英特尔的Emerald Rapids Xeon SP处理器在性能上略有提升,成本

随着每一代Intel Xeon SP处理器的推出,我们不禁想到同样的事情:如果这款一年前或两年前就发布了,对于Intel和客户来说都会更好,而且肯定是计划中的。
今天发布的新型“Emerald Rapids”处理器是Xeon SP系列的第五代,确实是Intel迄今为止推出的最优秀的CPU,但它将面临来自AMD的Epyc系列以及一些由超大规模计算和云服务提供商制造的本土ArmCPU的激烈竞争。更不用说Arm服务器CPU新秀Ampere Computing。
过去几年一直如此,Intel将在Emerald Rapids上赢得供应份额,但这将发生在一个除了在人工智能系统上的热衷支出之外,服务器市场已经衰退了两三个季度的市场中,这是个不好的时机。但这不仅仅对Intel来说是不好的时机,正如《可汗的愤怒》中的斯波克先生所说的那样,这也是“给鹅的调味品”,因为机会是平等的。AMD同样遭受着服务器CPU衰退的打击,所有下游服务器制造商也都在经历这一点,再次提醒一下,除了人工智能服务器上的大型GPU引擎,其他地方似乎没有给它们带来太多利润。但如果你仔细看,这使得Nvidia成为地球上商业史上最富有的公司之一。
不同之处在于,AMD在上周推出的“Antares” MI300系列中拥有可信的GPU加速器故事,而Intel对其“Ponte Vecchio” Max Series GPU并未透露太多信息,而是依靠其当前的Gaudi2和未来的Gaudi3人工智能加速器,这些加速器不是通用计算引擎,无法与Nvidia GPU和AMD GPU进行同等对抗。没有传统的高性能计算故事,没有VDI故事(人们似乎并不太关心),没有可视化故事,也没有数据库或分析加速故事,与Gaudi设备相关的故事。
因此,Intel等待在一个称为Intel 7的10纳米工艺的超精细变种上,对“Raptor Cove”核心和Emerald Rapids在今年1月发布的第四代Xeon SP“Sapphire Rapids”共享的“Eagle Stream”服务器平台进行了一些非常出色的工程设计。最终,随着Intel的晶圆厂缩小与台湾积体电路制造公司的工艺和封装差距,将会有更多的调味品为这只鹅提供。最终——因为在半导体业务中总会有一个最终——Intel在核心、工艺和封装方面将与AMD和Nvidia在CPU和GPU领域达到平衡,我们将再次看到计算成本急剧下降。
我们期待着为您而做的这一切。
与此同时,不再拖延,让我们谈谈Emerald Rapids系列,并在进行时牢记这个想法。当公司延长他们在领域中保留服务器的时间时,几乎必然要求他们购买尽可能高性能的机器,以便在向其机群添加一些新设备时,能够淘汰最多数量的老系统足迹。这样,高端CPU能够提供的核心、缓存和I/O,以及中端部分无法提供的东西,将使新设备在领域中的寿命更长。在过去的日子里,购买中端零件是一种常见的策略,但在这种情况下,这并不一定是一个好的做法。
对于Sapphire Rapids,Intel为其高端Extreme Core Count(XCC)变种组成了一个四组成的插座,该变种为HPC客户提供了HBM内存选项。这四个芯片组中,每个芯片组有16个核心,总共有64个核心,仅有60个核心用于良品率。还有一个Medium Core Count(MCC)的单片芯片变种,最多可扩展到32个核心,用于构建Sapphire Rapids SKU堆栈的52芯片中的下半部分。

通过超精细的10纳米工艺,Intel可以制造更大的芯片组,对于相同尺寸的芯片组获得更高的产量,并且对于更小的芯片组获得更好的产量,因此它选择使用三种不同的芯片封装创建Emerald Rapids,正如您在上文中所见。
在最高端,有两个芯片组,每个芯片组似乎有34或35个核心,排列成7×5个核心的网格(一个可能被弹出以腾出内存控制器空间),总共有60或70个核心,其中最多64个核心用于良品率。这是XCC变种,而这一次,对于HPC用户,没有HBM选项。抱歉。
Emerald Rapids的MCC芯片组对外暴露了最多32个核心,并且设计中可能有36个核心,同样是为了提高产量。还有一种能效低的Low Core Count(EE LCC)变种,最多向插座引脚暴露20个核心,并且设计中可能实际有24个核心。
我们已经提出了但目前还不知道这三种变种的晶体管数。
Eagle Stream平台的LGA-4677服务器插座在Sapphire Rapids一代中未被大量使用,但是通过顶级零件,Emerald Rapids填充得相当好:

