭代以大数据、大模型驱动为核心,感知方式是多模态传感器联合输出结果,而信息融合方式则从后融合逐步向中融合及前融合演进。
在数据能力建设上,企业的焦点已转移至数据闭环的效率与成本,并在数据合规和数据安全的前提下解决更多Corner Cases(极端情况如交通事故、恶劣天气条件或复杂路况),加速用户体验从“疲劳缓解”阶段向“场景化舒适体验”发展。其中主机厂着力提升的场景应用主要集中在城区、城市高架以及高速自动驾驶上。
在高速场景中,用户可以安心启用自动驾驶功能,自动驾驶系统可以精确舒适地引领上下匝道、车道居中保持、大曲率高速过弯、拥挤路段平衡跟车停车、智能选择最佳车道、车道内横向躲避并超越慢车、智能识别避让故障及缓慢车辆等。例如,小马智行NOA方案(见下图)能够灵活应对高速以及城市交通场景,在自主变道、上下匝道、定速巡航、车道居中、躲避障碍物等场景中表现优秀。
在城市场景中,蔚来NOP+、华为NCA、小鹏XNGP等城市NOA辅助驾驶功能纷纷落地,车辆功能的场景泛化能力持续提升。比如阿维塔搭载的华为智驾系统ADS2.0,能够在狭窄城市街道成功穿越两辆卡车的夹击(见下图),规划策略与人类驾驶决策水平持平,甚至超越。
总之,自动驾驶系统在自主变道、躲避障碍物等场景中的表现愈加优秀,人的接管率越来越低,而汽车智能化竞争的背后是数据在车端云端闭环中的高效流转。比如百度智能云自动驾驶数据闭环方案提供全周期的自动驾驶数据运营服务与自动驾驶工具链平台,能够解决数据获取、加工、使用过程中的难题。
百度自动驾驶数据闭环解决方案
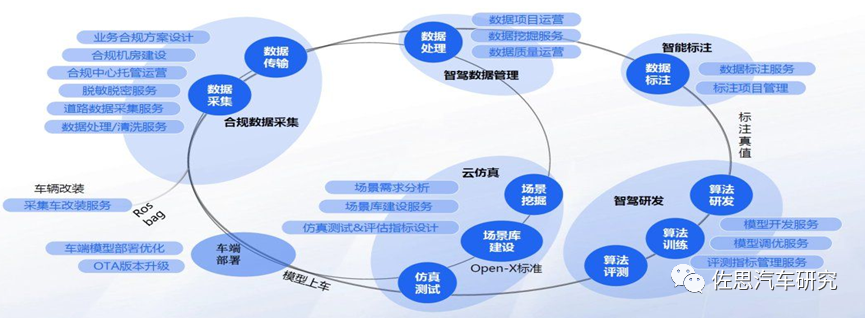
来源:百度智能云
01、自动驾驶3.0阶段开启,企业加码建设或完善数据闭环体系的各个环节
自动驾驶3.0阶段,本质就是以数据驱动为核心,持续提升数据挖掘效率和利用效率。这一阶段,车辆测试数据规模可达到1亿公里以上,这对数据闭环中的采集、标注等环节构成挑战。对此,车企通过提升影子模式的灵活采集逻辑、零原型仿真等手段来加速数据处理效率,为算法迭代、模型训练及部署等做好准备。
下面通过数据闭环的关键环节,即数据采集、数据标注、仿真测试等方面为例,来看汽车企业及数据闭环方案商的提效行动。
数据采集
目前,数据采集可以通过道路采集车、量产车、云端仿真、车主数据贡献等方式来实现。其中,影子模式在采集车内车外动/静态数据时,效率相对更高。车企设置的算法触发逻辑更加灵活、更加精准,比如小鹏在具备数采能力车辆上设置超300个触发信号,系统可判断当前怎样的Corner Case是对系统有用的,然后上传。上汽飞凡在车端设置了非常多的Triggered Event,触发这些条件后,采集多模态数据并回传数据,在效率上,三个月内就获得了近 1200 万个 clips 数据回传。还有智协慧同数采系统通过云端低代码工具vStudio使用各种算子轻松搭建触发算法。整套车云协同的方案,支持触发算法一键下发车端,无需繁杂的OTA流程,算法迭代效率高。智协慧同影子模式向2.0阶段演进,助力构建触发场景库、人机对比、AB模型对比,并在边缘计算的加持下,能够实现未知异常场景挖掘等,实现大幅降本增效。
数据标注
数据标注是自动驾驶数据闭环中最关键的环节之一。当前,如何不断提升对采集到的多模态高价值数据进行高效的自动化标注,是传统标注公司及数据闭环方案商关注的焦点。
为更好赋能车企,传统标注公司正陆续研发自己的自动化数据标注平台,提升数据标注的效率及标注的质量;同时,这些企业也开始与各类智算中心合作,在大模型加持下持续完善标注平台能力,并降低标注成本。
以海天瑞声为例,其自研的DOTS-AD自动驾驶标注平台能够支持多维度、全方位自动驾驶标注任务,数据标注效率提升高达8倍。再比如曼孚科技的MindFlow SEED数据服务平台通过AI+RPA驱动自动驾驶数据标注规模化量产,将综合人效平均提升30%,数据生产成本平均降低40%。
数据闭环方案商毫末智行在驾驶场景识别能力上,基于毫末 DriveGPT 所建立的 4D Clips 驾驶场景识别方案,可以使得单张图片的标注成本降到0.5元,是目前行业平均成本的1/10。毫末正在将图像帧及 4D Clips 自动驾驶场景识别服务向行业开放使用,目前不少标注公司已经展开与毫末智行的合作,比如数据堂、海天瑞声、澳鹏、云测数据、星尘数据,企业间的强强合作必将大幅降低行业使用数据的成本,提高数据质量。