核心数量有了适度的增加,从Sapphire Rapids芯片的最高配置的60个核心到Emerald Rapids的最高配置的64个核心,但是与Sapphire Rapids的XCC变种相比,Emerald Rapids的XCC变种芯片上的L3缓存最多可达320 MB,而Sapphire Rapids的XCC变种芯片的L3缓存最大只有112.5 MB。
Emerald Rapids插座上的UltraPath Interconnect(UPI)NUMA链接的速度提高到20 GT/秒,比Sapphire Rapids芯片上的UPI链接的16 GT/秒速度提高了25%。与Cascade Lake一样,Emerald Rapids仅设计用于具有一个或两个插槽的机器。因此,如果您需要一个四插槽或八插槽的服务器,您必须使用Sapphire Rapids,直到明年推出我们在九月份详细介绍的第六代“Granite Rapids” Xeon SP。如果您可以等待Granite Rapids用于大型NUMA服务器,那将是更好的选择。
Emerald Rapids芯片还支持CXL 1.1一致性内存协议,允许芯片上的PCI-Express端口支持Type 3 CXL内存,作为内置DDR5主内存的扩展。
至于Raptor Cove核心中每个核心的指令改进,Intel表示,从Sapphire Rapids到Emerald Rapids在High Performance Linpack、STREAM Triad、SPECrate2017_fp_base和SPECrate2017_int_base上的平均性能提升是1.21倍。这不是精确的每个核心时钟标准化的度量。进行1.21倍性能跃升测试的是一对64核Emerald Rapids Xeon SP-8592+芯片,可能以全部核心Turbo速度的2.9 GHz运行,以及一对56核的Sapphire Rapids Xeon SP-8480+芯片。如果将这两个处理器复杂的核心和时钟相乘,仅这两个因素就给您提供了10%的提升,也许更快的UPI 2.0链接也有些帮助。但假设它们没有。那么,实际的IPC增益,在时钟和核心数量相同的情况下标准化,可能更接近11%。这显然只是一个猜测。
因此,不再拖延,以下是32款新的Emerald Rapids Xeon SP处理器:
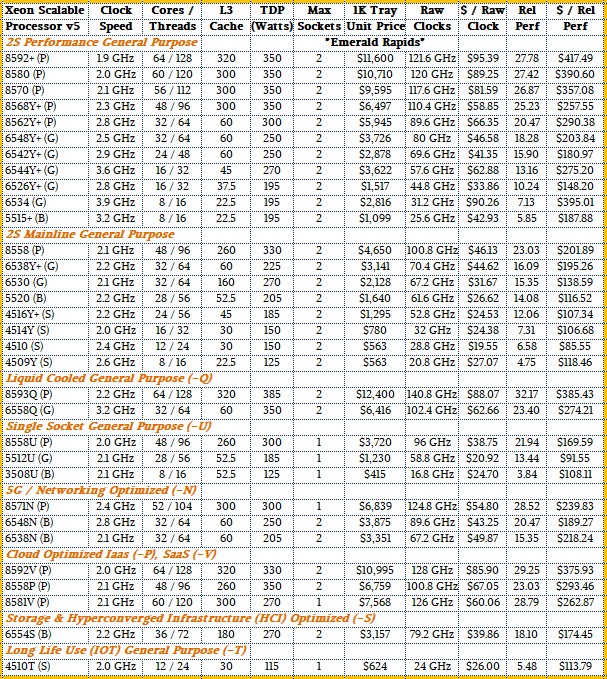
在SKU堆栈的多样性方面,Emerald Rapids系列有32个官方变种,比Sapphire Rapids系列的52个变种要窄且深得多。第一代的“Skylake” Xeon SP有51个变种,第二代的“Cascade Lake” Xeon SP有45个变种,再加上18个“Cascade Lake R”深度变种和为四插槽和八插槽服务器调整的“Cooper Lake”,这在某种程度上为Cascade Lake的63个正常变种增加了另外11个变种,总共达到74个变种。即使是命途多舛且长时间推迟的第三代“Ice Lake” Xeon SP也有38个变种。
总体而言,Emerald Rapids芯片在各种数据中心工作负载上提供了从1.13X到1.69X的性能提升,并提供了每瓦特平均1.34X更好的性能。在空闲功耗方面,热特性尤为出色,空闲时的功耗约为100瓦特。(我们想说的是:服务器芯片为什么会空闲?给它找点事做吧。)
其中一些性能提升不仅仅来自核心,还来自更高的内存带宽,因为Emerald Rapids CPU支持5.6 GHz的DDR5内存,而Sapphire Rapids使用的是4.8 GHz的DDR5内存,带来了16.7%的内存带宽增加。两款芯片均有八个内存通道,因此通过向计算复杂添加更多内存通道并没有增加带宽,但是它们支持CXL内存扩展,通常称为Type 3 CXL内存,提供了另外四个通道的CXL内存和额外的带宽。您可以以两种方式使用CXL内存:
 目前尚不清楚Intel在测试Emerald Rapids系统时是否以及如何使用CXL内存来提升基准性能。我们将尽力澄清这一点。我们还将进行我们通常的体系结构深度剖析、与先前的Xeon和Xeon SP代系列的性价比比较以及与AMD Epyc和Arm服务器CPU的竞争分析。
目前尚不清楚Intel在测试Emerald Rapids系统时是否以及如何使用CXL内存来提升基准性能。我们将尽力澄清这一点。我们还将进行我们通常的体系结构深度剖析、与先前的Xeon和Xeon SP代系列的性价比比较以及与AMD Epyc和Arm服务器CPU的竞争分析。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。