仿真测试
云仿真平台建设是企业工具链能力之一。仿真设备的购置及维护,又构成了一定的成本压力,但在自动驾驶研发过程中,相比先给出部件原型来验证功能,需要较少原型或零原型(Zero Prototype)的虚拟仿真,其成本更为划算,仿真投入几乎是必选项。
仿真有几种形式,包括MiL(模型在环)、SiL(软件在环)、HiL(硬件在环)、DiL(驾员在环)、ViL(整车在环), 不同的企业根据需求,在各自的研发周期的不同阶段,对仿真形式的需求也不尽相同。目前众多车企在利用仿真工具,进行各类功能验证,加快新车型的研发周期及上市时间,比如VI-grade的产品就被BBA、福特、本田、丰田、上汽、一汽、广汽、蔚来等车企所采用。
02、数据闭环生态构建中,企业加速打造“数智/数据底座”能力
数据、算法、算力是自动驾驶技术的三大基石,数据的数量和质量决定着算法能力的上限,而算力又是数据处理的载体。软件和硬件的一体化意味着算法和域控/芯片适配的“顺畅性”。目前行业内,少数企业如Tesla已构建了“数据+算法+算力”的完整智能生态体系,实现了数据的100%掌控。为实现对数据的控制力,主机厂及软件算法企业均在追赶。
智算中心建设
超算中心初期投入较高,主机厂及Tier1对搭建AI计算中心的预算普遍超过亿元。例如特斯拉超级计算机平台Dojo将于2023年7月投入生产;2024年特斯拉在Dojo上的投入将超过10亿美元,以推进超级计算机与神经网络训练。
尽管如此,在自动驾驶领域具有长期规划的车企或技术供应商,都在搭建自己的超算中心,以掌握稳定的算力资源,缩短开发周期,加快自动驾驶产品的上市。例如,2022 年 8 月小鹏汽车成立自动驾驶 AI 智算中心“扶摇”,由小鹏和阿里联合出资打造。该中心可将自动驾驶算法的模型训练时间提速 170 倍,且未来还具备10~100 倍的算力提升空间。
自动驾驶厂商超算中心建设情况

来源:佐思汽研《2023年自动驾驶数据闭环研究报告》
“数智/数据底座”能力建设
智能汽车的全生命周期需要数据来驱动,而基于数据打造的车云全链路能力底座正是一些自动驾驶方案商努力做的事。比如,智协慧同ExceedData车云一体计算架构结合其车载高性能时序数据库,构建了智能汽车的数据底座,重新定义了汽车数据智能的成本与效率,成本总计可下降85%。该数据底座方案获得包括一汽、上汽、上汽零束、华人运通、东风岚图、北汽、吉利等一线车企的高度认可,量产定点了10个以上车型。
智协慧同全栈产品
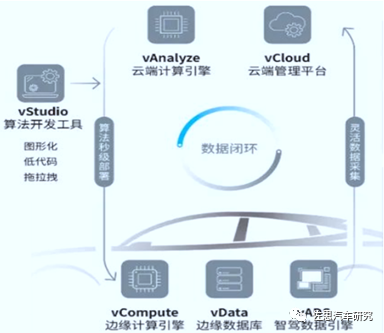
来源:智协慧同
福瑞泰克具备软硬一体平台化开发和量产交付能力,已打通了“规模数据获取-数据处理体系-自动化迭代”的数据闭环链路,其ODIN智能驾驶数智底座支持量产的大规模数据闭环系统,既包括福瑞泰克大规模量产数据基础,也有部署于国家超算中心算力平台,并全面形成了支持算法演进的完整数据闭环体系,可同步完成感知算法的迭代演进与规控算法的闭环验证。ODIN数智底座包括自研域控制器、传感器、自动驾驶算法以及数据闭环系统作为四大支柱体系,目前合作车企品牌已超过40家,合作车型项目超过100款。
03、BEV+Transformer赋能端到端感知决策一体化
自动驾驶能力的增强是更多数据+更好算法+更高算力联合优化的结果,更是感知、决策、规控技术进步的必然。
面对各种复杂的场景,尤其是Corner Case对自动驾驶的感知和决策能力提出了更高的要求。BEV技术通过提供全局视角来增强自动驾驶系统的感知能力。Transformer 模型可以用于提取多模态数据中的特征,如激光雷达点云、图像、雷达数据等。通过对这些数据进行端到端的训练,Transformer 能够自动学习到这些数据的内在结构和相互关系,从而有效识别和定位环境中的障碍物。
BEV+Transformer,可以构建一个端到端的自动驾驶系统,实现高精度的感知、预测和决策。比如商汤基于多模态大模型,可做到数据的感知闭环和决策闭环。商汤感知决策一体化的端到端自动驾驶解决方案UniAD,使车道线的预测准确率提升了30%,预测运动位移的误差降低了近40%,规划误差降低了近30%。在 AI 决策方面,商汤联合上海人工智能实验室推出了OpenDILab决策AI平台。决策 AI 平台也可以用到自动驾驶当中,去实现规划和控制。
商汤绝影感知决策一体化

来源:商汤绝影
此外, 觉非科技也具备“感知-决策-数据”闭环能力,其核心竞争壁垒在于算法和数据之间的联动和飞轮效应。软件层面上,觉非的核心技术路径是融合计算能力,将自车位置与姿态相关的空间数据、重地图或轻地图的静态数据以及感知类传感器数据进行实时融合与实时运算,并应用于自动驾驶的感知系统、定位系统、路径规划系统或记忆建图系统。
觉非科技基于BEV的数据闭环融合智驾解决方案

来源:觉非科技
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。